NodeJS 于其它任何平台的区别在于它如何处理 I/O。当我们听到 NodeJS 被一些人介绍的时候总是说:非阻塞,基于 google v8 js 引擎的事件驱动平台。这些意味着什么?”非阻塞“和”事件驱动“是什么意思?
所有的这些都在于 NodeJS 的核心,即 Event Loop.在接下来的一些列内容中,我将描述event loop 是什么,它如何工作,它如何作用于我们的应用,如何更好去应用它以及更多。为什么是一系列内容而不是一个?因为这个真的说来话长我肯定会有一些遗漏,所以我将写一个系列。在这第一篇文章中,我将描述 NodeJS 如何工作,它如何获取 I/O 以及如何运行在不同的平台上等等。
Reactor 模式:
NodoJS 在事件驱动模型工作时需要 Event Demultiplexer 和事件队列。所有的 I/O 请求将会最终生成一个完成或者失败的事件或者其它的触发,这些都叫做 Event(事件)。这些事件的进行是遵循一定的算法规则的。
- Event demultiplexer 接收 I/O 请求然后将他们分发到合适的硬件上。
- 一旦处理了 I/O 请求(比如 可以读取来自文件的数据, 可以读取来自套接字的数据等等),event demultiplexer 将为队列中的特定动作添加已注册的回调处理程序。这些回调事件被称为 events 以及这个被添加事件的队列被称作事件队列。
- 当事件在队列中准备好被执行的时候,它们会按照接收顺序依次执行,直到队列为空。
- 如果事件队列中没有事件了,或者 Event Demultiplexer 没有任何待处理的请求了,程序将会完成,否则,进程会从第一步继续执行。
编排整个机制的程序被称作事件循环(Event Loop)
事件循环是单线程(single threaded)并且半无限的循环。它被称为半无限循环的原因是因为当没有更多的工作要做时,实际上会在某个时刻退出。 从开发人员的角度来看,这是程序退出的地方。
note: 不要混淆了事件循环和事件派发(Event Emitter)。事件派发完全和这个循环机制是不一样的概念。接下去的一篇文章中,我将解释事件派发如何通过事件循环去影响事件处理过程。

上面的示意图是一个描述 NodeJS 如何工作的高度概览,以及展示了这个设计模式中的主要组成。该设计模式称为 Reactor Pattern ,实际上会更复杂。那么到底有多复杂呢?
tips:
- Event demultiplexer 并不是一个单一的组件去做所有操作系统上的所有类型的 I/O 操作。
- 事件队列也不是一件单一的像这边展示的队列一样。其中所有类型的事件都会被放入以及出队列,I/O 不是唯一的会被放进队列的事件类型。
所以让我们再深入了解一下。
Event Demultiplexer
Event Demultiplexer 不是一个现实世界中真是存在的组件实物,而是一个在 reactor 模式中的抽象概念。在现实世界中,event dumultiplexer 在不同的系统中的实现被叫做不同的名字,比如 Linux 中被叫做 epoll,BSD 系统(MacOS)中的 kqueue,Solaris 的 event ports,Windows 中的 IOCP 等等。NodeJS 使用这些实现的低级非阻塞,异步硬件 I/O 功能。
复杂的文件 I/O(Complexities in File I/O)
令人困惑的事实是,不是所有的类型的 I/O 都可以使用这些实现来执行。即使是在同样的操作系统平台上,也存在很多复杂的对不同 I/O 类型的支持。通常,网络 I/O 可以使用这些 epoll、kqueue、事件端口和 IOCP以非阻塞方式执行,但文件 I/O 却要复杂得多。某些系统(Certain systems)如 Linux 不支持文件系统访问的完全异步。在 MacOS 系统中,使用 kqueue 处理文件系统事件通知/信令会存在一些存在限制(您可以在此处阅读有关这些复杂情况的更多信息here)解决所有这些文件系统复杂性以提供完全异步是非常复杂且几乎不可能的。
复杂的 DNS
与文件 I/O 类似,Node API 提供的特定 DNS 功能也有特定的复杂性,由于 NodeJS DNS 函数比如 dns.lookup 获取系统配置文件比如 nsswitch.conf, resolv.conf 以及 /etc/hosts,上述描述的文件系统复杂性一样也适用于 dxn.resolve 功能。
解决方式?
