环境信息
-购买操作系统选择centos7(7的任何一个版本都可以),如果选错了可以在阿里云管理面板的-更多--云盘和镜像--更换操作系统。
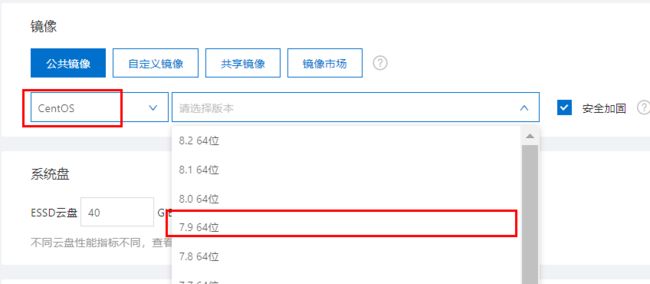
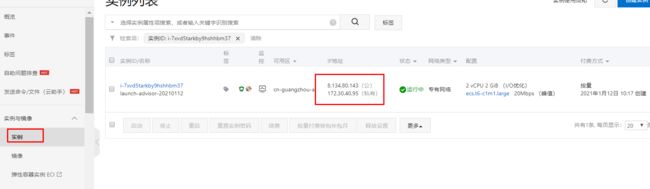
在阿里云购买ecs-购买后机器网卡环境:
公网IP-8.134.80.143、内网IP-172.30.40.95
设置阿里云端口映射:
开放3个端口
50070:hdfs管理端口
8088 : yarn 管理端口
60010:hbase管理端口
配置入口-->安全组-->配置规则
点击手动添加,添加8088、50070、60010端口
开始安装
整个一套安装配置内容比较多,顺序是:安装zookeeper--安装hadoop---安装hbase--springboot接入
安装zookeeper ,zookeeper版本不要选最后一个版本,选上下兼容hadoop、hbase的版本,这里选3.4.9就可以了。
安装java
yum -y install java-1.8.0-openjdk
配置java环境变量
执行:
export JAVA_HOME=/usr/lib/jvm/jre
export JRE_HOME=/usr/lib/jvm/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
source /etc/profile
下载zookeeper
wget http://archive.apache.org/dist/zookeeper/zookeeper-3.4.9/zookeeper-3.4.9.tar.gz
解压
tar -xzvf zookeeper-3.4.9.tar.gz
配置环境变量
vim /etc/profile
添加:
export ZOOKEEPER_HOME=/root/zookeeper-3.4.9
export PATH=$ZOOKEEPER_HOME/bin:$PATH
刷新环境变量
source /etc/profile
复制配置文件
cp /root/zookeeper-3.4.9/conf/zoo_sample.cfg /root/zookeeper-3.4.9/conf/zoo.cfg
创建目录:
/root/zookeeper-3.4.9/run
/root/zookeeper-3.4.9/run/data
/root/zookeeper-3.4.9/run/log
修改配置文件
vim /root/zookeeper-3.4.9/conf/zoo.cfg
修改如下两处(没有就增加):
dataDir=/root/zookeeper-3.4.9/run/data
dataLogDir=/root/zookeeper-3.4.9/run/log
启动zookeeper
zkServer.sh start
zk安装完成。
安装hadoop
hadoop,包括hdfs(分布式文件)、yarn(资源调度)、mapreduce(运算)
hadoop和hbase 有依赖关系,
hadoop这里选3.1.4,hbase 选2.3.3 能够兼容
下载hadoop
wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-3.1.4/hadoop-3.1.4.tar.gz
解压:
tar -zxvf hadoop-3.1.4.tar.gz
配置环境变量
vim /etc/profile
添加两行
export HADOOP_HOME=/root/hadoop-3.1.4
export PATH=${HADOOP_HOME}/bin:$PATH

刷新环境变量
source /etc/profile
修改hadoop配置文件
vim /root/hadoop-3.1.4/etc/hadoop/hadoop-env.sh
设置java_home
修改JAVA_HOME=/usr/lib/jvm/jre
创建目录:
mkdir /root/hadoop-3.1.4/run
mkdir /root/hadoop-3.1.4/run/hadoop
修改hosts文件,
vi /etc/hosts
添加1行(172.30.40.95为服务器内网地址):
172.30.40.95 hadoop1 hadoop1
修改配置文件core-site.xml
