- 总体设计
- 单个热图
- 产生随机数据
- 最基本的显示
- 颜色的改变
- 连续性变量的颜色注释
- 分类变量的颜色注释
- 缺失值的可视化
- 边框的变化
- 标题
- 聚类
- 基本设置
- 聚类的方法选择
- 聚类树的自定义
- 基于聚类结果进行排序
- 设置热图的观测值的顺序
- 观测值的自定义
- 热图的分割
- 热图本身的自定义
- 热图的大小
学习指南只要是对于作者提供的学习指南。另外学习的包一定要是github上的。如果是bioconductor上的则会有些参数不支持。
总体设计
绘制热图的包有很多。其实比较好用是的包有
pheatmap包。一般的热图绘制只能只能绘制热图本身。并不能在热图旁边绘制别的图。为了能够添加其他的图,因此开发了complexheatmap包。-
complexheatmap包主要是可以通过不同的对于热图各个部分(上下左右)的注释来扩展热图的功能。 image.png
image.png 该包主要可以使用到函数包括
Heatmap: 绘制单个的热图。这个图本身就包括所有的组成HeatmapList:绘制一系列的热图和注释HeatmapAnnotation:对热图进行注释,可以和热图一起时候,也可以单独的使用
单个热图
通过Heatmap我们就可以形成单个热图。
产生随机数据
library(ComplexHeatmap)
## Loading required package: grid
## ========================================
## ComplexHeatmap version 2.0.0
## Bioconductor page: http://bioconductor.org/packages/ComplexHeatmap/
## Github page: https://github.com/jokergoo/ComplexHeatmap
## Documentation: http://jokergoo.github.io/ComplexHeatmap-reference
##
## If you use it in published research, please cite:
## Gu, Z. Complex heatmaps reveal patterns and correlations in multidimensional
## genomic data. Bioinformatics 2016.
## ========================================
set.seed(123)
nr1 = 4; nr2 = 8; nr3 = 6; nr = nr1 + nr2 + nr3
nc1 = 6; nc2 = 8; nc3 = 10; nc = nc1 + nc2 + nc3
mat = cbind(rbind(matrix(rnorm(nr1*nc1, mean = 1, sd = 0.5), nr = nr1),
matrix(rnorm(nr2*nc1, mean = 0, sd = 0.5), nr = nr2),
matrix(rnorm(nr3*nc1, mean = 0, sd = 0.5), nr = nr3)),
rbind(matrix(rnorm(nr1*nc2, mean = 0, sd = 0.5), nr = nr1),
matrix(rnorm(nr2*nc2, mean = 1, sd = 0.5), nr = nr2),
matrix(rnorm(nr3*nc2, mean = 0, sd = 0.5), nr = nr3)),
rbind(matrix(rnorm(nr1*nc3, mean = 0.5, sd = 0.5), nr = nr1),
matrix(rnorm(nr2*nc3, mean = 0.5, sd = 0.5), nr = nr2),
matrix(rnorm(nr3*nc3, mean = 1, sd = 0.5), nr = nr3))
)
mat = mat[sample(nr, nr), sample(nc, nc)] # random shuffle rows and columns
rownames(mat) = paste0("row", seq_len(nr))
colnames(mat) = paste0("column", seq_len(nc))
mat[1:5,1:5]
## column1 column2 column3 column4 column5
## row1 0.90474160 -0.35229823 0.5016096 1.26769942 0.8251229
## row2 0.90882972 0.79157121 1.0726316 0.01299521 0.1391978
## row3 0.28074668 0.02987497 0.7052595 1.21514235 0.1747267
## row4 0.02729558 0.75810969 0.5333504 -0.49637424 -0.5261114
## row5 -0.32552445 1.03264652 1.1249573 0.66695147 0.4490584
最基本的显示
通过Heatmap函数我们可以对矩阵进行可视化。最基本的热图和其他热图绘制工具绘制出来的是一样的。 PS:如果我们把绘图结果放到了一个变量里面,我们可以通过draw函数来把结果绘制出来
ht <- Heatmap(mat)
draw(ht)

