Hadoop Yarn 高可用配置时的错误解决办法
找不到或无法加载主类 org.apache.hadoop.mapreduce.v2.app.MRAppMaster
配置Yarn ResourceManager 高可用时,遇到了一个坑。
找不到或无法加载主类 org.apache.hadoop.mapreduce.v2.app.MRAppMaster
参考了网上各种解决办法,运行演示程序 cd $HADOOP_HOME/share/hadoop/mapreduce; hadoop jar hadoop-mapreduce-examples-3.2.0.jar pi 50 100000;ls;
总是报这个错误。
肯定是哪里配置错了,于是写了个java 类,先验证一下,到底路径上有没有这个类.
[hadoop@hadoop-namenode1 test]$ more FindClass.java
public class FindClass {
public static void main(String[] args){
ClassLoader classLoader = FindClass.class.getClassLoader();
try {
Class aClass = classLoader.loadClass("org.apache.hadoop.mapreduce.v2.app.MRAppMaster");
System.out.println("找到了类 aClass.getName() = " + aClass.getName());
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
}
javac FindClass.java
java FindClass
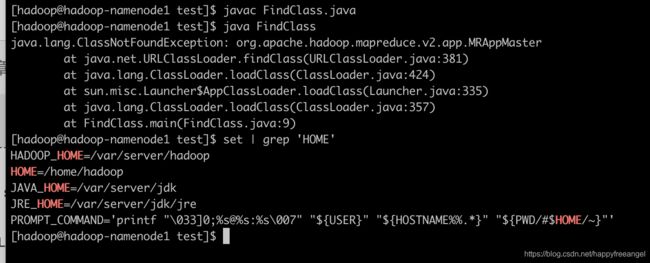
如上图所示,
[hadoop@hadoop-namenode1 test]$ hadoop classpath
WARNING: HADOOP_PREFIX has been replaced by HADOOP_HOME. Using value of HADOOP_PREFIX.
/var/server/hadoop/etc/hadoop:/var/server/hadoop/share/hadoop/common/lib/:/var/server/hadoop/share/hadoop/common/:/var/server/hadoop/share/hadoop/hdfs:/var/server/hadoop/share/hadoop/hdfs/lib/:/var/server/hadoop/share/hadoop/hdfs/:/var/server/hadoop/share/hadoop/mapreduce/lib/:/var/server/hadoop/share/hadoop/mapreduce/:/var/server/hadoop/share/hadoop/yarn:/var/server/hadoop/share/hadoop/yarn/lib/:/var/server/hadoop/share/hadoop/yarn/
[hadoop@hadoop-namenode1 test]$ yarn classpath
WARNING: HADOOP_PREFIX has been replaced by HADOOP_HOME. Using value of HADOOP_PREFIX.
WARNING: YARN_LOG_DIR has been replaced by HADOOP_LOG_DIR. Using value of YARN_LOG_DIR.
/var/server/hadoop/etc/hadoop:/var/server/hadoop/share/hadoop/common/lib/:/var/server/hadoop/share/hadoop/common/:/var/server/hadoop/share/hadoop/hdfs:/var/server/hadoop/share/hadoop/hdfs/lib/:/var/server/hadoop/share/hadoop/hdfs/:/var/server/hadoop/share/hadoop/mapreduce/lib/:/var/server/hadoop/share/hadoop/mapreduce/:/var/server/hadoop/share/hadoop/yarn:/var/server/hadoop/share/hadoop/yarn/lib/:/var/server/hadoop/share/hadoop/yarn/
[hadoop@hadoop-namenode1 test]$
export CLASSPATH=$(hadoop classpath):.
java FindClass
说明类路径上确实是有这个org.apache.hadoop.mapreduce.v2.app.MRAppMaster类的.
