实现步骤:
1、通过水平投影对图形进行水平分割,获取每一行的图像;
2、通过垂直投影对分割的每一行图像进行垂直分割,最终确定每一个字符的坐标位置,分割出每一个字符;
先简单介绍一下投影法:分别在水平和垂直方向对预处理(二值化)的图像某一种像素进行统计,对于二值化图像非黑即白,我们通过对其中的白点或者黑点进行统计,根据统计结果就可以判断出每一行的上下边界以及每一列的左右边界,从而实现分割的目的。
下面通过Python+opencv来实现该功能
首先来实现水平投影:
import cv2
import numpy as np
'''水平投影'''
def getHProjection(image):
hProjection = np.zeros(image.shape,np.uint8)
#图像高与宽
(h,w)=image.shape
#长度与图像高度一致的数组
h_ = [0]*h
#循环统计每一行白色像素的个数
for y in range(h):
for x in range(w):
if image[y,x] == 255:
h_[y]+=1
#绘制水平投影图像
for y in range(h):
for x in range(h_[y]):
hProjection[y,x] = 255
cv2.imshow('hProjection2',hProjection)
return h_
if __name__ == "__main__":
#读入原始图像
origineImage = cv2.imread('test.jpg')
# 图像灰度化
#image = cv2.imread('test.jpg',0)
image = cv2.cvtColor(origineImage,cv2.COLOR_BGR2GRAY)
cv2.imshow('gray',image)
# 将图片二值化
retval, img = cv2.threshold(image,127,255,cv2.THRESH_BINARY_INV)
cv2.imshow('binary',img)
#水平投影
H = getHProjection(img)
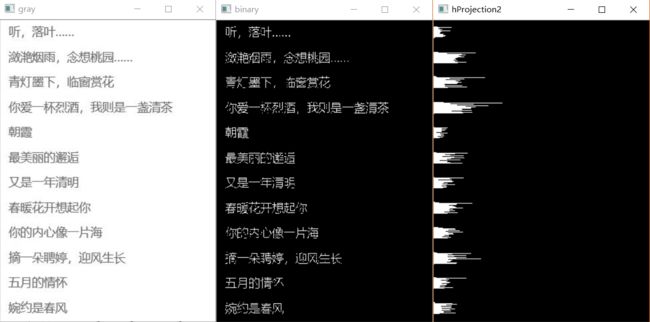
通过上面的水平投影,根据其白色小山峰的起始位置就可以界定出每一行的起始位置,从而把每一行分割出来。

获得每一行图像之后,可以对其进行垂直投影
def getVProjection(image):
vProjection = np.zeros(image.shape,np.uint8);
#图像高与宽
(h,w) = image.shape
#长度与图像宽度一致的数组
w_ = [0]*w
#循环统计每一列白色像素的个数
for x in range(w):
for y in range(h):
if image[y,x] == 255:
w_[x]+=1
#绘制垂直平投影图像
for x in range(w):
for y in range(h-w_[x],h):
vProjection[y,x] = 255
cv2.imshow('vProjection',vProjection)
return w_

通过垂直投影可以获得每一个字符左右的起始位置,这样也就可以获得到每一个字符的具体坐标位置,即一个矩形框的位置。
下面是实现的全部代码:
import cv2
import numpy as np
'''水平投影'''
def getHProjection(image):
hProjection = np.zeros(image.shape,np.uint8)
#图像高与宽
(h,w)=image.shape
#长度与图像高度一致的数组
h_ = [0]*h
#循环统计每一行白色像素的个数
for y in range(h):
for x in range(w):
if image[y,x] == 255:
h_[y]+=1
#绘制水平投影图像
for y in range(h):
for x in range(h_[y]):
hProjection[y,x] = 255
cv2.imshow('hProjection2',hProjection)
return h_
def getVProjection(image):
vProjection = np.zeros(image.shape,np.uint8);
#图像高与宽
(h,w) = image.shape
#长度与图像宽度一致的数组
w_ = [0]*w
#循环统计每一列白色像素的个数
for x in range(w):
for y in range(h):
if image[y,x] == 255:
w_[x]+=1
#绘制垂直平投影图像
for x in range(w):
for y in range(h-w_[x],h):
vProjection[y,x] = 255
#cv2.imshow('vProjection',vProjection)
return w_
if __name__ == "__main__":
#读入原始图像
origineImage = cv2.imread('test.jpg')
# 图像灰度化
#image = cv2.imread('test.jpg',0)
image = cv2.cvtColor(origineImage,cv2.COLOR_BGR2GRAY)
cv2.imshow('gray',image)
# 将图片二值化
retval, img = cv2.threshold(image,127,255,cv2.THRESH_BINARY_INV)
cv2.imshow('binary',img)
#图像高与宽
(h,w)=img.shape
Position = []
#水平投影
H = getHProjection(img)
start = 0
H_Start = []
H_End = []
#根据水平投影获取垂直分割位置
for i in range(len(H)):
if H[i] > 0 and start ==0:
H_Start.append(i)
start = 1
if H[i] <= 0 and start == 1:
H_End.append(i)
start = 0
#分割行,分割之后再进行列分割并保存分割位置
for i in range(len(H_Start)):
#获取行图像
cropImg = img[H_Start[i]:H_End[i], 0:w]
#cv2.imshow('cropImg',cropImg)
#对行图像进行垂直投影
W = getVProjection(cropImg)
Wstart = 0
Wend = 0
W_Start = 0
W_End = 0
for j in range(len(W)):
if W[j] > 0 and Wstart ==0:
W_Start =j
Wstart = 1
Wend=0
if W[j] <= 0 and Wstart == 1:
W_End =j
Wstart = 0
Wend=1
if Wend == 1:
Position.append([W_Start,H_Start[i],W_End,H_End[i]])
Wend =0
#根据确定的位置分割字符
for m in range(len(Position)):
cv2.rectangle(origineImage, (Position[m][0],Position[m][1]), (Position[m][2],Position[m][3]), (0 ,229 ,238), 1)
cv2.imshow('image',origineImage)
cv2.waitKey(0)
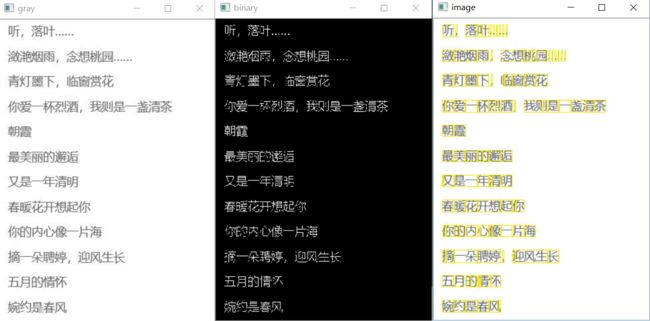
从分割的结果上看,基本上实现了图片中文字的分割。但由于中文结构复杂性,对于一些文字的分割并不理想,比如“叶”、“桃”等字会出现过度分割现象;对于有粘连的两个字会出现分割不够的现象,比如上图中的“念想”。不过可以从图像预处理(腐蚀),边界判断阈值的调整等方面进行优化。