UNIF: 自然语言处理联合框架
Github 地址:https://github.com/geyingli/unif

有数据,想要快速实现你的想法?轻便、易使用的自然语言处理联合框架,帮你快速搭建各类常用深度学习模型 (Transformer, GPT-2, BERT, ALBERT, UniLM, XLNet, ELECTRA),同时对于 BERT 系列,支持高效用的蒸馏 (TinyBERT, FastBERT)。支持各类上下游任务 (语言模型、文本分类、文本生成、命名实体识别、机器阅读理解、机器翻译、序列标注等)。
特性
- API 简单:三行代码完成训练及推理,并一键设置多 GPU 并行
- 品类丰富:支持 40+ 种模型类
- 唯一依赖:Tensorflow 1.x/2.x
- 高分保证:提供分层学习率、对抗式训练等多项训练技巧
- 高扩展性:代码高度抽象、易扩展,能够高效支持更多 SOTA 算法
- 可供部署:导出 SavedModel,供部署使用
安装
git clone https://github.com/geyingli/unif
cd unif
python3 setup.py install --user
快速上手
import uf
# 载入模型(使用 demo 配置文件进行示范)
model = uf.BERTClassifier(config_file='demo/bert_config.json', vocab_file='demo/vocab.txt')
# 定义训练样本
X, y = ['久旱逢甘露', '他乡遇故知'], [1, 0]
# 训练
model.fit(X, y)
# 推理
print(model.predict(X))
模型列表
| 领域 | API | 简介 |
|---|---|---|
| 语言模型 | BERTLM |
结合 MLM 和 NSP 任务,随机采样自下文及其他文档 |
RoBERTaLM |
仅 MLM 任务,采样至文档结束 | |
ALBERTLM |
结合 MLM 和 SOP,随机采样自上下文及其他文档 | |
ELECTRALM |
结合 MLM 和 RTD,生成器与判别器联合训练 | |
VAELM |
可生成语言文本负样本,也可提取向量用于聚类 | |
GPT2LM |
自回归式文本生成 | |
UniLM |
结合双向、单向及 Seq2Seq 建模的全能语言模型 | |
| 命名实体识别 | BERTNER |
- |
BERTCRFNER |
结合 CRF | |
BERTCRFCascadeNER |
识别与分类同时进行的级联架构 | |
| 机器翻译 | TransformerMT |
共享词表,标准 Seq2Seq 架构 |
| 机器阅读理解 | BERTMRC |
- |
RoBERTaMRC |
- | |
ALBERTMRC |
- | |
ELECTRAMRC |
- | |
SANetMRC |
引入 Sentence Attention | |
BERTVerifierMRC |
抽取 answer span 的同时判断可答性 | |
RetroReaderMRC |
抽取 answer span 的同时判断可答性 | |
| 单 Label 分类 | TextCNNClassifier |
小而快 |
BERTClassifier |
- | |
XLNetClassifier |
- | |
RoBERTaClassifier |
- | |
ALBERTClassifier |
- | |
ELECTRAClassifier |
- | |
WideAndDeepClassifier |
通过 Wide & Deep 架构融合句子级别特征 | |
SemBERTClassifier |
通过 SemBERT 架构融合字级别的特征 | |
PerformerClassifier |
引入 FAVOR+ 加速推理 | |
UDAClassifier |
结合一致性学习的半监督学习算法 | |
| 多 Label 分类 | BERTBinaryClassifier |
- |
XLNetBinaryClassifier |
- | |
RoBERTaBinaryClassifier |
- | |
ALBERTBinaryClassifier |
- | |
ELECTRABinaryClassifier |
- | |
| 序列标注 | BERTSeqClassifier |
- |
XLNetSeqClassifier |
- | |
RoBERTaSeqClassifier |
- | |
ALBERTSeqClassifier |
- | |
ELECTRASeqClassifier |
- | |
| 模型蒸馏 | TinyBERTClassifier |
大幅压缩模型参数,提速十倍以上 |
FastBERTClassifier |
动态推理,易分样本提前离开模型 |
文档目前还不完善,善用 help(XXX) 能帮你获得更多 API 的使用细节。
建模
一步创建新模型:
model = uf.BERTClassifier(
config_file, vocab_file,
max_seq_length=128,
label_size=2,
init_checkpoint=None, # 预训练参数路径
output_dir='./output',
gpu_ids='0,1,3,5',
drop_pooler=False, # 建模时跳过 pooler 层
do_lower_case=True,
truncate_method='LIFO') # longer-FO/LIFO/FIFO
