python机器学习之特征选择(过滤法、嵌入法、包装法案例详解)
特征选择
特征工程:
1、特征提取 :从文字,图像等数据中提取信息作为特征
2、特征创造 :把现有特征进行组合,或仙湖计算,得到新的特征
3、特征选择 :从所有的特征种,选择出有意义的,对模型有帮助的特征,避免所有特征都导图模型取训练的情况。在特征选择之前,跟数据提供者开会。
下面案例所用到的数据获取地址——>这里下载
1.过滤法
首先导入数据
import pandas as pd
data = pd.read_csv("../数据/digit recognizor.csv")
data.head()
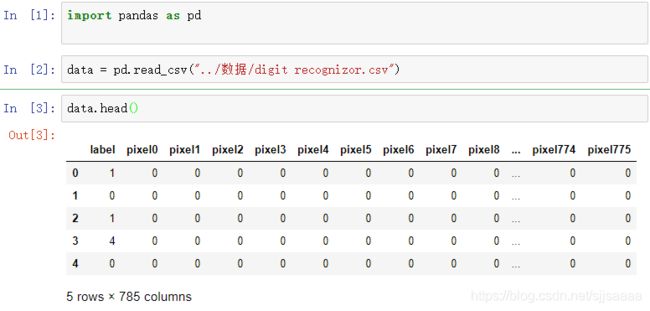
这个数据亮较大,如果使用支持向量机和神经网络,可能会直接跑不出来,使用KNN跑一次大概需要半个小时,用这个数据更能体现特征工程的重要性。
过滤法:
全部特征—> 最佳特征子集->算法->模型评估
方差过滤
无论接下来的特征工程要做什么,都要优先消除方差为0的特征。
from sklearn.feature_selection import VarianceThreshold
selector = VarianceThreshold()#实例化,默认方差为0
x_var0 = selector.fit_transform(x)
x_var0.shape#查看数据维度
pd.DataFrame(x_var0).head()#查看数据前五行

删除了方差为0的特征,但是还剩下708个特征,明显还需要进一步选择,可以设置方差阈值
import numpy as np
x_fsvar =VarianceThreshold(np.median(x.var().values)).fit_transform(x)
#将中位数设置为阈值,砍掉一般的特征
x.var().values
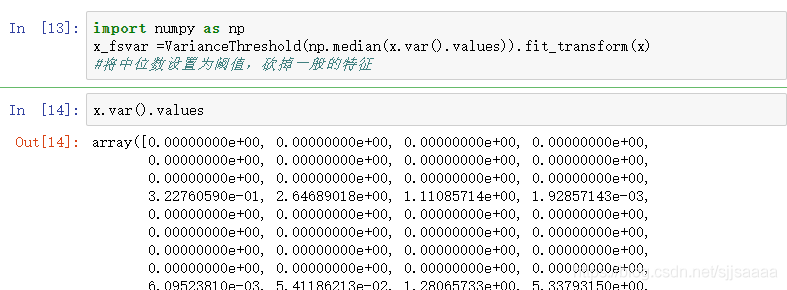
np.median(x.var().values)#中位数
x_fsvar.shape#利用中位数过滤后的维度

当特征时二分类时,特征的取值就是伯努利随机变量。
若特征时伯努利随机变量,假设p=0.8,即二分类特征种某种分类占到80%以上的时候删除特征
x_bvar = VarianceThreshold(0.8*(1-0.8)).fit_transform(x)
x_bvar.shape

差过滤对模块的影响
KNN VS 随机森林在不同方差过滤效果下的对比
导入库
from sklearn.ensemble import RandomForestClassifier as RFC
from sklearn.neighbors import KNeighborsClassifier as KNN
from sklearn.model_selection import cross_val_score
import numpy as np
提取数据
x = data.iloc[:,1:]
y = data.iloc[:,0]
使用中位数过滤特征
x_fsvar = VarianceThreshold(np.median(x.var().values)).fit_transform(x)
**KNN 方差过滤前 **
35分钟才能运行完
cross_val_score(KNN(),x,y,cv=5).mean()