vim /root/hadoop-3.1.4/etc/hadoop/core-site.xml
修改hdfs配置,内容(没有就添加):
fs.defaultFS
hdfs://hadoop1:8020
hadoop.tmp.dir
/root/hadoop-3.1.4/run/hadoop
hadoop.native.lib
false
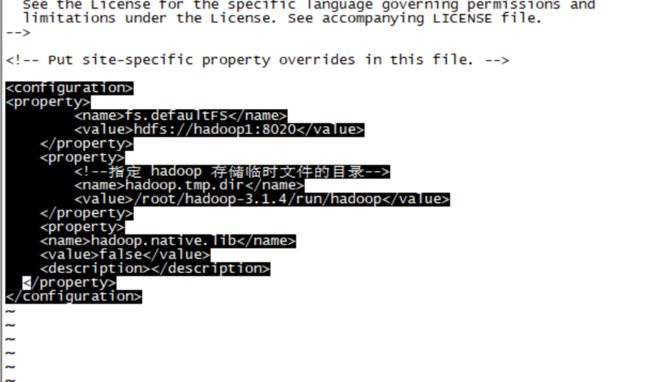
修改hdfs-site.xml文件
vim /root/hadoop-3.1.4/etc/hadoop/hdfs-site.xml
添加hdfs副本数配置,这里配置1 ,内容(172.30.40.95为服务器内网地址):
dfs.replication
1
dfs.secondary.http.address
172.30.40.95:50070

修改文件:mapred-site.xml
vim /root/hadoop-3.1.4/etc/hadoop/mapred-site.xml
内容:
mapreduce.framework.name
yarn
修改文件:yarn-site.xml
vim /root/hadoop-3.1.4/etc/hadoop/yarn-site.xml
内容:
yarn.nodemanager.aux-services
mapreduce_shuffle
主机访问设置
在root用户目录下执行,也就是/root目录下
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
格式化hdfs
/root/hadoop-3.1.4/bin/hdfs namenode -format
 image.png
image.png
修改hdfs启动脚本:
vim /root/hadoop-3.1.4/sbin/start-dfs.sh
顶部增加4行
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root

修改hdfs停止脚本:
vim /root/hadoop-3.1.4/sbin/stop-dfs.sh
顶部增加4行
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
修改yarn启动脚本:
vim /root/hadoop-3.1.4/sbin/start-yarn.sh
顶部增加3行
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
修改yarn停止脚本:
vim /root/hadoop-3.1.4/sbin/stop-yarn.sh
顶部增加3行
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
启动hdfs
export JAVA_HOME=/usr/lib/jvm/jre
(停止脚本:/root/hadoop-3.1.4/sbin/stop-dfs.sh)
/root/hadoop-3.1.4/sbin/start-dfs.sh
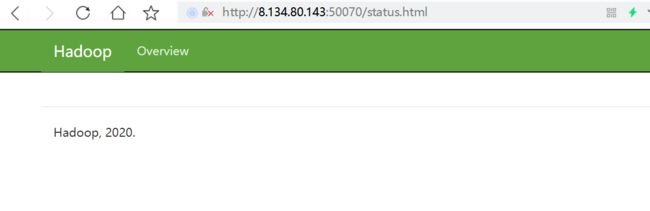
浏览器访问验证
地址:http://8.134.80.143:50070/
启动yarn
(停止脚本:/root/hadoop-3.1.4/sbin/stop-yarn.sh)
/root/hadoop-3.1.4/sbin/start-yarn.sh
浏览器访问验证
地址:http://8.134.80.143:8088/

hadoop 安装完成。
附:hadoop hbase 对应关系
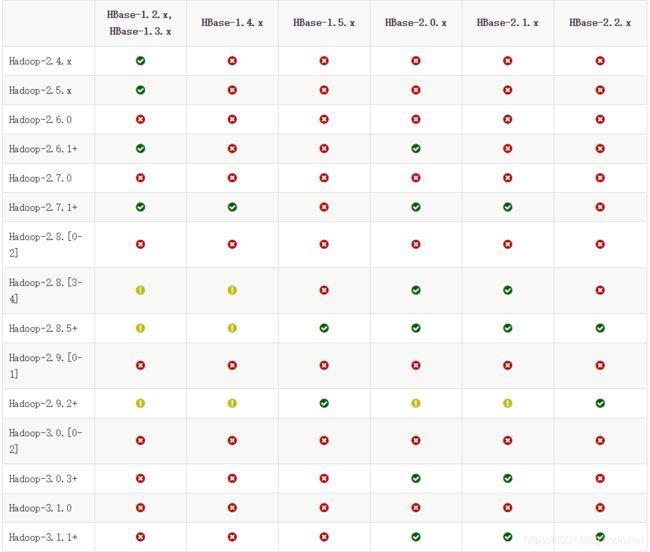
安装hbase
hbase 运行依赖zookeeper,前面已经安装好了。
下载hbase
wget http://mirror.bit.edu.cn/apache/hbase/2.3.3/hbase-2.3.3-bin.tar.gz
解压:
tar -zxvf hbase-2.3.3-bin.tar.gz
修改环境变量
vim /etc/profile
添加:
export HBASE_HOME=/root/hbase-2.3.3
export PATH=$HBASE_HOME/bin:$PATH
刷新环境变量:
source /etc/profile
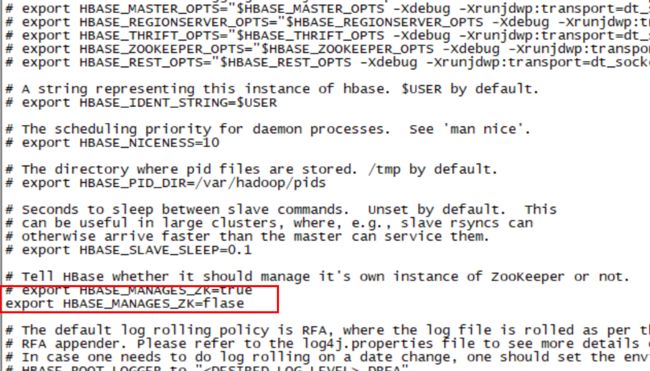
