Redis使用
String
set key value
get key
Hash(Map)
hset key mapkey mapvalue
hget key mapkey
一.數據結構
开发中还是String & Hash用的比较多,
1.list
Redis存储的list接口其实是一个双向链表、
其实就是咱们java中见到的LinkedList列表数据结构-----没下标,查询慢,增删快
左右可以被认为就是链表的 头 和 尾部
存:
lpush : 表示从左边加入数据
语法格式: lpush key 值1 值2 值3 ...
lpush mylist aa bb cc
rpush : 从右边加入数据
语法格式 rpush key 值1 值2 值3 ...
rpush mylist dd ee ff
----------------------------------------------------------
取:
语法: lrange key start end
lrange mylist 0 2
range: 表示是区间的意思。 那么上面这一句话的意思是: 从左边开始取数据 从0位置开始取, 取到2的位置。
如果想取全部的列表内容:
lrange mylist 0 -1 : -1表示链表的尾部。 也可以认为 -1 就是倒数第一个。
lrange mylist 0 -2 : -2表示链表的倒数第二个。
----------------------------------------------------------
两端弹出:
lpop mylist : 从左边弹出并返回链表的第一个元素, 若不存在该key, 那么返回nil . 弹出: 其实可以认为是删除的意思、并兼有返回
rpop mylist : 从右边弹出并返回链表的最后一个元素。
----------------------------------------------------------
返回列表元素个数:
语法格式: llen key
形如: llen mylist
----------------------------------------------------------
扩展命令:
1. 语法: lpushx key value
形如: lpushx list aobama . 意思是: 如果以前已经存在了一个key , 叫做 list, 那么在这个list的列表的前面加入 一个值 aobama . 假设没有,那么就不加数据。
2. 语法 : rpushx key value
形如: rpushx list telangpu . 这句话的意思,我就算不写,聪明的你一定能猜出来是什么意思的~
3. 语法: lrem key count value
形如: lrem list 3 aobama . 这句话的意思是: 删除这个list列表中 3个值为aobama的数据。 这种情况可能是在这列表中有很多个 aobama. 我们要删除3个。
这个地方 count还是有一点玄机的。
假设 count > 0 ,那么从左边找到右边。 找出 count的个数删除。
假设 count < 0 , 那么从右边开始找,找到右边, 找到count的个数删除
如果 count = 0 , 那么删除列表中的所有 value
注意:
value是数字,直接写即可。 如: lrem list 3 10 ----意思是,从这个key 为 list的列表中移除 3个 数字 10
vlaue是字母,那么需要加上'' ,如: lrem list 3 'aa' --意思是: 从这个key为list的列表中移除 3个 aa
4. 设置指定位置的值
语法: lset key index value
形如: lset list 2 aa 意思是: 设置 key为list的列表 下标位2的位置,内容为 aa. 0 表示列表的开始位置 , -1表示列表的结尾位置
5. 在指定值的前后插入新的值
语法: linsert key before|after pivot value
形如: linsert list before bb 55 . 意思是: 在list里列表里面,在bb这个value之前,插入一个新的值为55.
注意:这里有一个情况是: 如果在这个list列表里面,有很多个 bb 呢 , 那么到底是在哪个bb之前添加 55呢 。 这里只能在第一个bb之前添加数据。
6. 从源列表的尾部弹出值, 添加到目标里列表的开始位置。
语法格式:rpoplpush sourcekey targetkey
形如: rpoplpush list list02 : 意思是弹出list的结尾(右边) , 然后 添加到list02的前面(左边)去。
sourcekey 和 targetkey 可以是同一个 ,也可以不是同一个。 若为同一个, 那么表示 把自己的右边内容放置到左边来显示 。
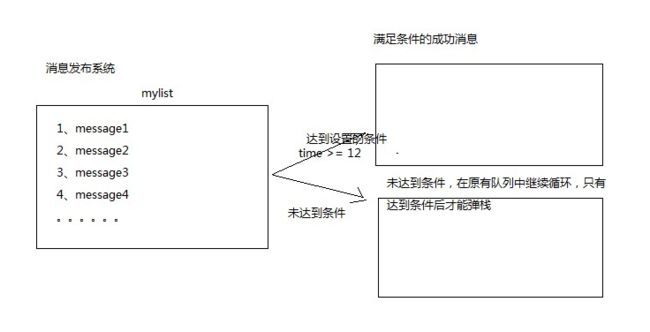
rpoplpush使用場景:
redis鏈經常會被用於消息隊列的服務,已完成多個程序之間的消息交換
2.set
Set 其实是没有排序的一个 set集合, 并且里面不允许出现重复数据。
除此之外,set还允许执行聚合函数。如: 交集、差集、并集...
