装好并设置好MySQL的 root 账户的密码后就可以尝试使用 Windows 上的 Navicat 之类的可视化工具连接该数据库了。连接好后创建一个名为 hive 的数据库,字符集选择 utf-8 ,排序规则选择 utf8_general_ci (当然你也可以直接使用 Linux 下的 MySQL 命令行客户端创建该数据库: CREATE DATABASE hive DEFAULT CHARACTER SET utf8;)。
cd /usr/local/hive/apache-hive-2.3.4-bin/conf
cp hive-env.sh.template hive-env.sh
# Set HADOOP_HOME to point to a specific hadoop install directory
HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.7
# Hive Configuration Directory can be controlled by:
export HIVE_CONF_DIR=/usr/local/hive/apache-hive-2.3.4-bin/conf
javax.jdo.option.ConnectionURLjdbc:mysql://127.0.0.1:3306/hive?characterEncoding=UTF-8&serverTimezone=GMT%2B8
JDBC connect string for a JDBC metastore.
To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL.
For example, jdbc:postgresql://myhost/db?ssl=true for postgres database.
javax.jdo.option.ConnectionDriverNamecom.mysql.cj.jdbc.DriverDriver class name for a JDBC metastorejavax.jdo.option.ConnectionUserNamerootUsername to use against metastore databasejavax.jdo.option.ConnectionPasswordAa123456!password to use against metastore database
最后找到以下参数,进行如下配置:
hive.exec.local.scratchdir/usr/local/hive/apache-hive-2.3.4-bin/tmp/${user.name}Local scratch space for Hive jobshive.downloaded.resources.dir/usr/local/hive/apache-hive-2.3.4-bin/iotmp/${hive.session.id}_resourcesTemporary local directory for added resources in the remote file system.hive.querylog.location/usr/local/hive/apache-hive-2.3.4-bin/iotmp/${system:user.name}Location of Hive run time structured log filehive.server2.logging.operation.log.location/usr/local/hive/apache-hive-2.3.4-bin/iotmp/${system:user.name}/operation_logsTop level directory where operation logs are stored if logging functionality is enabledhive.server2.thrift.bind.hostbigdataBind host on which to run the HiveServer2 Thrift service.
# 还需要在开头处添加以下配置:
system:java.io.tmpdir/usr/local/hive/apache-hive-2.3.4-bin/iotmp
至此就完成了使用外部 MySQL 数据库服务器配置 Metastore 的全过程,控制台结果输出如下:
[root@bigdata apache-hive-2.3.4-bin]# schematool -dbType mysql -initSchema
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/hive/apache-hive-2.3.4-bin/lib/log4j-slf4j-impl-2.6.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/hadoop/hadoop-2.7.7/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Metastore connection URL: jdbc:mysql://127.0.0.1:3306/hive?characterEncoding=UTF-8&serverTimezone=UTC
Metastore Connection Driver : com.mysql.cj.jdbc.Driver
Metastore connection User: root
Starting metastore schema initialization to 2.3.0
Initialization script hive-schema-2.3.0.mysql.sql
Initialization script completed
schemaTool completed
[root@bigdata ~]# beeline -u jdbc:hive2://bigdata:10000
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/hive/apache-hive-2.3.4-bin/lib/log4j-slf4j-impl-2.6.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/hadoop/hadoop-2.7.7/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Connecting to jdbc:hive2://bigdata:10000
Connected to: Apache Hive (version 2.3.4)
Driver: Hive JDBC (version 2.3.4)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 2.3.4 by Apache Hive
0: jdbc:hive2://bigdata:10000>
0: jdbc:hive2://bigdata:10000> load data inpath '/input/1.txt' overwrite into table words;
No rows affected (0.557 seconds)
执行 WordCount 操作,将结果保存到新表 wordcount 中:
0: jdbc:hive2://bigdata:10000> create table wordcount as select word, count(1) as count from (select explode(split(line,' '))as word from words) w group by word order by word;
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
No rows affected (43.34 seconds)
[root@bigdata spark-2.4.2-bin-hadoop2.7]# ./bin/spark-shell
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://bigdata:4040
Spark context available as 'sc' (master = local[*], app id = local-1557543612970).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.2
/_/
Using Scala version 2.12.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_211)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
转自于:http://www.iteye.com/problems/23775
问:
我在开发过程中,使用hql进行查询(mysql5)使用到了mysql自带的函数find_in_set()这个函数作为匹配字符串的来讲效率非常好,但是我直接把它写在hql语句里面(from ForumMemberInfo fm,ForumArea fa where find_in_set(fm.userId,f
1、下载软件 rzsz-3.34.tar.gz。登录linux,用命令
wget http://freeware.sgi.com/source/rzsz/rzsz-3.48.tar.gz下载。
2、解压 tar zxvf rzsz-3.34.tar.gz
3、安装 cd rzsz-3.34 ; make posix 。注意:这个软件安装与常规的GNU软件不
Forwarded port
Private network
Public network
Vagrant 中一共有三种网络配置,下面我们将会详解三种网络配置各自优缺点。
端口映射(Forwarded port),顾名思义是指把宿主计算机的端口映射到虚拟机的某一个端口上,访问宿主计算机端口时,请求实际是被转发到虚拟机上指定端口的。Vagrantfile中设定语法为:
c
Given a 2D board and a word, find if the word exists in the grid.
The word can be constructed from letters of sequentially adjacent cell, where "adjacent" cells are those horizontally or ve
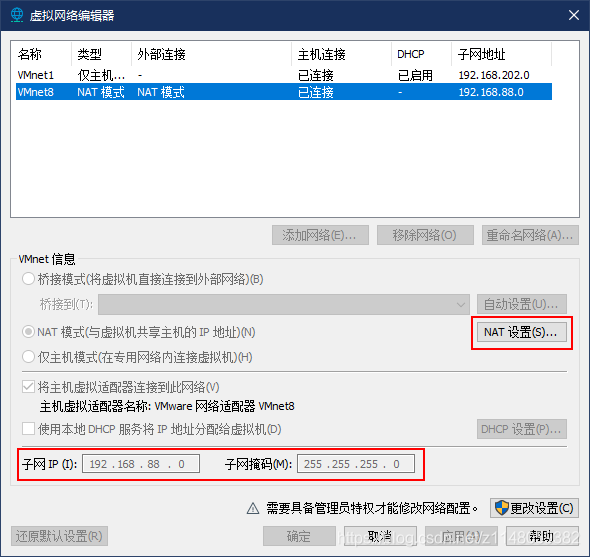

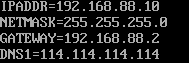
 (其实就是设成 Hadoop 的 core-site.xml 配置文件中 fs.defaultFS 配置的值)
(其实就是设成 Hadoop 的 core-site.xml 配置文件中 fs.defaultFS 配置的值)