修改hbase配置文件
vim /root/hbase-2.3.3/conf/hbase-env.sh
设置java_home
修改2处
export JAVA_HOME=/usr/lib/jvm/jre
export HBASE_MANAGES_ZK=flase
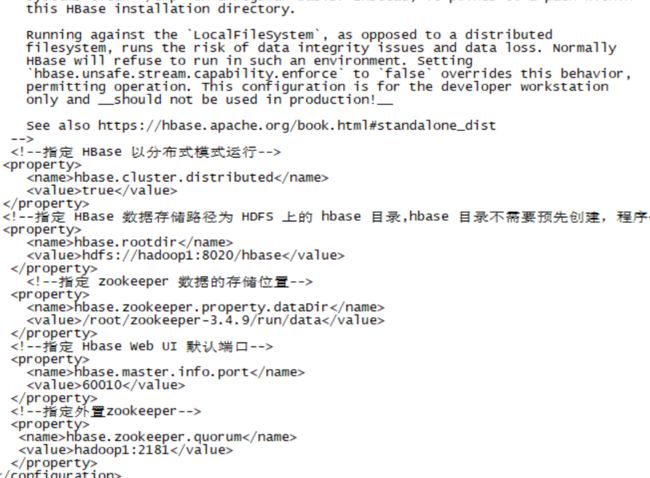
vim /root/hbase-2.3.3/conf/hbase-site.xml
修改为如下:
hbase.cluster.distributed
true
hbase.rootdir
hdfs://hadoop1:8020/hbase
hbase.zookeeper.property.dataDir
/root/zookeeper-3.4.9/run/data
hbase.master.info.port
60010
hbase.zookeeper.quorum
hadoop1:2181
修改 regionservers文件
vim /root/hbase-2.3.3/conf/regionservers
修改为:hadoop1

启动hbase
(停止脚本: /root/hbase-2.3.3/bin/stop-hbase.sh)
/root/hbase-2.3.3/bin/start-hbase.sh
测试hbase
浏览器打开:http://8.134.80.143:60010/

hbase安装完成。
SpringBoot接入调用
引用
pom文件引入
org.projectlombok
lombok
1.18.10
org.apache.hbase
hbase-client
2.3.3
org.slf4j
slf4j-log4j12
log4j
log4j
org.apache.hbase
hbase-server
2.3.3
org.slf4j
slf4j-log4j12
log4j
log4j
org.apache.hbase
hbase-common
2.3.3
org.slf4j
slf4j-log4j12
log4j
log4j
org.apache.hbase
hbase-mapreduce
2.3.3
org.slf4j
slf4j-log4j12
log4j
log4j
org.apache.hbase
hbase-annotations
2.3.3
log4j
log4j
1.2.16
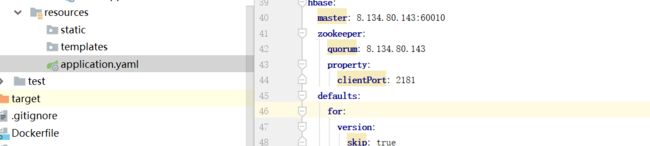
配置文件application.yaml 的hbase服务器参数
内容(8.134.80.143是阿里云公网IP):
hbase:
master: 8.134.80.143:60010
zookeeper:
quorum: 8.134.80.143
property:
clientPort: 2181
defaults:
for:
version:
skip: true
创建hbase操作和测试类
连接配置类-HbaseConfiguration:
内容:
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Scope;
import java.io.IOException;
import java.util.function.Supplier;
@Configuration
public class HbaseConfiguration {
@Value("${hbase.defaults.for.version.skip}")
private String skip;
@Value("${hbase.zookeeper.property.clientPort}")
private String clientPort;
@Value("${hbase.zookeeper.quorum}")
private String quorum;
@Value("${hbase.master}")
private String master;
@Bean
public org.apache.hadoop.conf.Configuration config() {
//这里启动会打印异常java.io.FileNotFoundException: java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset.