因此,引入了一个线程池被用于支持 I/O 函数,但是这些函数不能由硬件异步 I/O 工具比如 epoll/kqueue/event ports 或者 IOCP 直接寻址。现在我们知道不是所有的 I/O 函数会在线程池中执行。NodeJS 已尽最大努力使用非阻塞和异步硬件 I/O 来完成大部分 I/O,但是对于阻塞或者更复杂的 I/O 类型【注:此处有一个 complex to address,更复杂的寻址?】,需要用到线程池。
总结
正如我们所见,在现实世界中,在所有的不同类型的操作系统平台上支持所有类型的 I/O(文件 I/O,网络 I/O,DNS 等等)是非常难的,一些 I/O 可以直接在原生的硬件设施上被支持,并且保留完全的异步,但是也有一些 I/O 类型需要在线程池中被执行来达到异步。
tips: 关于 Node,很多开发者都有一个常见的误解是 Node 执行线程池中的所有 I/O.
为了在支持跨平台 I/O 的同时管理整个过程,应该有一个抽象层,它封装了这些平台间和平台内的复杂性,并为Node 的上层暴露出一个通用的 API。
所以谁做了这个,女士们先生们,有请:libuv
从 libuv 的官方文档中,提到:
- libuv 是最初为 NodeJS 编写的跨平台支持库,它是围绕事件驱动异步 I/O 模型来设计的。
- 该库提供的不仅仅是对不同 I/O 轮询机制(polling mechanisms)的简单抽象:'handle' 和 'streams' 为套接字和其他实体(entities)提供高级抽象; 除此之外,还提供跨平台文件 I/O 和线程功能。
现在让我看看 libuv 的组成。下面的示意图来自于 libuv 的官网文档,描述了不同类型的 I/O 是如何通过被暴露的通用 API 处理的。

现在我们知道 Event Demultiplexer,不是一个原子实体【注:其实这里就是指不是最小的粒度了】,而是一个由 Libuv 抽象并暴露给 NodeJS 上层的 I/O 处理 API 的集合。它不仅是 libuv 提供给 Node 的 event demultiplexer。Libuv 为 NodeJS 提供了完整的事件循环功能,包括事件队列机制。
现在让我们看一下事件队列。
事件队列(Event Queue)
事件队列被认为是一个所有事件被排列以及通过事件循环机制执行直到队列清空的数据结构,但是在 Node 中是如何发生的和抽象 reactor 模式的描述完全不一致的。所以哪里不一样呢?
tips:
- NodeJS 中有多个队列,不同类型的事件在不同的队列中排队。
- 在处理一个阶段后并且在移动到下一个阶段之前,事件循环将会处理两个中间队列,直到没有任何一个项目被遗留在中间队列中。
所以到底有多少个队列呢?这些中间队列是什么呢?
原生的 Libuv 事件循环中主要处理四个队列类型
- 过期的计时器及 intervals 队列(Expired timers and intervals queue)-- 通过使用 setTimeout 添加的 expired timers 或者由 interval 函数添加 setInterval 组成的 interval 函数。
- IO 事件队列(IO Event Queue) — 完整的 IO 事件
- Immediates 队列(Immediates Queue) — 通过 setImmediate 函数添加的回调函数
- Close Handlers 队列(Close Handlers Queue) -- 任何 Close Handlers
tips: 请注意,尽管我为了简单起见,将所有的这些都称为“队列”,但是实际上他们都会有不同的数据结构(比如计时器是存储在最小堆中(min-heap))
除了这四种队列,还有2个我刚才提到的有趣的中间队列被 Node 执行。虽然这些队列不是 libuv 自己的一部分,但是是 NodeJS 的一部分,它们是:
- Next Ticks Queue -- 通过 process.nextTick 函数添加的回调函数
- 其它微服务队列(Other Microtasks Queue) -- 包括其它微服务比如 peomise 里的 resolved 回调函数
它是如何工作的呢?