存:
语法格式: sadd key 值1 值2 值3 ...
如: sadd myset aa bb cc
如果在来一句 sadd cc 这时候是不能成功的。因为之前就已经有了一个cc
取:
语法格式: smembers key
smembers myset
判断是否存在该值
语法格式 : sismember key 值
如: sismember myset aa
如果有 ,那么返回值是 1 ,如果没有或者压根都没有这个key,返回只是 0.
删:
语法格式: srem key 值1 值2 值3...
如: srem myset aa : 意思是,从myset集合中移除值aa
差集运算:
语法格式: sdiff key1 key2
意思是返回key1 与 key2 相差的值。 意思是: 属于key1 并且不属于 key2 的结果。
如:
sadd list a b c
sadd list02 a b e f
sdiff list list02 将会返回 c
交集运算:
语法格式: sinter key1 key2
交集: 是指这两个集合中都包含的值。
如: sinter list list02 .
list = {a,b,c}
list02 = {a,b,e,f}
那么将会返回 {a,b}
并集运算:
语法格式: sunion key1 key2
并集: 返回属于key1 或者 属于key的元素构成的集合。 不保留重复
如: sunion list list02 .
list = {a,b,c}
list02 = {a,b,e,f}
那么结果是:{a,b,c,e,f}
----------------------------------------------------------------------
扩展命令:
1. 获取set集合中的成员数量
语法格式: scard key
如: scard myset
2. 随机返回set集合中的一个成员
语法格式 : srandmember key
如: srandmember myset
3. 差集再存储操作。
语法格式: sdiffstore destination key1 key2 意思是: 将key1 key2的差集 存储到 destination上。
如: sdiffstore myset03 myset02 myset01 . 即使myset03不存在也可以的,也可以存储起来。 假设已经存在了myset03. 那么将会替换掉里面的内容。
4. 交集再存储操作
语法格式: sinterstore destination key1 key2 意思是: 将key1 key2的交集 存储到 destination上。
如: sinterstore myset03 myset02 myset01 . 即使myset03不存在也可以的,也可以存储起来。 假设已经存在了myset03. 那么将会替换掉里面的内容。
5. 并集再存储操作
语法格式: sunionstore destination key1 key2 意思是: 将key1 key2的并集集 存储到 destination上。
如: sunionstore myset03 myset02 myset01 . 即使myset03不存在也可以的,也可以存储起来。 假设已经存在了myset03. 那么将会替换掉里面的内容。
Set使用場景:
1.可以使用redis 的set 數據類型跟蹤一些唯一性數據,比如某一博客的唯一IP地址信息,我們衹需每次訪問時將IP地址存放到redis中,set數據類型就會自動保證IP地址的唯一性
2.Set类型服务端,聚合操作方便,高效的特性
用于维护数据对象之间的关联关系,
比如:購買某商品A客戶ID存放一個指定set,而購買另一商品的B客戶ID存放在另一個set
如此,想獲取有哪些客戶同時購買了這個兩種商品,set的intersections命令可以充分發揮它的方便和效率優勢了
3.SortedSet
Sorted-set 和 set有几分相似的特点。 都是无法存储重复数据。
并且它可以做出排序的效果。这个排序的效果需要依赖一个 score的分数。
存储到sorted-set里面的每一个元素都拥有一个score与之绑定上。
存:
语法格式: zadd key score member score member ...
