深度学习基础--卷积类型
本文主要简单介绍几种常见卷积类型,有错误的地方望指正,喜欢就点赞吧。知乎也是本人:https://zhuanlan.zhihu.com/p/59839551
用于回忆和梳理知识,一些原话没有标注引用,望见谅。
1、Upsampling(上采样)
在FCN、U-net等网络结构中,涉及到上采样。上采样概念:任何可以让图像变成更高分辨率的技术。最简单的方式是重采样和插值:将输入图片进行rescale到一个想要的尺寸,而且计算每个点的像素点,使用如双线性插值等插值方法对其余点进行插值来完成上采样过程。

2、上池化
Unpooling是在CNN中常用的来表示max pooling的逆操作。这是论文《Visualizing and Understanding Convolutional Networks》中产生的思想,原理很好理解,就是最大池化的逆运算。下图示意:
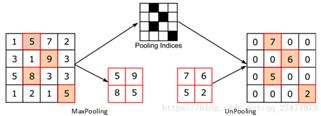
3、反卷积 DeCov
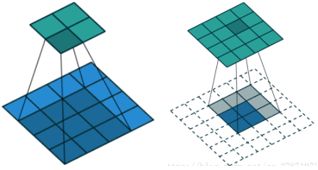
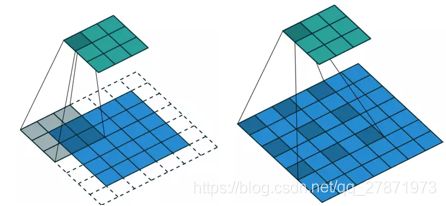
反卷积又被称为Transposed(转置) Convolution,卷积的计算可以转化为权值稀疏矩阵和特征矩阵相乘。3×3卷积核展成一个权值稀疏矩阵,把4×4的输入特征展成[16,1]的矩阵,那么卷积可以输出是一个[4,1]的输出特征矩阵。下图表示卷积计算对应的反卷积操作,其中他们的输入输出关系正好相反。如果不考虑通道以卷积运算的反向运算来计算反卷积运算的话,还可以通过离散卷积的方法来求反卷积。
4、group convolution
Group convolution是分组卷积,最早在AlexNet中出现,由于当时的硬件资源有限,训练AlexNet网络时卷积操作不能全部放在同一个GPU处理,作者把feature maps分给多个GPU进行处理,最后把多个GPU的结果进行融合。
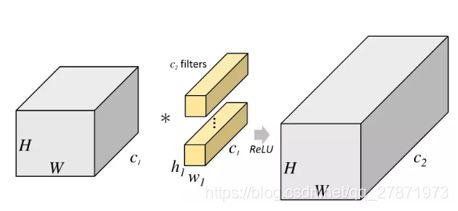
从上图看出,一般的卷积会对输入数据的整体一起做卷积操作,即输入数据:H1×W1×C1;卷积核大小为h1×w1,一共有C2个,然后卷积得到的输出数据是H2×W2×C2。这里假设输入和输出的分辨率是不变的。这个过程是一气呵成的,对当时存储器和计算能力来说要求很苛刻。 但是分组卷积明显没有那么多的参数,对于上面同样的问题,分组卷积操作如下图所示。
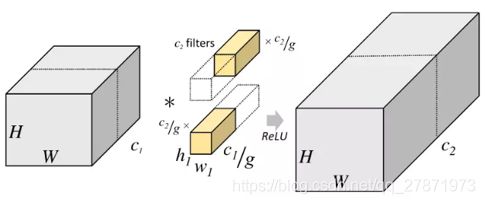
将输入数据分成了2组(组数为g),这种分组只是在深度(通道)上进行划分,即某几个通道编为一组,这个具体的数量由(C1/g)决定。因为输出数据的改变,相应的,卷积核也需要做出同样的改变。即每组中卷积核的深度也就变成了(C1/g),而卷积核的大小是不需要改变的,此时每组的卷积核的个数就变成了(C2/g)个,而不是原来的C2。然后用每组的卷积核同它们对应组内的输入数据卷积,得到了输出数据以后,再用concatenate的方式组合起来,最终的输出数据的通道仍旧是C2。也是说,分组数g决定以后,那么我们将并行的运算g个相同的卷积过程,每个过程里(每组),输入数据为H1×W1×C1/g,卷积核大小为h1×w1×C1/g,一共有C2/g个,输出数据为H2×W2×C2/g。
从一个具体的例子来看,Group conv本身就极大地减少了参数。比如当输入通道为256,输出通道也为256,kernel size为3×3,不做Group conv参数为256×3×3×256。实施分组卷积时,若group为8,每个group的input channel和output channel均为32,参数为8×32×3×3×32,是原来的八分之一。而Group conv最后每一组输出的feature maps应该是以concatenate的方式组合。
复习一下concatenate(cafe中叫cat操作)和add操作的区别:前者在通道维度上相加,后者是直接在feature map尺度上相加(对,Resnet网络的跳跃连接是add操作,DenseNet是concatenate操作。)
Alex认为group conv的方式能够增加filter之间的对角相关性,而且能够减少训练参数,不容易过拟合,这类似于正则的效果。