正如你所见下面的示例图,Node 通过在计时器中检查任何过期计时器开始事件循环,并在每个步骤中浏览每个队列,同时保持要处理的总项目的参考计数器(and go through each queue in each step while maintaining a reference counter of total items to be processed)。在处理完关闭处理队列(close handlers queue)的进程后,如果队列中没有任何项目要执行,这个循环将会退出。每个在事件循环中执行的队列可以被看做是事件循环中的一个阶段。

红色描述的中间队列比较有趣的一点是,一旦一个阶段完成了,事件循环将会检查两个中间队列是否有任何可用的项目。如何这里有任何可用项目在中间队列,事件循环将会马上开始执行它们直到两个中间队列被清空。一旦它们被清空,事件循环将会继续执行执行下一个阶段。
栗子:事件循环当前执行了有5个事件的 immediates 队列(immediates queue)。同时,两个事件被添加到 next tick 队列中,一旦事件循环完成了在 immediates 队列中的五个事件,事件循环将会在移动到下一个 close handlers 队列之前发现这里有两个项目在 next tick 队列中需要被执行。然后它将会执行所有 next tick 队列中的事件,再移动到 close handlers 队列中。
Next tick 队列和其他 Microtasks
Next tick 队列比其它微任务队列拥有更高的优先级。虽然它们都是事件循环中的一环。当 libuv 在阶段结束时回传给更高层的 Node。你注意到我用暗红色表示 next tick 队列,表示在开始 microtasks 队列中的 promise sesolved 进程结束前, next tick 队列将会清空。
tips:
- next tick 队列的优先级高于 promises resolved 仅仅是在 v8 引擎提供的原生 JS Promises 适用。如果你使用了如 q 或者 bluebird 之类的库,你会发现会出现完全不一样的结果,因为他们优先于原生的 promise 并且有不同的语义。
- q 和 bluebird 同样有不同的处理 prosemise resolved 的处理方式,我将会在之后的文章中解释。
这些被称作"中间"队列的通常也会引入一个新的问题,IO 饥饿(IO starvation)。到处通过 process.nextTick 函数填充 next tick 队列将会强制事件循环进程一直处理 next tick 队列而不是向前移动。这个将会导致 IO starvation ,因为事件循环不能执行下一步除非 next tick 队列被清空。
tips: 为了避免这个,他们通过用 process.maxTickDepth 参数给 next tick 队列设置最大限制,但是它由于某些原因在 NodeJS v0.12 被移除了。
我将在接下去的几篇文章用一些例子深入讲解这些队列。
最后,现在你知道事件循环是什么了,以及它如何实现以及 Node 如何处理异步I/O。现在让我们来看一下在 NodeJS 架构中 Libuv 处于哪个位置。
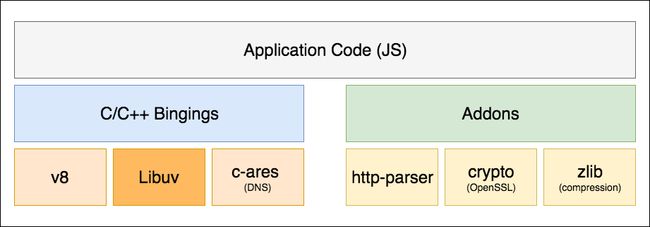
原文链接:https://jsblog.insiderattack.net/event-loop-and-the-big-picture-nodejs-event-loop-part-1-1cb67a182810