颜色的改变
连续性变量的颜色注释
- 在热图当中如果需要改变颜色的话,一定要使用
circlize::colorRamp2()来对颜色进行赋值。这个函数接受两个参数:颜色分割的位置以及相应分割点上的颜色。最后我们的Heatmap当中通过col来制定颜色
PS:colorRamp2默认的使用的配色方案是LAB的。如果想使用RGB的则可以通过其中的space参数进行修改。
library(circlize)
## ========================================
## circlize version 0.4.6
## CRAN page: https://cran.r-project.org/package=circlize
## Github page: https://github.com/jokergoo/circlize
## Documentation: http://jokergoo.github.io/circlize_book/book/
##
## If you use it in published research, please cite:
## Gu, Z. circlize implements and enhances circular visualization
## in R. Bioinformatics 2014.
## ========================================
col_fun <- colorRamp2(c(-2, 0, 2), c("navy", "white", "firebrick3"))
Heatmap(mat, col = col_fun)

这样设定的好处在于:
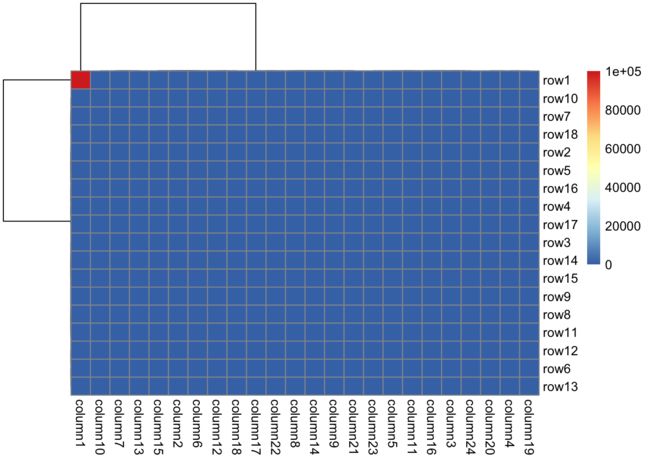
- 即使出现了异常值,在制定的颜色当中,异常值也只是显示最大值而不是说是把整体的颜色分布给破坏了。我们可以比较一下
pheatmap和Heatmap的结果
mat2 = mat
mat2[1, 1] = 100000
Heatmap(mat2, name = "mat", col = col_fun)

pheatmap::pheatmap(mat2)
- 另外一个好处是,如果我们要比较不同组数据的热图,这样设置后,他们的数值对应的颜色不会因为整体分布的原因发生改变
p1 <- Heatmap(mat, name = "mat", col = col_fun, column_title = "mat")
p2 <- Heatmap(mat/4, name = "mat", col = col_fun, column_title = "mat/4")
p3 <- Heatmap(abs(mat), name = "mat", col = col_fun, column_title = "abs(mat)")
p1 + p2 + p3
## Warning: Heatmap/annotation names are duplicated: mat
## Warning: Heatmap/annotation names are duplicated: mat, mat

分类变量的颜色注释
如果要绘制分类变量的热图的话,则需要把每个分类的数字进行一定的赋值。
discrete_mat = matrix(sample(1:4, 100, replace = TRUE), 10, 10)
col1 = structure(1:4, names = c("1", "2", "3", "4")) # black, red, green, blue
mycol <- colorRamp2(breaks = col1, colors = c("red", "blue", "green", "black"))
h1 <- Heatmap(discrete_mat, col = col1)
h2 <- Heatmap(discrete_mat, name = "mat", col = mycol)
h1 + h2

缺失值的可视化
如果数据当中含有缺失值,如果我们不想去掉想要可视化的话,可以通过na_col来指定颜色
mat_with_na = mat
na_index = sample(c(TRUE, FALSE), nrow(mat)*ncol(mat), replace = TRUE, prob = c(1, 9))
mat_with_na[na_index] = NA
Heatmap(mat_with_na, name = "mat", na_col = "black")

