【JVM进阶之路】十四:类加载器和类加载机制
在上一章里,我们已经学习了类加载的过程,我们知道在加载阶段需要”通过一个类的全限定名来获取描述该类的二进制字节流“,而来完成这个工作的就是类加载器(Class Loader)。
1、类与类加载器
类加载器只用于实现类的加载动作。
但对于任意一个类,都必须由加载它的类加载器和这个类本身一起共同确立其在Java虚拟机中的唯一性,每 一个类加载器,都拥有一个独立的类名称空间。
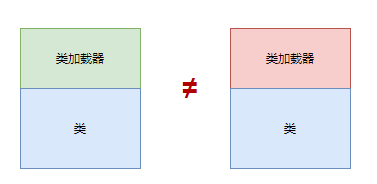
这句话可以表达得更通俗一些:比较两个类是否“相等”,只有在这两个类是由同一个类加载器加载的前提下才有意义,否则,即使这两个类来源于同一个Class文件,被同一个Java虚拟机加载,只要加载它们的类加载器不同,那这两个类就必定不相等。
如下演示了不同的类加载器对instanceof关键字运算的结果的影响。
public class ClassLoaderTest {
public static void main(String[] args) throws Exception {
//自定义一个简单的类加载器
ClassLoader myLoader = new ClassLoader() {
@Override
//加载类方法
public Class<?> loadClass(String name) throws ClassNotFoundException {
try {
//获取文件名
String fileName = name.substring(name.lastIndexOf(".") + 1) + ".class";
//加载输入流
InputStream is = getClass().getResourceAsStream(fileName);
//使用父类加载
if (is == null) {
return super.loadClass(name);
}
byte[] b = new byte[is.available()];
is.read(b);
//从流中转化类的实例
return defineClass(name, b, 0, b.length);
} catch (IOException e) {
throw new ClassNotFoundException(name);
}
}
};
//使用自己实现的类加载器加载
Object obj = myLoader.loadClass("cn.fighter3.loader.ClassLoaderTest").newInstance();
System.out.println(obj.getClass());
//实例判断
System.out.println(obj instanceof cn.fighter3.loader.ClassLoaderTest);
}
}
运行结果:

在代码里定义了一个简单的类加载器,使用这个类加载器去加载cn.fighter3.loader.ClassLoaderTest类并创建实例,去做类型检查的时候,发现结果是false。
2、双亲委派模型
从Java虚拟机的角度来看,只存在两种不同的类加载器:一种是启动类加载器(Bootstrap ClassLoader),这个类加载器使用C++语言实现,是虚拟机自身的一部分;另外一种就是其他所有的类加载器,这些类加载器都由Java语言实现,独立存在于虚拟机外部,并且全都继承自抽象类 java.lang.ClassLoader。
站在Java开发人员的角度来看,类加载器就应当划分得更细致一些。自JDK 1.2以来,Java一直保持着三层类加载器、双亲委派的类加载架构。

双亲委派模型如上图:
- 启动类加载器(Bootstrap Class Loader):负责加载存放在
\lib目录,或者被-Xbootclasspath参数所指定的路径中存放的,能被Java虚拟机能够识别的(按照文件名识别,如rt.jar、tools.jar,名字不符合的类库即使放在lib目录中也不会被加载)类。 - 扩展类加载器(Extension Class Loader):负责加载
\lib\ext目录中,或者被java.ext.dirs系统变量所指定的路径中所有的类库。 - 应用程序类加载器(Application Class Loader):负责加载用户类路径 (ClassPath)上所有的类库,如果没有自定义类加载器,一般情况下这个加载器就是程序中默认的类加载器。
用户还可以加入自定义的类加载器器来进行扩展。
双亲委派模型的工作过程:如果一个类加载器收到了类加载的请求,它首先不会自己去尝试加载这个类,而是把这个请求委派给父类加载器去完成,每一个层次的类加载器都是如此,因此所有的加载请求最终都应该传送到最顶层的启动类加载器中,只有当父加载器反馈自己无法完成这个加载请求时,子加载器才会尝试自己去完成加载。