于是认真看了yarn-site.xml
发现重复设置了2次yarn.application.classpath属性,后面的属性是空的,把前面的有效属性覆盖了,正确的配置如下:
[hadoop@hadoop-namenode1 hadoop]$ more yarn-site.xml
yarn.application.classpath
/var/server/hadoop/etc/hadoop:/var/server/hadoop/share/hadoop/common/lib/*:/var/server/hadoop/share/hadoop/common/*:/var/server/hadoop/share/hadoop/hdfs:/var/server/hadoop/share/hadoop/hdfs/lib/*:/var/server/hadoop/share/ha
doop/hdfs/*:/var/server/hadoop/share/hadoop/mapreduce/lib/*:/var/server/hadoop/share/hadoop/mapreduce/*:/var/server/hadoop/share/hadoop/yarn:/var/server/hadoop/share/hadoop/yarn/lib/*:/var/server/hadoop/share/hadoop/yarn/*
yarn.log-aggregation-enable
true
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.cluster-id
mycluster
yarn.resourcemanager.ha.rm-ids
rm1,rm2,rm3
yarn.resourcemanager.hostname.rm1
hadoop-namenode1
yarn.resourcemanager.hostname.rm2
hadoop-namenode2
yarn.resourcemanager.hostname.rm3
hadoop-namenode3
yarn.resourcemanager.address.rm1
hadoop-namenode1:8032
yarn.resourcemanager.scheduler.address.rm1
hadoop-namenode1:8030
yarn.resourcemanager.resource-tracker.address.rm1
hadoop-namenode1:8031
yarn.resourcemanager.admin.address.rm1
hadoop-namenode1:8033
yarn.resourcemanager.webapp.address.rm1
hadoop-namenode1:8088
yarn.resourcemanager.address.rm2
hadoop-namenode2:8032
yarn.resourcemanager.scheduler.address.rm2
hadoop-namenode2:8030
yarn.resourcemanager.resource-tracker.address.rm2
hadoop-namenode2:8031
yarn.resourcemanager.admin.address.rm2
hadoop-namenode2:8033
yarn.resourcemanager.webapp.address.rm2
hadoop-namenode2:8088
yarn.resourcemanager.address.rm3
hadoop-namenode3:8032
yarn.resourcemanager.scheduler.address.rm3
hadoop-namenode3:8030
yarn.resourcemanager.resource-tracker.address.rm3
hadoop-namenode3:8031
yarn.resourcemanager.admin.address.rm3
hadoop-namenode3:8033
yarn.resourcemanager.webapp.address.rm3
hadoop-namenode3:8088
yarn.resourcemanager.recovery.enabled
true
yarn.resourcemanager.ha.id
rm1
If we want to launch more than one RM in single node, we need this configuration
yarn.resourcemanager.store.class
org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore
hadoop.zk.address
10.6.1.51:2181,10.6.1.52:2181,10.6.1.53:2181
For multiple zk services, separate them with comma
yarn.resourcemanager.ha.automatic-failover.enabled
true
Enable automatic failover; By default, it is enabled only when HA is enabled.
yarn.client.failover-proxy-provider
org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider
yarn.nodemanager.resource.cpu-vcores
4
yarn.nodemanager.resource.memory-mb
12288
yarn.scheduler.minimum-allocation-mb
1024
yarn.scheduler.maximum-allocation-mb
12288
yarn.log-aggregation.retain-seconds
2592000
yarn.nodemanager.log.retain-seconds
604800
yarn.nodemanager.log-aggregation.compression-type
gz
yarn.nodemanager.local-dirs
/var/server/yarn/local
yarn.resourcemanager.max-completed-applications
1000
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.connect.retry-interval.ms
2000
echo "一键启动hadoop集群,替代默认的start-all.sh"
su hadoop
hdfs zkfc -formatZK -force
cat $HADOOP_PREFIX/etc/hadoop/datanode-hosts-exclude | xargs -i -t ssh hadoop@{} "rm -rf /var/server/hadoop/tmp/hadoop-hadoop-zkfc.pid;hdfs --daemon start zkfc"
cat $HADOOP_PREFIX/etc/hadoop/datanode-hosts-exclude | xargs -i -t ssh hadoop@{} "hdfs --daemon start journalnode"
cat $HADOOP_PREFIX/etc/hadoop/datanode-hosts-exclude | xargs -i -t ssh hadoop@{} "hdfs --daemon start namenode"
cat $HADOOP_PREFIX/etc/hadoop/slaves | xargs -i -t ssh hadoop@{} "hdfs --daemon start datanode"
pwd;
#分2次
su yarn;
$HADOOP_PREFIX/sbin/start-yarn.sh
cat $HADOOP_PREFIX/etc/hadoop/slaves | xargs -i -t ssh yarn@{} "yarn --daemon start nodemanager"
pwd;
echo "查看resource manager 高可用是否正常."
yarn rmadmin -getServiceState rm1;
yarn rmadmin -getServiceState rm2;
yarn rmadmin -getServiceState rm3;
echo "批量关闭防火墙"
cat $HADOOP_PREFIX/etc/hadoop/datanode-hosts-exclude | xargs -i -t ssh root@{} "systemctl disable firewalld;systemctl stop firewalld"
cat $HADOOP_PREFIX/etc/hadoop/slaves | xargs -i -t ssh root@{} "systemctl disable firewalld;systemctl stop firewalld"
su hadoop
echo "运行官方map reduce 实例,测试系统是否正常运行"
#cd $HADOOP_HOME/share/hadoop/mapreduce; hadoop jar hadoop-mapreduce-examples-3.0.0-beta1.jar pi 50 100000;ls;
cd $HADOOP_HOME/share/hadoop/mapreduce; hadoop jar hadoop-mapreduce-examples-3.2.0.jar pi 50 100000;ls;