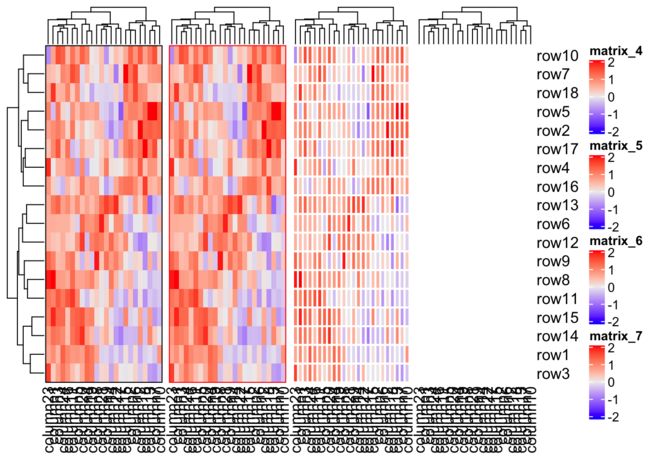
边框的变化
- 通过
border,来对整个热图添加边框。这个参数可以接受逻辑值或者具体的颜色 - 每个格子的边框的变化,我们可以通过
rect_gp来进行设置。这个参数可以通过gpar来设置其颜色以及线条宽度的变化。同样可以把这个热图到去掉
h1 <- Heatmap(mat, border = T)
h2 <- Heatmap(mat, border = "red")
h3 <- Heatmap(mat, rect_gp = gpar(col = "white", lwd = 2))
h4 <- Heatmap(mat, rect_gp = gpar(type = "none"))
h1 + h2 + h3 + h4
标题
通过上图,我们可以使用对热图的四周都可以进行标题注释。
通过
column_title以及row_title来设置标题通过
column_title_side以及row_title_side来设置标题位置通过
column_title_gp以及row_title_gp设置标题的格式。通过gpar函数来进行设置。通过
row_title_rot以及column_title_rot设置标题的旋转角度
Heatmap(mat, column_title = "column title", column_title_side = "bottom", column_title_gp = gpar(fontsize = 20, fontface = "bold"), row_title_rot = 0, row_title = "row title", row_title_gp = gpar(col = "red"))

聚类
基本设置
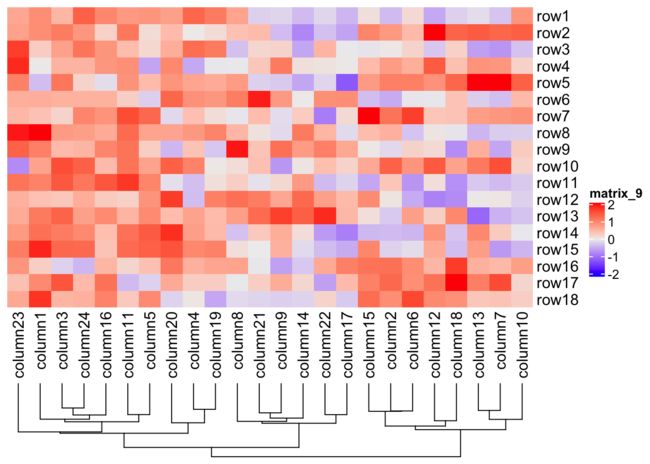
无监督的聚类属于热图的可视化的一个重要组成部分。
cluster_rows/columns来设置是否进行聚类show_column/row_dend设置是否显示聚类树(会发生聚类)column/row_dend_side设置聚类图绘制的位置column/row_dend_height设置聚类树的高度
Heatmap(mat, cluster_rows = F, show_column_dend = T,
column_dend_side = "bottom", column_dend_height = unit(2, "cm"))
聚类的方法选择
分类聚类只要包括两步:计算距离矩阵以及应用聚类。一般来说计算距离的方式包括pearson, spearman以及kendall。这个计算方式是通过1 - - cor(x, y, method)来实现的。在函数当中则是通过clustering_distance_rows/columns来进行实现的。
Heatmap(mat, name = "mat", clustering_distance_rows = "pearson",
column_title = "pre-defined distance method (1 - pearson)")

