手把手搭建TensorFlow神经网络简单例子——非线性回归
构建一个完整的神经网络,包括添加自定义网络层、计算误差、训练步骤等
import tensorflow as tf
import numpy as np
自定义网络层
def my_layer(inputs, in_size, out_size, activation_function=None):
w = tf.Variable(tf.random_normal([in_size, out_size])) # 因为在生成初始参数时,随机变量(normal distribution)会比全部为0要好很多,所以我们这里的weights为一个in_size行, out_size列的随机变量矩阵。
bias = tf.Variable(tf.zeros([1, out_size])+0.1) # 在机器学习中,biases的推荐值不为0,所以我们这里是在0向量的基础上又加了0.1。
# 下面,我们定义Wx_plus_b, 即神经网络未激活的值。其中,tf.matmul()是矩阵的乘法。
Wx_plus_b = tf.matmul(inputs, w) + bias
# 当activation_function为None时,输出就是当前的预测值——Wx_plus_b,不为None时,就把Wx_plus_b传到activation_function()函数中得到输出。
if activation_function is None:
outputs = Wx_plus_b
else:
outputs = activation_function(Wx_plus_b)
# 最后,返回输出
return outputs
导入数据
# 先构造所需数据,实际实验中用实验数据
x_data = np.linspace(-1,1,300,dtype=np.float32)[:, np.newaxis] # np.linspace()在指定的间隔内返回均匀间隔的数字
noise = np.random.normal(0, 0.05, x_data.shape).astype(np.float32)
y_data = np.square(x_data) - 0.5 + noise
# 利用占位符定义所需的神经网络输入
xs = tf.placeholder(tf.float32, [None, 1]) # None代表无论输入有多少都可以。因为输入只有一个特征,所以这里是1
ys = tf.placeholder(tf.float32, [None, 1])
接下来,我们就可以开始定义神经层了。 通常神经层都包括输入层、隐藏层和输出层。这里的输入层只有一个属性, 所以我们就只有一个输入;隐藏层我们可以自己假设,这里我们假设隐藏层有10个神经元; 输出层和输入层的结构是一样的,所以我们的输出层也是只有一层。 所以,我们构建的是——输入层1个、隐藏层10个、输出层1个的神经网络。
搭建网络
# 定义隐藏层
l1 = my_layer(xs, 1, 10, activation_function=tf.nn.relu) # 使用 Tensorflow 自带的激励函数tf.nn.relu
# 定义输出层。此时的输入就是隐藏层的输出——l1,输入有10层(隐藏层的输出层),输出有1层。
prediction = my_layer(l1, 10, 1, activation_function=None)
# pred = prediction.eval()
# 计算预测值与真实值之间的误差,这里采用均方误差
loss = tf.reduce_mean(tf.reduce_sum(tf.square(ys-prediction), axis=1)) # reduce_sum() 用于计算张量tensor沿着某一维度的和,可以在求和后降维
接下来,是很关键的一步,如何让机器学习提升它的准确率。tf.train.GradientDescentOptimizer()中的值通常都小于1,这里取的是0.1,代表以0.1的效率来最小化误差loss。
train_step = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
[2020-07-27 11:27:36,860] [INFO] [1586#MainThread] [../.local/lib/python3.6/site-packages/tensorflow/python/util/auto_strategy_utils.py:108] Disable Auto Strategy.
# 初始化变量
init = tf.global_variables_initializer()
# pred = [] # 定义预测结果
# 定义Session
sess = tf.Session()
# 用session执行init初始化步骤
sess.run(init)
训练
下面,让机器开始学习。
比如这里,我们让机器学习1000次。机器学习的内容是train_step, 用 Session 来 run 每一次 training 的数据,逐步提升神经网络的预测准确性。 (注意:当运算要用到placeholder时,就需要feed_dict这个字典来指定输入。)
for i in range(1000):
pred = sess.run(prediction, feed_dict={
xs:x_data}) # 将预测结果保存为ndarray
# print(type(pred1))
sess.run(train_step, feed_dict={
xs:x_data, ys:y_data})
# pred.extend(pred1)
if i%50 == 0:
print('loss:', sess.run(loss, feed_dict={
xs:x_data, ys:y_data}))
loss: 0.63628364
loss: 0.049008463
loss: 0.017530525
loss: 0.009206567
loss: 0.0072187544
loss: 0.0062632295
loss: 0.0054437136
loss: 0.004810252
loss: 0.0043729395
loss: 0.0040402594
loss: 0.003757407
loss: 0.0035299452
loss: 0.003324487
loss: 0.0031560475
loss: 0.0030254459
loss: 0.0029268647
loss: 0.0028413555
loss: 0.002776701
loss: 0.0027193136
loss: 0.0026768323
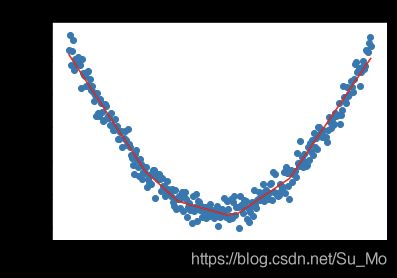
import matplotlib.pyplot as plt
# 把随机在坐标轴中打印出来
plt.xlabel("x")
plt.ylabel("y")
plt.title("Nonlinear Regression")
plt.scatter(x_data, y_data)
# 用最终训练的模型输出结果,在图上显示
plt.plot(x_data, pred,'r-' , label='拟合数据')
plt.show()