下载知名公开预训练参数:
# 查看可下载列表
uf.list_resources()
# ┌──────────────────────────┬──────────┬──────────────┬───────────────────────────────────────────┬───────────────────────────────────────────────────────────────────────────────────┐
# ┊ Key ┊ Backbone ┊ Organization ┊ Site ┊ URL ┊
# ├──────────────────────────┼──────────┼──────────────┼───────────────────────────────────────────┼───────────────────────────────────────────────────────────────────────────────────┤
# ┊ bert-base-zh ┊ BERT ┊ Google ┊ https://github.com/google-research/bert ┊ https://storage.googleapis.com/bert_models/2018_11_03/chinese_L-12_H-768_A-12.zip ┊
# ┊ albert-tiny-zh ┊ ALBERT ┊ Google ┊ https://github.com/google-research/albert ┊ https://storage.googleapis.com/albert_zh/albert_tiny_zh_google.zip ┊
# ┊ albert-small-zh ┊ ALBERT ┊ Google ┊ https://github.com/google-research/albert ┊ https://storage.googleapis.com/albert_zh/albert_small_zh_google.zip ┊
# ┊ albert-base-zh ┊ ALBERT ┊ Brightmart ┊ https://github.com/brightmart/albert_zh ┊ https://storage.googleapis.com/albert_zh/albert_base_zh_additional_36k_steps.zip ┊
# ┊ albert-large-zh ┊ ALBERT ┊ Brightmart ┊ https://github.com/brightmart/albert_zh ┊ https://storage.googleapis.com/albert_zh/albert_large_zh.zip ┊
# ┊ albert-xlarge-zh ┊ ALBERT ┊ Brightmart ┊ https://github.com/brightmart/albert_zh ┊ https://storage.googleapis.com/albert_zh/albert_xlarge_zh_183k.zip ┊
# ┊ bert-wwm-ext-base-zh ┊ BERT ┊ HFL ┊ https://github.com/ymcui/Chinese-BERT-wwm ┊ https://drive.google.com/uc?export=download&id=1buMLEjdtrXE2c4G1rpsNGWEx7lUQ0RHi ┊
# ┊ roberta-wwm-ext-base-zh ┊ BERT ┊ HFL ┊ https://github.com/ymcui/Chinese-BERT-wwm ┊ https://drive.google.com/uc?export=download&id=1jMAKIJmPn7kADgD3yQZhpsqM-IRM1qZt ┊
# ┊ roberta-wwm-ext-large-zh ┊ BERT ┊ HFL ┊ https://github.com/ymcui/Chinese-BERT-wwm ┊ https://drive.google.com/uc?export=download&id=1dtad0FFzG11CBsawu8hvwwzU2R0FDI94 ┊
# ┊ xlnet-mid-zh ┊ XLNet ┊ HFL ┊ https://github.com/ymcui/Chinese-XLNet ┊ https://drive.google.com/uc?export=download&id=1342uBc7ZmQwV6Hm6eUIN_OnBSz1LcvfA ┊
# ┊ xlnet-base-zh ┊ XLNet ┊ HFL ┊ https://github.com/ymcui/Chinese-XLNet ┊ https://drive.google.com/uc?export=download&id=1m9t-a4gKimbkP5rqGXXsEAEPhJSZ8tvx ┊
# ┊ electra-180g-small-zh ┊ ELECTRA ┊ HFL ┊ https://github.com/ymcui/Chinese-ELECTRA ┊ https://drive.google.com/uc?export=download&id=177EVNTQpH2BRW-35-0LNLjV86MuDnEmu ┊
# ┊ electra-180g-small-ex-zh ┊ ELECTRA ┊ HFL ┊ https://github.com/ymcui/Chinese-ELECTRA ┊ https://drive.google.com/uc?export=download&id=1NYJTKH1dWzrIBi86VSUK-Ml9Dsso_kuf ┊
# ┊ electra-180g-base-zh ┊ ELECTRA ┊ HFL ┊ https://github.com/ymcui/Chinese-ELECTRA ┊ https://drive.google.com/uc?export=download&id=1RlmfBgyEwKVBFagafYvJgyCGuj7cTHfh ┊
# ┊ electra-180g-large-zh ┊ ELECTRA ┊ HFL ┊ https://github.com/ymcui/Chinese-ELECTRA ┊ https://drive.google.com/uc?export=download&id=1P9yAuW0-HR7WvZ2r2weTnx3slo6f5u9q ┊
# └──────────────────────────┴──────────┴──────────────┴───────────────────────────────────────────┴───────────────────────────────────────────────────────────────────────────────────┘
# 下载预训练模型包
uf.download('bert-wwm-ext-base-zh')
任务后期需要大量的训练,可以通过配置文件,方便地整理和读取模型:
# 写入配置文件
assert model.output_dir is not None # 为空的话模型就白训了
model.cache('key', cache_file='.cache')
# 从配置文件读取
model = uf.load('key', cache_file='.cache')
程序还没执行结束,内存就不够用了?试试删除模型 del model 或重置 model.reset()。
训练/推理/评分
# 训练
model.fit(
X=None, y=None, sample_weight=None,
X_tokenized=None, # 特定场景下使用,e.g. 使用你自己的分词工具
batch_size=32,
learning_rate=5e-05,
target_steps=None, # 放空代表直接训练到 `total_steps`,不中途停止;否则为本次训练暂停点
total_steps=-3, # -3 代表自动计算数据量并循环三轮
warmup_ratio=0.1,
print_per_secs=1, # 多少秒打印一次信息
save_per_steps=1000,
**kwargs) # 其他参数,下文介绍
# 推理
model.predict(
X=None, X_tokenized=None, batch_size=8)
# 评分
model.score(
X=None, y=None, sample_weight=None, X_tokenized=None,
batch_size=8)
# 常规训练流程示范
assert model.output_dir is not None # 非空才能保存模型参数
for loop_id in range(10): # 假设训练途中一共验证 10 次
model.fit(X, y, target_steps=((loop_id + 1) * -0.6), total_steps=-6) # 假设一共训练 6 轮
model.cache('dev-%d' % loop_id) # 保存一次模型
print(model.score(X_dev, y_dev)) # 查看模型表现
复用训练数据?可以尝试先存为 TFRecords,训练时读取:
# 缓存数据
model.to_tfrecords(
X=None, y=None, sample_weight=None, X_tokenized=None,
tfrecords_file='./train.tfrecords') # 一次只能存一个文件
# 边读边训
model.fit_from_tfrecords(
tfrecords_files=['./train.tfrecords-0', './.tfrecords-1'], # 同时从两个 TFRecords 文件读取
n_jobs=3, # 启动三个线程
batch_size=32, # 以下参数和 `.fit()` 中参数相同
learning_rate=5e-05,
target_steps=None,
total_steps=-3,
warmup_ratio=0.1,
print_per_secs=1,
save_per_steps=1000,
**kwargs)
训练所用的条件参数 kwargs:
# 优化器
model.fit(X, y, ..., optimizer='gd')
model.fit(X, y, ..., optimizer='adam')
model.fit(X, y, ..., optimizer='adamw') # 默认
model.fit(X, y, ..., optimizer='lamb')
# 分层学习率 (少量模型不适用)
model.fit(X, y, ..., layerwise_lr_decay_ratio=0.85) # 默认为 None