//该异常不影响应用,源码里面是window需要配置对应版本的hadoop客户端才不抛出这个错误,这个不影响程序运行,linux服务器不会走这个逻辑,所以不管就行了
org.apache.hadoop.conf.Configuration config = HBaseConfiguration.create();
config.set("hbase.defaults.for.version.skip", skip);
config.set("hbase.zookeeper.property.clientPort", clientPort);
config.set("hbase.zookeeper.quorum", quorum);
config.set("hbase.master", master);
return config;
}
@Bean
public Supplier hbaseConnSupplier() {
return () -> {
try {
return connection();
} catch (IOException e) {
throw new RuntimeException(e);
}
};
}
@Bean
@Scope(value = "prototype")
public Connection connection() throws IOException {
return ConnectionFactory.createConnection(config());
}
}
业务实现类-HbaseService:
import lombok.extern.slf4j.Slf4j;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.io.IOException;
import java.text.SimpleDateFormat;
import java.util.*;
@Slf4j
@Service
public class HbaseService {
@Autowired
private Connection hbaseConnection;
private String tableName = "tb_order";
/**
* 创建表
*/
public String createTable() throws IOException {
//获取管理员对象,用于创建表、删除表等
Admin admin = hbaseConnection.getAdmin();
//获取HTableDescriptor对象
HTableDescriptor hTableDescriptor = new HTableDescriptor(TableName.valueOf(tableName));
//给表添加列族名需要创建HColumnDescriptor对象
HColumnDescriptor order = new HColumnDescriptor("order");
HColumnDescriptor orther = new HColumnDescriptor("orther");
//先给表添加列族名
hTableDescriptor.addFamily(order);
hTableDescriptor.addFamily(orther);
//用管理员创建表
admin.createTable(hTableDescriptor);
//关闭admin
admin.close();
//hbaseConnection.close();
return tableName;
}
/**
* 创建订单
*/
public String createOrder(String code,String address,String state,String createName) throws IOException {
long r = (long) ((Math.random() * 9 + 1) * 100000000);
String rowKey =new SimpleDateFormat("yyyyMMddHHmmssSSS").format(new Date(System.currentTimeMillis()))+r;
String orderId =new SimpleDateFormat("yyyyMMddHHmmssSSS").format(new Date(System.currentTimeMillis()));
try (Table table = hbaseConnection.getTable(TableName.valueOf(tableName))) {//获取表连接
Put put = new Put(Bytes.toBytes(rowKey));
put.addColumn(Bytes.toBytes("order"), Bytes.toBytes("id"), Bytes.toBytes(orderId));
put.addColumn(Bytes.toBytes("order"), Bytes.toBytes("code"), Bytes.toBytes(code));
put.addColumn(Bytes.toBytes("order"), Bytes.toBytes("address"), Bytes.toBytes(address));
put.addColumn(Bytes.toBytes("order"), Bytes.toBytes("state"), Bytes.toBytes(state));
put.addColumn(Bytes.toBytes("orther"), Bytes.toBytes("create_name"), Bytes.toBytes(createName));