如: zadd myset 70 aobama 80 xilali telangpu 90 意思是: 往一个叫做 myset的集合中添加三个元素 aobama 、xilali 、telangpu . 分别指定他们的分数是 70 、80、90
如果一个元素在set中已经存在,再次执行add操作,其实会替换以前的分数。并不会多加一个元素。 如:
zadd myset 88 aobama : 如果集合中存在了aobama , 那么aobama的分数将变成 88
取:
1. 获取指定元素的分数
语法格式: zscore key member
如: zscore myset aobama : 意思是返回myset集合中 aobama的分数
2. 获取集合中的元素个数
语法格式:zcard key
如: zcard myset : 返回myset集合的元素个数
删除:
1. 删除指定元素
语法格式: zrem key member [member ...]
如: zrem myset aobama : 意思是删除myset中的奥巴马
当然也可以一次删除多个 如: zrem myset aobama xilali
---------------------------------------------------------------
范围查询:
1. 查询指定范围的元素 ,根据脚标来查询 (返回的数据,按分数从小到大排列)
语法格式: zrange key start end [withscores]
如 : zrange myset 0 1 : 意思是: 查询myset集合中的 第0个下标元素 和 第一个下标元素返回。
如果想全部查询,那么语句为: zrange myset 0 -1 : -1在此处的意思是末尾,也可以认为是倒数第一个。
后面的中括号[withscores] 代表的意思是,可写可不写 。 如果写上如下代码。
zrange myset 0 -1 withscores : 那么意思是 查询所有元素,并且把元素对应的分数也给查询出来。
2. 查询指定范围的元素 ,根据脚标来查询 (返回的数据,按分数从大到小排列)
语法格式: zrevrange key start end [withscores]
这里就不过多演示了,其实跟上面是一样的,其实就是数据排列结果跟上面是相反的而已。
3. 删除属于某一个范围的元素(按下标界定)
语法格式: zremrangebyrank key start stop
如: zremrangebyrank myset 0 1 : 意思是: 删除0-1 的元素 此处也可以认为是按下标来进行删除
4. 删除属于某一个范围的元素(按分数界定)
语法格式: zremrangebyscore key min max
如: zremrangebyscore myset 50 80 : 意思是: 删除分数为50-80之间的元素 此处也可以认为是按分数来进行删除
-----------------------------------------------------------------------
扩展命令:
1. 查询指定分数范围的元素 ,并按分数小到大排列
语法格式: zrangebyscore key min max [withscores] [limit offset count]
如: zrangebyscore myset 0 100 witchscores 意思是: 返回 myset集合中,分数从0 到100的元素,按分数从小到大排列
zrangebyscore myset 0 100 witchscores limit 0 2 : 后面的limit 0 2 表示的是 跳过前面的0个元素, 返回2个元素
offset : 指的是跳过前面多少个元素
count : 指返回多少个元素
这跟大家早前学的分页差不多。
2. 增加指定成员分数
语法格式: zincrby key increment member
如: zincrby myset 10 aobama : 意思是: 给myset集合里面的aobama元素增加 10分 。 结果会返回奥巴马的分数
3. 获取分数在某个范围返回的元素个数
语法格式: zcount key min max
如: zcount myset 60 100 : 意思是 : 返回myset集合中 60 - 100分的元素个数有多少个。
4. 返回指定成员的排名 (按分数低到高排列,分数越低越排在前面)
语法格式: zrank key member
如: zrank myset aobama : 返回aobama 在myset的排名 , 分数最低的元素,返回值是0
5. 返回指定成员的排名 (按分数高到低排列,分数越高越排在前面 , 这有点类似考试的成绩排名了)
语法格式: zrevrank key member
如: zrevrank myset aobama : 返回aobama 在myset的排名 , 分数最高的元素,返回值是0
sortedset使用場景:
1.可以用于大型在线游戏的积分排行榜,每当玩家的分数发生变化,就执行zadd命令更新.此后在通过zrange命令获取积分topten的用户信息.