print(model._key_to_depths) # 衰减比率
# 对抗式训练
model.fit(X, y, ..., adversarial='fgm', epsilon=0.5) # FGM
model.fit(X, y, ..., adversarial='pgd', epsilon=0.05, n_loop=2) # PGD
model.fit(X, y, ..., adversarial='freelb', epsilon=0.3, n_loop=3) # FreeLB
model.fit(X, y, ..., adversarial='freeat', epsilon=0.001, n_loop=3) # FreeAT
model.fit(X, y, ..., adversarial='smart', epsilon=0.01, n_loop=2, prtb_lambda=0.5, breg_miu=0.2, tilda_beta=0.3) # SMART (仅 Classifier 可用)
# 置信度过滤 (仅 Classifier 可用)
model.fit(X, y, ..., conf_thresh=0.99) # 默认为 None
迁移学习
存在变量命名不同而无法加载,可通过以下步骤解决:
# 查看从 `init_checkpoint` 初始化失败的变量
assert model.init_checkpoint is not None
model.init()
print(model.uninited_vars)
# 在 `checkpoint` 中寻找对应的参数名
print(uf.list_variables(model.init_checkpoint))
# 人工添加映射关系到 `assignment_map`
model.assignment_map['var_1_in_ckpt'] = model.uninited_vars['var_1_in_model']
model.assignment_map['var_2_in_ckpt'] = model.uninited_vars['var_2_in_model']
# 重新读取预训练参数
model.reinit_from_checkpoint()
# 看看变量是否从初始化失败的名单中消失
print(model.uninited_vars)
# 保存参数及配置(避免下次载入预训练参数时,重复上述步骤)
assert model.output_dir is not None
model.cache('key')
直接给参数赋值如何?当然是可以的:
import numpy as np
# 获取参数
variable = model.trainable_variables[0]
# 赋值
model.assign(variable, value)
# 查看参数
print(model.sess.run(variable))
# 保存赋值后的参数及配置
assert model.output_dir is not None
model.cache('key')
TFServing
# 导出 PB 文件到 `output_dir` 下
assert model.output_dir is not None
model.export(
export_dir, # 导出目录
rename_inputs=None, # 重命名输入
rename_outputs=None, # 重命名输出
ignore_outputs=None) # 裁剪多余输出
FAQ
-
问:如何实现多个 segment 的输入?
答:使用 list 组合多个 segment 的输入,如
X = [['文档1句子1', '文档1句子2', '文档1句子3'], ['文档2句子1', '文档2句子2']],模型会自动按顺序拼接并添加分隔符。 -
问:如何查看切词结果?
答:通过
model.tokenizer.tokenize(text)可查看切词结果。另外也可通过model.convert(X)查看切词与 ID 转换后的矩阵。 -
问:如何使用自己的切词工具?
答:在训练和推理时预先将传入参数
X改为X_tokenized,模型将直接跳过原有的的分词步骤。需要注意的是,分词结果同样需要基于list承载,例如原先由x承载的['黎明与夕阳'],由X_tokenized承载后需呈现['黎', '##明', '与', '夕', '##阳']的形式。 -
问:如何实现 TinyBERT 和 FastBERT 复蒸馏?
答:
TinyBERTClassifier训练完成后使用.to_bert()将变量重命名保存,而后使用FastBERTClassifier常规读取生成的 checkpoint 和配置文件即可。
开发需知
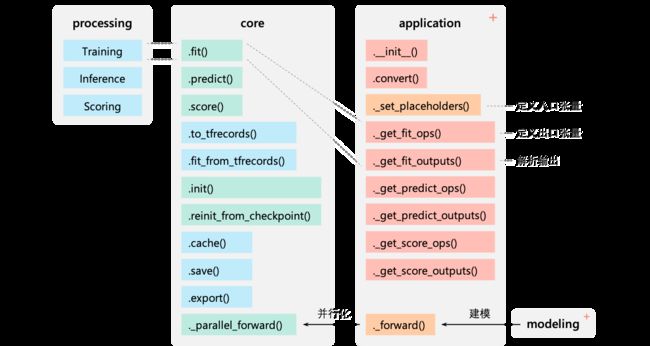
我们欢迎一切有效的 pull request,加入我们,成为 contributors 一员。 核心的代码架构如下图所示,新的模型开发仅需要在 application 下添加新的类,这些类可以由现有算法库 modeling 中的算子组合而来,也可以自行编写。
尾声
框架目前主要为我个人及团队所用,靠兴趣推动至今。如果能受到更多人,包括您的认可,我们会愿意投入更多精力进行丰富与完善,早日推出第一个正式版本。如果您喜欢,请点个 star 作为支持。如果有希望实现的 SOTA 算法,留下 issue,我们会酌情考虑,并安排时间为你编写。通常三日以内可以实现。任何需求和建议都不尽欢迎。最后,感谢你读到这里。