//put插入数据
table.put(put);
}
//hbaseConnection.close();
return rowKey;
}
/**
* 根据rowkey查找数据
*/
public Map findDataByRowKey(String rowKey) throws IOException {
Map rtn = new HashMap();
//获取get对象
Get get = new Get(Bytes.toBytes(rowKey));
//通过get获取数据 result封装了所有结果数据
try (Table table = hbaseConnection.getTable(TableName.valueOf(tableName))) {
get.addColumn("order".getBytes(),"id".getBytes());
get.addColumn("order".getBytes(),"code".getBytes());
get.addColumn("order".getBytes(),"address".getBytes());
get.addColumn("order".getBytes(),"state".getBytes());
get.addColumn("orther".getBytes(),"create_name".getBytes());
Result result = table.get(get);
Map familyMap = result.getFamilyMap(Bytes.toBytes("order"));
String id = Bytes.toString(familyMap.get(Bytes.toBytes("id")));
String code = Bytes.toString(familyMap.get(Bytes.toBytes("code")));
String address = Bytes.toString(familyMap.get(Bytes.toBytes("address")));
String state = Bytes.toString(familyMap.get(Bytes.toBytes("state")));
Map ortherfamilyMap = result.getFamilyMap(Bytes.toBytes("orther"));
String createName = Bytes.toString(ortherfamilyMap.get(Bytes.toBytes("create_name")));
rtn.put("id",id);
rtn.put("code",code);
rtn.put("address",address);
rtn.put("state",state);
rtn.put("createName",createName);
/* for(Map.Entry entry:familyMap.entrySet()){
System.out.println(Bytes.toString(entry.getKey())+":"+Bytes.toString(entry.getValue()));
}*/
}
return rtn;
}
/**查询一段时间范围类的数据**/
public List getRangeRowKey() throws IOException {
ArrayList rtnList = new ArrayList();
//创建Scan对象,获取到rk的范围-当天的数据,如果不指定范围就是全表扫描
String beginRow =new SimpleDateFormat("yyyyMMdd").format(new Date(System.currentTimeMillis()))+"000000000"+"00000000";
String endRow =new SimpleDateFormat("yyyyMMdd").format(new Date(System.currentTimeMillis()))+"999999999"+"00000000";
Scan scan = new Scan(beginRow.getBytes(),endRow.getBytes());
try (Table table = hbaseConnection.getTable(TableName.valueOf(tableName))) {
//拿到了多条数据的结果
ResultScanner scanner = table.getScanner(scan);
//循环遍历ResultScanner,将多条数据分成一条条数据
for (Result result : scanner) {
Map familyMap = result.getFamilyMap(Bytes.toBytes("order"));
String id = Bytes.toString(familyMap.get(Bytes.toBytes("id")));
String code = Bytes.toString(familyMap.get(Bytes.toBytes("code")));
String address = Bytes.toString(familyMap.get(Bytes.toBytes("address")));
String state = Bytes.toString(familyMap.get(Bytes.toBytes("state")));
