可视化 绘制正弦余弦曲线
案例:
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import pyplot as plt
plt.rcParams["font.sans-serif"] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
#可视化
#折线图
#绘制正弦曲线
#[0,2π]闭区间的等间距100个点
x=np.linspace(0,2*np.pi,num=100)
print(x)
siny=np.sin(x)
cosy=np.cos(x)
plt.xlabel('时间(s)')
plt.ylabel('电压(v)')
plt.title('正弦电压曲线')
plt.plot(x, siny,color='g',linestyle='--',marker='+',label='sin(x)')
plt.plot(x, cosy,color='r',label='cos(x)')
plt.legend()
plt.show()
输出结果:

image.png
饼状图
案例:
from matplotlib import pyplot as plt
plt.rcParams["font.sans-serif"] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
from random import randint
import string
#饼图
counts=[randint(3500,10000) for i in range(5)]
print(counts)
labels=['员工{}'.format(i) for i in string.ascii_uppercase[:5]]
print(labels)
#距离圆心的距离
#autopct百分比
explode=[0.2,0,0,0,0]
colors=['red','yellow','blue','purple','green']
plt.pie(counts,explode=explode,labels=labels,shadow=True,colors=colors,autopct='%1.1f%%')
plt.legend(loc=3)
plt.title('员工工资占比图')
plt.show()
输出结果:

image.png
散点图
案例:
from matplotlib import pyplot as plt
plt.rcParams["font.sans-serif"] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
x=np.random.normal(0,1,100000)
y=np.random.normal(0,1,100000)
#alpha为透明度
plt.scatter(x,y,alpha=0.1)
plt.show()
输出结果:

字典解析
和集合很像
和列表推导式很像
案例:
from random import randint
stu_grade={'student{}'.format(i):randint(50,100) for i in range(1,101)}
for k,v in stu_grade.items():
print(k,v)
#筛选出及格的学生
res_dict={k:v for k,v in stu_grade.items() if v>60}
for k,v in res_dict.items():
print(k,v)
输出结果:
image.png
集合解析
案例:
from random import randint
set1={randint(50,100) for i in range(1,101)}
print(set1)
#筛选能被3整除的
res={x for x in set1 if x%3==0}
for x in res:
print(x)
输出结果:

image.png
输出三国TOP10饼状图
案例:
import jieba
from wordcloud import WordCloud
#1、读取文件
with open('threekingdom.txt','r',encoding='UTF-8')as f:
words=f.read()
word_list=jieba.lcut(words)
excludes = {"将军", "却说", "丞相", "二人", "不可", "荆州", "不能", "如此", "商议",
"如何", "主公", "军士", "军马", "左右", "次日", "引兵", "大喜", "天下",
"东吴", "于是", "今日", "不敢", "魏兵", "陛下", "都督", "人马", "不知",
'孔明曰', '玄德曰', '刘备', '云长'}
# print(word_list)
# print(len(word_list))
#定义一个字典{‘夏侯渊’:788,‘不来’:56}
counts={}
for word in word_list:
#删除靠前与人名无关的词汇
if len(word)==1:
continue
else:
#往字典里添加元素
# count[word]=取出字典中原来的计数+1
# count[word]=count[word]+1
counts[word]=counts.get(word,0)+1
# print(counts)
counts['孔明']=counts['孔明曰'] + counts['孔明']
counts['玄德']=counts['玄德曰'] + counts['玄德'] + counts['刘备']
counts['关公']=counts['关公'] + counts['云长']
#将counts转化成列表
for word in excludes:
del counts[word]
items=list(counts.items())
def sort_by_count(x):
return x[1]
items.sort(key=sort_by_count,reverse=True)
# print(items)
# 显示计数前20词语
role_list=[]
for i in range(10):
#拆包 序列解包
role_name,count=items[i]
print(role_name,count)
#给读代码的人看的,_代表并没有使用临时变量
# for _ in range(1):
# role_list.append(role_name)
# # print(role_list)
# text=' '.join(role_list)
# WordCloud(
# background_color='white',
# width=800,
# height=600,
# font_path='msyh.ttc',
# #相同匹配词的处理
# collocations=False
# ).generate((text)).to_file('top10.png')
import matplotlib.pyplot as plt
plt.rcParams["font.sans-serif"] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# print(items)
print(items[0:10:1])
dict1=dict(items[0:10:1])
print(dict1)
x = ["{}".format(i) for i in dict1.keys()]
print(x)
y = [i for i in dict1.values()]
print(y)
# 绘制 条形图
explode=[0.2,0,0,0,0,0,0,0,0,0]
plt.pie(y,explode=explode,labels=x,shadow=True,autopct='%1.1f%%')
plt.legend(loc=1)
plt.title('三国人物出场次数占比图')
plt.show()
输出结果:
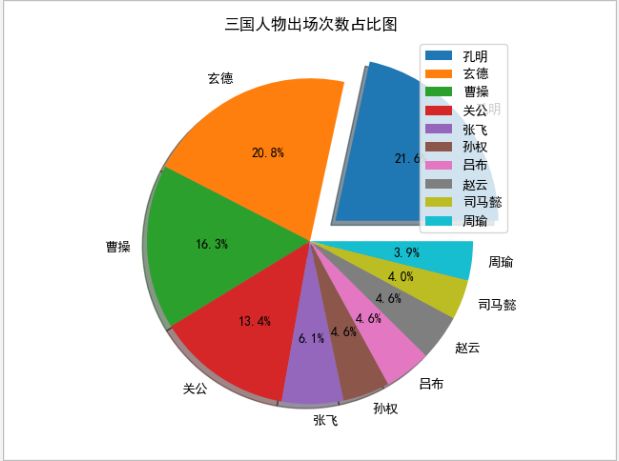
image.png
Python爬虫
案例(爬取豆瓣TOP250电影):
# -*- coding: utf-8 -*-
# @Time : 2019/7/24 15:22
# @Author : Eric Lee
# @Email : [email protected]
# @File : 豆瓣top250爬虫.py
# @Software: PyCharm
import requests
from lxml import etree
def parse():
"""豆瓣网top250爬虫"""
# 1、获取url地址
# for i in range(0, 226, 25):
# url = 'https://movie.douban.com/top250?start={}&filter='.format(i)
# print(url)
# # 获取 byte的类型的响应
# resp = requests.get(url)
# data = resp.content
headers = {"User-Agent": "ozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36"}
url = 'https://movie.douban.com/top250?start=0&filter='
# 获取 byte的类型的响应
resp = requests.get(url,headers=headers)
data = resp.content
# 调用etree.HTML获取html对象,然后调用html的xpath语法
html = etree.HTML(data)
movie_list = html.xpath('//div[@id="content"]//ol/li')
print(len(movie_list))
for movie in movie_list:
# 获取电影序号
serial_number = movie.xpath('./div[@class="item"]/div[@class="pic"]/em/text()')
serial_number = '' if len(serial_number)==0 else serial_number[0]
print(serial_number)
movie_name = movie.xpath('./div[@class="item"]/div[@class="info"]/div[@class="hd"]/a/span[1]/text()')
movie_name = '' if len(movie_name) == 0 else movie_name[0]
print(movie_name)
# 电影介绍
# introduce =
introduce = movie.xpath('./div[@class="item"]/div[@class="info"]/div[@class="bd"]/p/text()')
introduce = '' if len(introduce) == 0 else introduce[0]
print(introduce)
# 电影星级
# star =
star = movie.xpath('./div[@class="item"]/div[@class="info"]/div[@class="bd"]/div[@class="star"]/span[2]/text()')
star = '' if len(star) == 0 else star[0]
print(star)
# 电影的评价
# evalute =
evalute = movie.xpath('./div[@class="item"]/div[@class="info"]/div[@class="bd"]/div[@class="star"]/span[4]/text()')
evalute = '' if len(evalute) == 0 else evalute[0]
print(evalute)
# 电影的描述
# describe =
describe = movie.xpath('./div[@class="item"]/div[@class="info"]/div[@class="bd"]/p[@class="quote"]/span[1]/text()')
describe = '' if len(describe) == 0 else describe[0]
print(describe)
parse()
输出结果:

image.png