为什么要用双亲委派机制呢?
答案是为了保证应用程序的稳定有序。
例如类java.lang.Object,它存放在rt.jar之中,通过双亲委派机制,保证最终都是委派给处于模型最顶端的启动类加载器进行加载,保证Object的一致。反之,都由各个类加载器自行去加载的话,如果用户自己也编写了一个名为java.lang.Object的类,并放在程序的 ClassPath中,那系统中就会出现多个不同的Object类。
双亲委派模型的代码实现非常简单,在java.lang.ClassLoader.java中有一个 loadClass方法:
protected Class<?> loadClass(String name, boolean resolve)
throws ClassNotFoundException
{
synchronized (getClassLoadingLock(name)) {
// 首先,判断类是否被加载过
Class<?> c = findLoadedClass(name);
if (c == null) {
long t0 = System.nanoTime();
try {
if (parent != null) {
c = parent.loadClass(name, false);
} else {
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
// 如果父类加载器抛出ClassNotFoundException
// 说明父类加载器无法完成加载请求
}
if (c == null) {
// 在父类加载器无法加载时
// 再调用本身的findClass方法来进行类加载
long t1 = System.nanoTime();
c = findClass(name);
// this is the defining class loader; record the stats
sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0);
sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);
sun.misc.PerfCounter.getFindClasses().increment();
}
}
if (resolve) {
resolveClass(c);
}
return c;
}
}
3、破坏双亲委派模型
双亲委派机制在历史上主要有三次破坏:
第一次破坏
双亲委派模型的第一次“被破坏”其实发生在双亲委派模型出现之前——即JDK 1.2面世以前的“远古”时代。
由于双亲委派模型在JDK 1.2之后才被引入,但是类加载器的概念和抽象类 java.lang.ClassLoader则在Java的第一个版本中就已经存在,为了向下兼容旧代码,所以无法以技术手段避免loadClass()被子类覆盖的可能性,只能在JDK 1.2之后的java.lang.ClassLoader中添加一个新的 protected方法findClass(),并引导用户编写的类加载逻辑时尽可能去重写这个方法,而不是在 loadClass()中编写代码。

第二次破坏
双亲委派模型的第二次“被破坏”是由这个模型自身的缺陷导致的,如果有基础类型又要调用回用户的代码,那该怎么办呢?
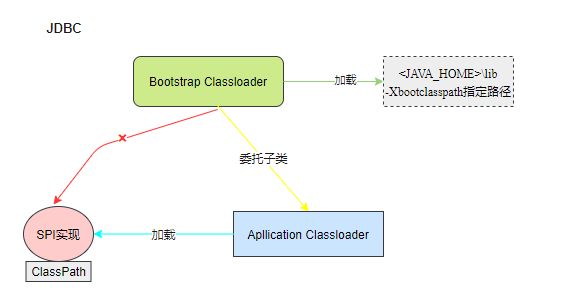
例如我们比较熟悉的JDBC:
各个厂商各有不同的JDBC的实现,Java在核心包\lib里定义了对应的SPI,那么这个就毫无疑问由启动类加载器加载器加载。
但是各个厂商的实现,是没办法放在核心包里的,只能放在classpath里,只能被应用类加载器加载。那么,问题来了,启动类加载器它就加载不到厂商提供的SPI服务代码。
为了解决这个我呢提,引入了一个不太优雅的设计:线程上下文类加载器 (Thread Context ClassLoader)。这个类加载器可以通过java.lang.Thread类的setContext-ClassLoader()方法进行设置,如果创建线程时还未设置,它将会从父线程中继承一个,如果在应用程序的全局范围内都没有设置过的话,那这个类加载器默认就是应用程序类加载器。
JNDI服务使用这个线程上下文类加载器去加载所需的SPI服务代码,这是一种父类加载器去请求子类加载器完成类加载的行为。
第三次破坏
双亲委派模型的第三次“被破坏”是由于用户对程序动态性的追求而导致的,例如代码热替换(Hot Swap)、模块热部署(Hot Deployment)等。
OSGi实现模块化热部署的关键是它自定义的类加载器机制的实现,每一个程序模块(OSGi中称为 Bundle)都有一个自己的类加载器,当需要更换一个Bundle时,就把Bundle连同类加载器一起换掉以实现代码的热替换。在OSGi环境下,类加载器不再双亲委派模型推荐的树状结构,而是进一步发展为更加复杂的网状结构。
“简单的事情重复做,重复的事情认真做,认真的事情有创造性地做!”——
我是三分恶,可以叫我老三/三分/三哥/三子,一个能文能武的全栈开发,咱们下期见!
参考:
【1】:《深入理解Java虚拟机:JVM高级特性与最佳实践(第3版) 》
【4】:读者美团五面:Java历史上有三次破坏双亲委派模型,是哪三次?