Map ortherfamilyMap = result.getFamilyMap(Bytes.toBytes("orther"));
String createName = Bytes.toString(ortherfamilyMap.get(Bytes.toBytes("create_name")));
Map rtn = new HashMap();
rtn.put("id",id);
rtn.put("code",code);
rtn.put("address",address);
rtn.put("state",state);
rtn.put("createName",createName);
rtnList.add(rtn);
}
}
return rtnList;
}
}
hbase的controller测试类-HbaseController:
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.io.IOException;
import java.util.List;
import java.util.Map;
@Slf4j
@RestController
public class HbaseController {
@Autowired
private HbaseService hbaseService;
@RequestMapping("hbaseCreate")
public String create(){
String rtnName = "";
try {
rtnName = hbaseService.createTable();
} catch (IOException e) {
e.printStackTrace();
}
return "hbase成功:"+rtnName;
}
@RequestMapping("hbaseCreateOrder")
public String createOrder(String code,String address,String state,String createName){
String rtnName = "";
try {
rtnName = hbaseService.createOrder(code,address,state,createName);
} catch (IOException e) {
e.printStackTrace();
}
return "hbase工单创建成功:"+rtnName;
}
@RequestMapping("hbaseGet")
public Map get(String key){
Map info = null;
try {
info = hbaseService.findDataByRowKey(key);
} catch (IOException e) {
e.printStackTrace();
}
return info;
}
@RequestMapping("hbaseGetRang")
public List getRang(){
List info = null;
try {
info = hbaseService.getRangeRowKey();
} catch (IOException e) {
e.printStackTrace();
}
return info;
}
}
目录结构:

测试
本地测试前,需要设置一下本机的hosts文件,添加阿里云服务器的名称和公网IP的映射。
找到本地hosts文件(windows在:C:\Windows\System32\drivers\etc\hosts),添加:
8.134.80.143 iZ7xvd5tarkby9hshhbm37Z
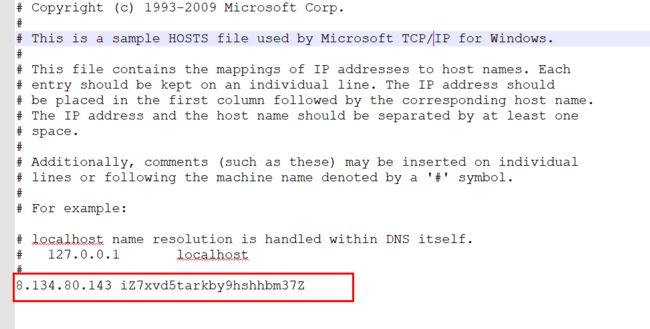
注意:(iZ7xvd5tarkby9hshhbm37Z是阿里云主机的服务器名称,不知道名称,可以在服务器上查看名称,这里服务器名字自动创建的没有改名字,所以显得有点长)
hostname
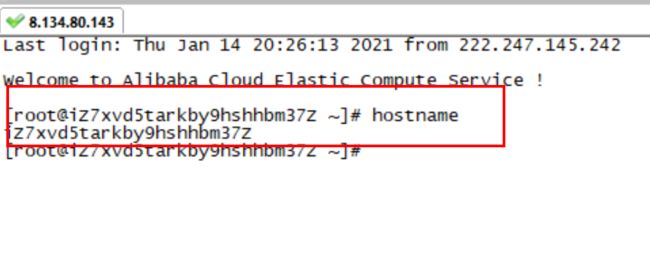
启动项目
启动会打印连接日志,连接失败是显示异常。

注意:
windows IDEA 启动打印的“java.io.FileNotFoundException: java.io.FileNotFoundException: HADOOP_HOME ”是没有配置hadoop客户端,这里不需要配置,源码里面是去找exe文件,源码打印的也只是告警信息,这里我们用不到,linux服务器也不会走这个逻辑,直接忽略。
开始测试
创建订单表
浏览器访问:http://localhost:8080/hbaseCreate
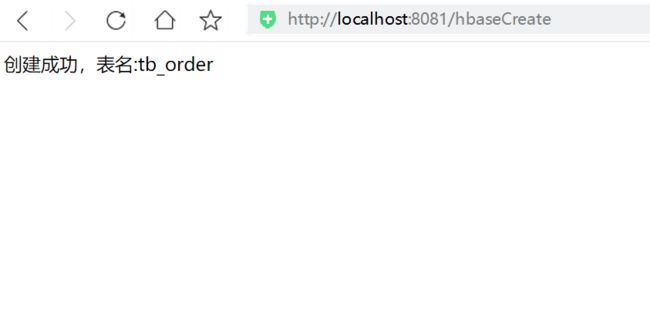
创建订单
浏览器访问:http://localhost:8080/hbaseCreateOrder?code=202101142025&address=cs0103&state=1&createName=georgekaren3
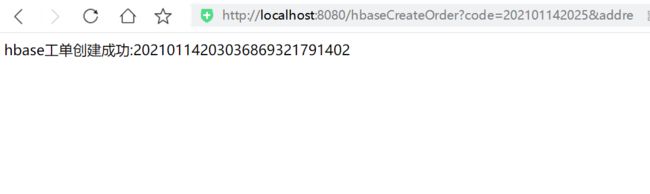
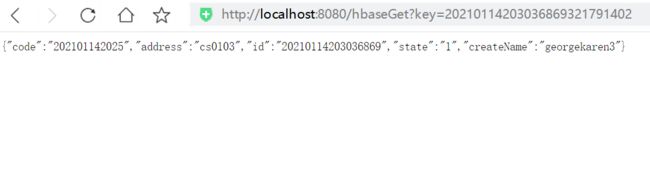
根据rowkey查询工单信息
浏览器访问:http://localhost:8080/hbaseGet?key=20210114203036869321791402
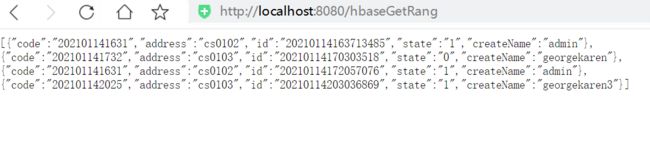
查询一段时间的工单信息
浏览器访问:http://localhost:8080/hbaseGetRang
测试成功,部署调用完成。