4小时才能运行完
%%timeit 可以用来计算运行这个cell种代码所需的时间,一般是运行7次取平均值
cross_val_score(KNN(),x,y,cv=5).mean()

方差过滤后
20分钟
cross_val_score(KNN(),x_fsvar,y,cv=5).mean()

%%timeit
cross_val_score(KNN(),x_fsvar,y,cv=5).mean()

可以看出,对于KNN,过滤后的效果十分明显:准确率稍微有提升
但是平均运行时间减少了10分钟,算法效率上升了1/3
随机森林: 方差过滤前
cross_val_score(RFC(n_estimators=10,random_state=0),x,y,cv=5).mean()

%%timeit
cross_val_score(RFC(n_estimators=10,random_state=0),x,y,cv=5).mean()

方差过滤后
cross_val_score(RFC(n_estimators=10,random_state=0),x_fsvar,y,cv=5).mean()

%%timeit
cross_val_score(RFC(n_estimators=10,random_state=0),x_fsvar,y,cv=5).mean()

可以观察到,随机森林的准确率略逊于KNN,但运行时间连KNN的1%都不到,只需要十几秒,方差过滤后,随机森林的准确率也微弱上升,但是运行时间却几乎没有什么变化,依然是10秒左右。
所以过滤法:
主要对象是:需要遍历或升维的算法们
主要目的是:在维持算法表现的前提下,帮助算法们降低计算成本
方差过滤的影响:
阈值很小或被过滤掉的特征比较少:
模型表现:不会有太大影响,
运行时间:可能降低模型的运行时间,基于方差很小的特征有多少,当方差很小的特征不多时,对模型没有太大的影响
阈值比较大:
模型表现:可能变更好,代表被滤掉的特征大部分是噪音,也可能变糟糕,代表被滤掉的特征都是有效特征
运行时间:一定能降低模型的运行时间,算法在便利特征时的计算越复杂,运行时间下降的越多
选取超参数threshold
每个数据集都不一样,只能自己去尝试,在现实中我们会使用阈值为0或阈值很小的方差过滤,来为我们消除一些明显用不到的特征,然后我们会选择更优的特征选择方法继续消减特征数量。
卡方过滤(不能计算负数)
导入库
from sklearn.ensemble import RandomForestClassifier as RFC #随机森林
from sklearn.model_selection import cross_val_score#交叉验证
from sklearn.feature_selection import SelectKBest #选分数最大的个数
from sklearn.feature_selection import chi2#卡方检验
获得特征
x_fschi = SelectKBest(chi2,k = 300).fit_transform(x_fsvar,y) #chi2以来的统计量,k=300为需要前300个特征
x_fschi.shape

查看模型效果
#查看模型效果
cross_val_score(RFC(n_estimators=10,random_state=0),x_fschi,y,cv=10).mean()#交叉验证

模型效果降低了说明删除了与模型有关的且有效的特征
使用学习曲线,获得合适的参数
%matplotlib inline
import matplotlib.pyplot as plt
score = []
for i in range(390,200,-10):
x_fschi = SelectKBest(chi2,k=i).fit_transform(x_fsvar,y)
once = cross_val_score(RFC(n_estimators=10,random_state=0),x_fschi,y,cv=5).mean()
score.append(once)
plt.plot(range(390,200,-10),score)
plt.show()
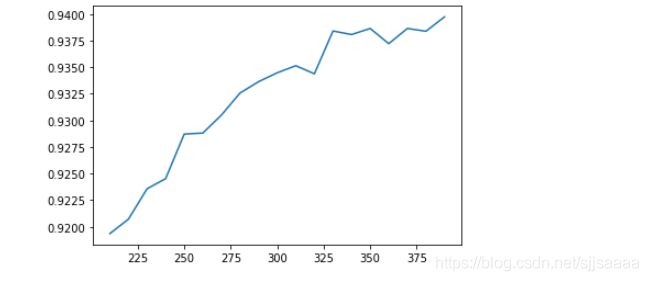
依照学习曲线选取效果好的那个数量值。
获得卡方值和P值
P值的影响

chivalue,pvalues_chi = chi2(x_fsvar,y)
chivalue#卡方值
pvalues_chi#P值

k取多少?我们想要消除所有P值大于设定值。
chivalue.shape[0] - (pvalues_chi > 0.05 ).sum()
可以看到方差验证已经把和标签无关的特征都删除了。