聚类树的自定义
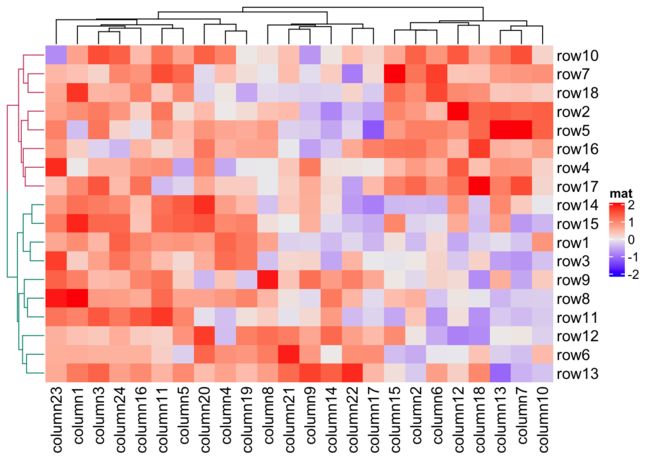
我们可以对聚类树进行自定义,主要是可以
column/row_dend_gp设置聚类图的自定义cluster_rows分开设置不同的颜色
library(dendextend)
##
## ---------------------
## Welcome to dendextend version 1.12.0
## Type citation('dendextend') for how to cite the package.
##
## Type browseVignettes(package = 'dendextend') for the package vignette.
## The github page is: https://github.com/talgalili/dendextend/
##
## Suggestions and bug-reports can be submitted at: https://github.com/talgalili/dendextend/issues
## Or contact:
##
## To suppress this message use: suppressPackageStartupMessages(library(dendextend))
## ---------------------
##
## Attaching package: 'dendextend'
## The following object is masked from 'package:stats':
##
## cutree
row_dend = as.dendrogram(hclust(dist(mat)))
row_dend = color_branches(row_dend, k = 2) # `color_branches()` returns a dendrogram object
Heatmap(mat, name = "mat", cluster_rows = row_dend)
Heatmap(mat, name = "mat", cluster_rows = row_dend, row_dend_gp = gpar(col = "red"))

基于聚类结果进行排序
我们可以通过column/row_dend_reorder来对聚类的结果进行重新排序
m2 = matrix(1:100, nr = 10, byrow = TRUE)
h1 <- Heatmap(m2, name = "mat", row_dend_reorder = FALSE, column_title = "no reordering")
h2 <- Heatmap(m2, name = "mat", row_dend_reorder = TRUE, column_title = "apply reordering")
h1 + h2
## Warning: Heatmap/annotation names are duplicated: mat

设置热图的观测值的顺序
一般情况下,热图当中各个观测值的顺序是基于聚类的分组来进行排列的。有时候我们想要自己排序顺序。这个时候就可以自定义去顺序。通过row_order/column_order可以来定义其排序。 PS:当我们自定义顺序之后,聚类的顺序就随之关闭了。
Heatmap(mat, name = "mat", row_order = sort(rownames(mat)),
column_order = sort(colnames(mat)))

观测值的自定义
默认情况下对于列名和行名都是显示的。我们可以对其进行自定义
show_row/colums_names设置是否显示列名和行名column/row_names_side设置列名和行名的位置column/row_names_gp设置列名和行名的自定义column/row_names_centered设置名称是否中心化column/row_names_rot设置名称的角度column/row_labels设置重新定义名称column_names_max_height和row_names_max_width设置列名和行名的最大空间。默认的都是6cm。如果名称太长可以通过这个来设置。
row_labels = structure(paste0(letters[1:24], 1:24), names = paste0("row", 1:24))
Heatmap(mat, show_row_names = T, column_names_side = "top",
row_names_gp = gpar(fontsize = 20, col = c(rep("red", 10), rep("blue", 8))), column_names_centered = TRUE, column_names_rot = 45, row_labels = row_labels[rownames(mat)])