5、dilated convolution
Dilated/Atrous Convolution(空洞卷积或者膨胀卷积) 图像分割领域一个比较重要的技术,是在标准的 convolution map 里注入空洞,以此来增加 reception field。
在使用深层的CNN网络中做一些其他任务时,比如图像分割,有一些致命性的缺陷。主要问题:
- Up-sampling / pooling layer is 确定的 (参数不可学习)。
- 内部数据结构丢失,空间层级化信息丢失。
- 小物体信息无法重建 (假设有四个pooling layer 则 任何小于 2^4 = 16 pixel 的物体信息将理论上无法重建)。
在图像分割领域,图像输入到FCN中,FCN像传统的CNN那样对图像做卷积再pooling,降低图像尺寸的同时增大感受野,但是由于图像分割预测是pixel-wise的输出,所以要将pooling后较小的图像尺寸upsampling到原始的图像尺寸进行预测(上采样一般采用本文1和3方法),pooling操作使得每个像素预测接收到的感受野信息。因此图像分割FCN中有两个关键,一个是pooling减小图像尺寸增大感受野,另一个是upsampling扩大图像尺寸。在先减小再增大尺寸的过程中,肯定有一些信息损失掉了。
dilated conv是在已有的像素上,skip掉一些像素或者输入不变,对conv的kernel参数中插一些0的权值,实现参数不增加的同时,可以filter可以接收更大的感受野。
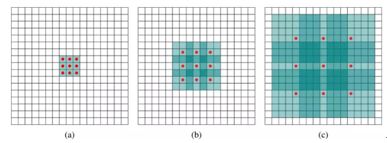
b)为3∗3+dilation=2 的空洞卷积,感受野为7∗7;(c)为3∗3+dilation=4的空洞卷积感受野为15∗15。
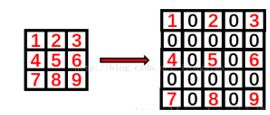
以 dilation=2 为例介绍了如何做二维空洞卷积(先做0填充,然后卷积)。
但是标准的Dilated/Atrous Convolution也有一些弊端:多次叠加相同的卷积模式,会导致feature map上部分像素信息没有参与计算,信息不连续;只用较大的 dilation rate 可能只对一些大物体分割有效果,对小物体就不太理想。一些研究者也提出了解决方案,比如Hybrid Dilated Convolution 等。
6、1x1卷积
1x1卷积(pointwise 卷积)应用很广泛,比如Resnet的瓶颈结构,Inception系列的一些网络,MobileNet中用DW卷积组合1x1卷积对网络进行轻量化等。1*1卷积是大小为1*1的滤波器做卷积操作,不同于2*2、3*3等filter,没有考虑在前一特征层局部信息之间的关系。
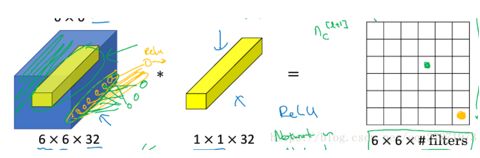 吴恩达课件
吴恩达课件
当设置多个1*1filter时,就可以随意增减输出的通道数,也就是降维和升维。

 Inception结构
Inception结构
参数:(1×1×192×64) + (3×3×192×128) + (5×5×192×32) = 153600。最终输出的feature map个数:64+128+32+192 = 416
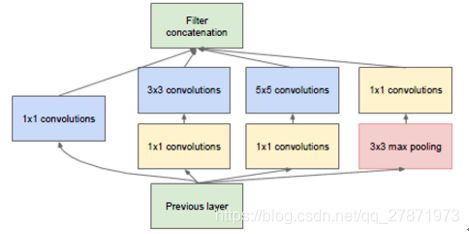 加1x1卷积的Inception
加1x1卷积的Inception
上图中在3x3,5x5 卷积层前新加入的1x1的卷积核为96和16通道的,max pooling后加入的1x1卷积为32通道。图中该层的参数:参数:(1×1×192×64)+(1×1×192×96+3×3×96×128)+(1×1×192×16+5×5×16×32)+(1x1x32)=15904 。最终输出的feature map个数: 64+128+32+32=256
filter数,一个滤波器在前一个feature map上进行一次卷积操作(特征抽取)会产生一个feature map或者叫通道、深度。
1*1卷积作用
1、降维。比如,一张500 * 500且厚度depth为100 的图片在20个filter上做1*1的卷积,那么结果的大小为500*500*20。
2、加入非线性。卷积层之后经过激励层,1*1的卷积在前一层的学习表示上添加了非线性激励,提升网络的表达能力;
3、增加模型深度。可以减少网络模型参数,增加网络层深度,一定程度上提升模型的表征能力。