F 检验
from sklearn.feature_selection import f_classif
F, pvalues_f = f_classif(x_fsvar,y)
F.shape
pvalues_f.shape

我们希望选取p值小于0.05或0.01的特征,这些特征与标签显著相关的
K = F.shape[0] - (pvalues_f > 0.05).sum()

查看模型效果
x_fsF = SelectKBest(f_classif,k=300).fit_transform(x_fsvar,y)
cross_val_score(RFC(n_estimators=10,random_state=0),x_fsF,y,cv = 5).mean()

得到的结论和我们用卡方过滤得到的结论一摸一样:没有任何特征的P值大于0.01,所有的特征都是和标签相关的,因此我们不需要相关性过滤
互信息法
用来捕捉每个特征与标签之间的任意关系
from sklearn.feature_selection import mutual_info_classif as MIC
result = MIC(x_fsvar,y)
result

查看小于=0的个数
k = result.shape[0]-sum(result <= 0)
k

查看模型效果
x_fsmic = SelectKBest(MIC,k=300).fit_transform(x_fsvar,y)
cross_val_score(RFC(n_estimators = 10,random_state = 0),x_fsmic,y,cv = 5).mean()

所有特征的互信息量估计都大于0,因此所有特征都与标签相关
2.嵌入法 Embedded
导入库
from sklearn.feature_selection import SelectFromModel
from sklearn.ensemble import RandomForestClassifier as RFC
训练模型
RFC_ = RFC(n_estimators=10,random_state=0)
x_embedded = SelectFromModel(RFC_,threshold=0.005).fit_transform(x,y)
x_embedded.shape
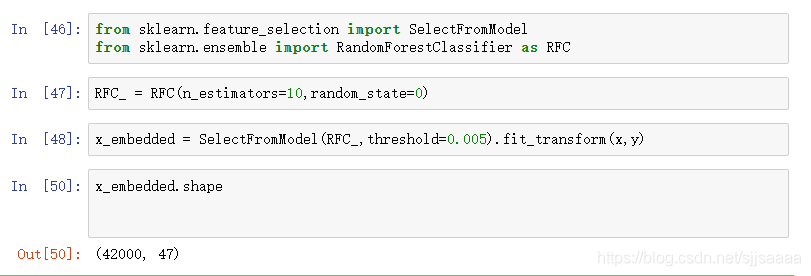
模型的维度明显降低了。
查看最佳阈值,也可以画学习曲线
import numpy as np
import matplotlib.pyplot as plt
RFC_.fit(x,y).feature_importances_ #实例化好的数值
threshold = np.linspace(0,(RFC_.fit(x,y).feature_importances_).max(),20)
score = []
for i in threshold:
x_embedded = SelectFromModel(RFC_,threshold=i).fit_transform(x,y)
once = cross_val_score(RFC_,x_embedded,y,cv = 5).mean()
score.append(once)
plt.plot(threshold,score)
plt.show()

当阈值越来越大,模型的效果越来越低。可以选择前半段作为阈值。
从中挑选一个数值,验证一下模型的效果。
选取其中的值0.00067,查看模型效果
x_embedded = SelectFromModel(RFC_,threshold=0.00067).fit_transform(x,y)
cross_val_score(RFC_,x_embedded,y,cv=5).mean()