热图的分割
热图的分割主要包括多种方式
按照k-means方法来分割。可以通过
column/row_km参数进行实现。按照固定的分类来进行分割,可以通过
row/column_split参数来实现 另外可以通过row_gap来设置分割的距离。
###k-means方式
Heatmap(mat, name = "mat", row_km = 2, column_km = 3)
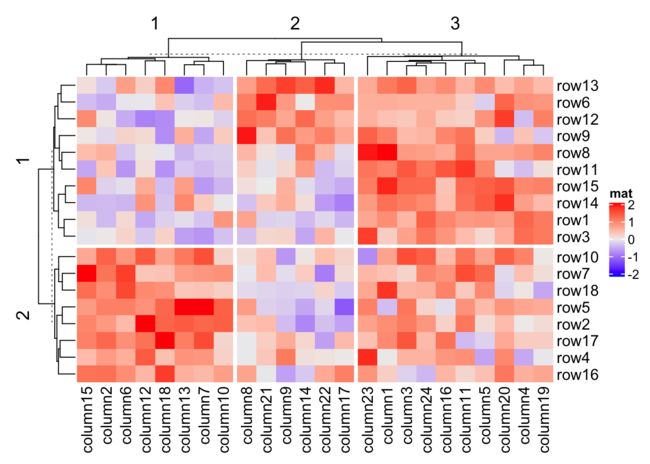
### 特定的分组
Heatmap(mat, name = "mat", row_split = data.frame(rep(c("A", "B"), 9), rep(c("C", "D"), each = 9)), column_split = factor(rep(c("C", "D"), 12)))