2.构建索引数据
二.jedis(重点)
官方推荐java语言访问Redis的一种方案
需要导入两个jar包 commons-pool2-2.3.jar 和 jedis-2.7.0.jar
//1. 创建Jedis客户端, 用于连接服务器
参数一: 指定Redis服务器所在
参数二:指定redis的端口好
Jedis jedis = new Jedis("192.168.204.129" ,6379);
//2. 存储
jedis.set("name", "aobama");
//3. 取值
String name = jedis.get("name");
注意: 若想使用jedis来访问redis, 一定要打开 6379端口。 打开的方式如下:
/sbin/iptables -I INPUT -p tcp --dport 6379 -j ACCEPT
/etc/rc.d/init.d/iptables save
连接池用法
/**
* 创建对象的方式 :
* 一:new 对象
*
* 二: 单例模式 。 静态方法 类.getInstance();
*
* 三: 工厂模式 PoolFactory.getPool()
*/
GenericObjectPoolConfig config = new GenericObjectPoolConfig();
//设置最大连接数
config.setMaxTotal(20);
//最大空闲数
config.setMaxIdle(10);
//1. 创建连接池
JedisPool pool = new JedisPool(config,"192.168.204.129" ,6379);
//2. 从连接池中获取对象
Jedis jedis =pool.getResource();
//3. 存储
jedis.set("address", "中国");
//4. 取值
String address = jedis.get("address");
//释放连接
jedis.close();
三.redis特性(了解)
1.多数据库
redis内部已经建好了16个数据库,0-15.默认是操作第0个
1. 切换数据库
select 1 选择1号数据库
2. 迁移数据到指定数据库
move key 1 从当前数据库中迁移 key到 1号数据库
如 : move myset 1
2.订阅发布
订阅&发布需要多个客户端协同工作。
由A客户端订阅 指定频道消息、由B客户端发布 指定频道的消息 。
一般会在网络聊天室中出现、实际开发当中这个知识点比较少用到。
演示如下:
分别启动两个终端。
A终端使用:
subscribe cctv5 : 意思是 ,该终端在订阅频道名为 cctv5的消息。
当然也可以进行批量订阅:
subscribe cctv* 只要频道是以cctv 打头的都进行订阅。
B 终端使用
publish cctv5 'i love china...' 发布消息
一旦B终端发布消息,那么A终端就会收到消息。
3.事务
Redis的事务 与关系型数据库的事务还是有一点区别的。
虽然都是包含了一组操作逻辑,但是关系型数据库是 只要这一组中有一个小动作失败,那么组内的所有逻辑都以失败告终。
Redis的却是,如果有一个小动作失败了,那么剩下的动作依然可以继续往下执行。
但是Redis的事务却可以保证Redis 的服务器在没有执行完事务中的所有逻辑,是不会再为其他Redis的客户端服务。也就是确保了事务不会被打断或者执行到一半的时候,突然被别的客户端插进来执行。
演示如下:
set num 10
开启事务:
multi
执行逻辑1
incrby num 5
执行逻辑2
incrby num x
执行逻辑3
incrby num 10
提交事务
exec (等同于我们平常见到的 commit)
回滚事务:
discard
四.redis持久化(了解)
1.RDB
默认就支持的,无需配置。
该机制是:在指定的时间间隔内将内存中的数据写入磁盘中。


2.AOF
需要配置,该机制是: 以日志的方式记录服务器所处理的每一个动作。Redis服务器在启动的时候,会读取该文件来重新构建数据库,
以保证启动后的数据库数据是完整的


五.部分异常
Throwable
兩個子類===>error & exception
runtimeException---運行時異常,
throw 用戶自定義異常--檢查時異常
斷言---AssertionError
Assert.assertEquals(s,"post");
成倍增長---outOfMemoryError異常
StringBuffer sb = new StringBuffer("1");
for(;;){
sb.append(sb);
}
實現Cloneable 才能用clone方法-------CloneNotSupportedException
相當於備份---地址值不一樣,其他都一樣
控製幀異常------對象爲空,調用方法或者調用屬性
不支持方法異常---UnsupportedOperationException
String[] s = new String(){"1","2"};
List list = Arrays.asList(s);
list.add("3");
//不支持add方法抛出異常