由于嵌入法比方差过滤更具体到模型的表现的缘故。
和其他调参一样,选定一个范围,使用细化的学习曲线来找到最佳的值。
进一步画学习曲线,找到更详细的值
score2 = []
for i in np.linspace(0,0.00134,20):
x_embedded = SelectFromModel(RFC_,threshold=i).fit_transform(x,y)
once = cross_val_score(RFC_,x_embedded,y,cv=5).mean()
score2.append(once)
plt.figure(figsize = [20,5])
plt.plot(np.linspace(0,0.00134,20),score2)
plt.xticks(np.linspace(0,0.00134,20))
plt.show()
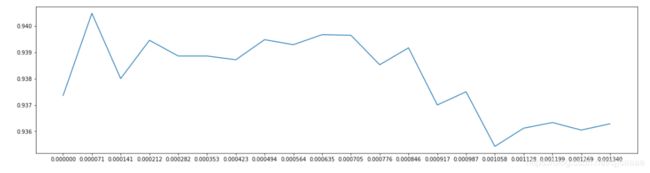
查看模型效果
x_embedded = SelectFromModel(RFC_,threshold=0.000564).fit_transform(x,y)
cross_val_score(RFC_,x_embedded,y,cv=5).mean()

查看使用嵌入法后随机森林的模型效果
cross_val_score(RFC(n_estimators=100,random_state=0),x_embedded,y,cv=5).mean()

可以看到模型的效果达到了0.963,效果明显增加,但是运行的时间过于长。
所以数据量大的时候选择过滤法,因为嵌入法耗时长。
3.包装法
from sklearn.feature_selection import RFE
RFC_ = RFC(n_estimators=10,random_state=0)#实例化模型
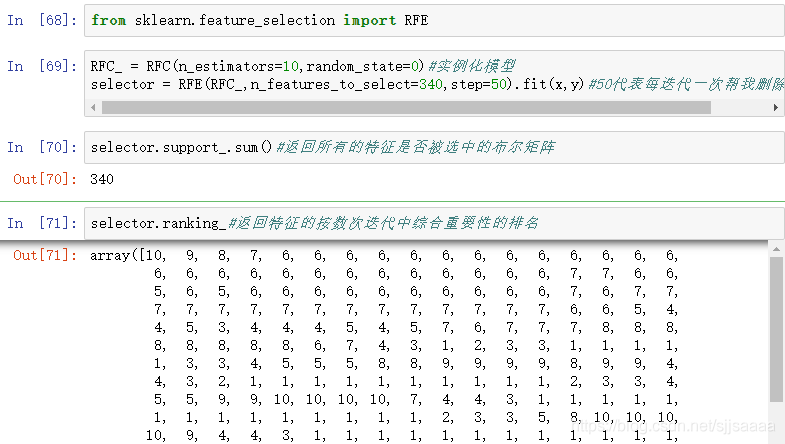
selector = RFE(RFC_,n_features_to_select=340,step=50).fit(x,y)#50代表每迭代一次帮我删除50个特征
selector.support_.sum()#返回所有的特征是否被选中的布尔矩阵
selector.ranking_#返回特征的按数次迭代中综合重要性的排名
得到特征矩阵,算出模型效果
x_wrapper = selector.transform(x)#得到使用包装法的到的特征矩阵
cross_val_score(RFC_,x_wrapper,y,cv=5).mean()

对包装法画学习曲线
大概需要15分钟,很漫长。
score = []
for i in range(1,751,50):
x_wrapper = RFE(RFC_,n_features_to_select=i,step=50).fit_transform(x,y)
once = cross_val_score(RFC_,x_wrapper,y,cv=5).mean()
score.append(once)
plt.figure(figsize = [20,5])
plt.plot(range(1,751,50),score)
plt.xticks(range(1,751,50))
plt.show()

可以看到,应用50个特征时,就达到了90%以上。
小结
过滤法更快速,但更粗糙。
包装法和嵌入法更准确,比较适合具体到算法去调整,但计算量比较大,运行时间长。
当数据量很大的时候,优先考虑使用方差过滤和互信息法调整,再上其他特征选择方法。
使用逻辑回归时,优先使用嵌入法。
使用支持向量机时,优先使用包装法。
迷茫的时候,过滤法。看具体数据具体分析
-------—----–--—----------—-------—-------—----—--—----—------—--------–--—----------------—----–—--—-----
python编码实战
安利一门Python超级好课!
扫码下单输优惠码【csdnfxzs】再减5元,比官网还便宜!