Heatmap(mat, name = "mat", row_km = 3, row_gap = unit(5, "mm"))
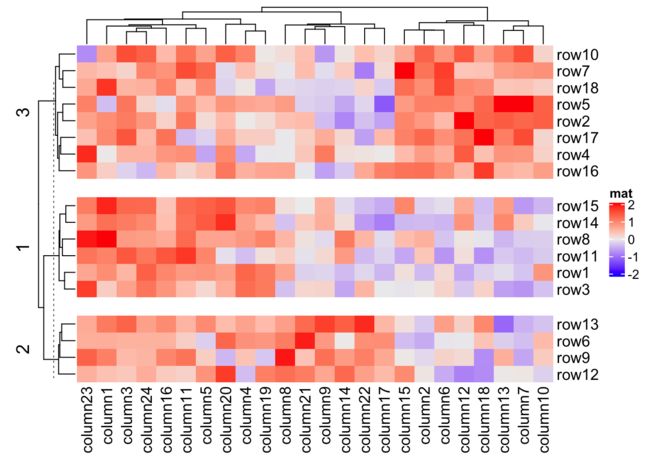
热图本身的自定义
一般的热图上都是方块形的颜色的变化。我们可以通过cell_fun参数来对热图本身进行自定义。这个参数本质是一个for循环的函数。这个接受7个参数分别是: - j矩阵当中行的索引。 - i矩阵当中的列的索引。 - x在热图当中测量点的X坐标 - y在热图当中测量点单元格Y的坐标 - width 单元格的宽度。默认值是unit(1/nrow(sub_mat), "npc") - height单元格的高度。默认值是unit(1/nrow(sub_mat), "npc") - fill单元格的颜色。 通过一个简单的例子我们来详细说一下具体的含义
small_mat = mat[1:9, 1:9]
small_mat1 = cut(small_mat, breaks = c(-Inf, 0.5,1,Inf),
labels = c("**","*","."))
small_mat1 = matrix(small_mat1, ncol = 9)
col_fun = colorRamp2(c(-2, 0, 2), c("green", "white", "red"))
p1 <- Heatmap(small_mat)
p2 <- Heatmap(small_mat, name = "mat", col = col_fun,
cell_fun = function(j, i, x, y, width, height, fill) {
grid.text(small_mat1[i, j], x, y, gp = gpar(fontsize = 10))
})
p1 + p2
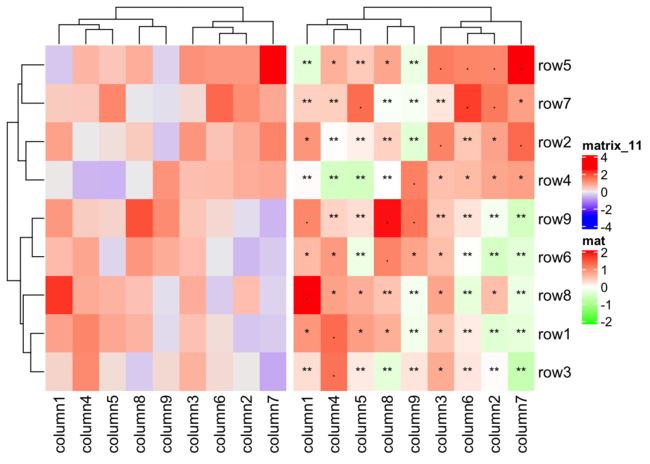
上述两个热图的区别就在于增加了一个
cell_fun参数。通过比较两个热图可以明白cell_fun本质上就是给单元格自定义。这个例子当中,通过自定义函数,我们取small_mat1的数据放到热图上。放的位置及基于i,j,x,y来决定的。这个例子当中四个参数都没有变化。所以默认热图的数据集和自定义的数据集和变化是一样的。即:在small_data[1,1]的位置放置small_data1[1,1]的内容。以此类推。
由于是函数嘛,所以可以更加的自定义数据了。比如加入if来筛选数据
Heatmap(small_mat, name = "mat", col = col_fun,
cell_fun = function(j, i, x, y, width, height, fill) {
if(small_mat[i, j] > 0)
grid.text(sprintf("%.1f", small_mat[i, j]), x, y, gp = gpar(fontsize = 10))
})

同样的由于自定义绘图也是基于grid系统的。所以grid系统另外一些绘图参数也是可以使用的。所以我们可以隐藏默认的热图显示来定义不同的图形。
cor_mat = cor(small_mat)
od = hclust(dist(cor_mat))$order
cor_mat = cor_mat[od, od]
nm = rownames(cor_mat)
col_fun = circlize::colorRamp2(c(-1, 0, 1), c("green", "white", "red"))
# `col = col_fun` here is used to generate the legend
Heatmap(cor_mat, name = "correlation", col = col_fun, rect_gp = gpar(type = "none"),
cell_fun = function(j, i, x, y, width, height, fill) {
grid.rect(x = x, y = y, width = width, height = height,
gp = gpar(col = "grey", fill = NA))
if(i == j) {
grid.text(nm[i], x = x, y = y)
} else if(i > j) {
grid.circle(x = x, y = y, r = abs(cor_mat[i, j])/2 * min(unit.c(width, height)),
gp = gpar(fill = col_fun(cor_mat[i, j]), col = NA))
} else {
grid.text(sprintf("%.1f", cor_mat[i, j]), x, y, gp = gpar(fontsize = 10))
}
}, cluster_rows = FALSE, cluster_columns = FALSE,
show_row_names = FALSE, show_column_names = FALSE)

热图的大小
我们可以通过width和height来调整整体图片的大小。通过heatmap_width以及heatmap_height来调整热图部分的大小。
p1 <- Heatmap(mat, name = "mat1", width = unit(8, "cm"), height = unit(8, "cm"))
p2 <- Heatmap(mat, name = "mat2", heatmap_width = unit(8, "cm"), heatmap_height = unit(8, "cm"))
p1 + p2
