Vitalik:Rollup 不完全指南
原文:An Incomplete Guide to Rollups
作者:Vitalik
译者:阿树
????️ 字数:5349 | ???? 阅读时间:18m39s
Rollup 最近在 Ethereum 社区风靡一时,有望在未来成为 Ethereum 的主要扩容解决方案。但这项技术到底是什么样的呢?它可以给我们带来什么变化?我们如何使用这项技术?这篇文章将试图回答其中的一些关键问题。
背景:什么是 Layer1 和 Layer2 扩容?
目前主要有两种区块链扩容方式。
首先,你可以直接提高区块链交易吞吐量,但这类技术主要挑战为「当区块容量越大时,区块链将更难以验证,而且很可能逐渐变得更中心化」。为了避免这样的风险,开发者可以提高客户端软件的效率(译者注:比如 Turbo Geth),或者使用 Sharding 技术让构建和验证工作分散到许多节点上,目前 Ethereum 准备借助 Eth2 升级引入 Sharding 技术。
其次,你也可以改变使用区块链的方式。用户不必将所有交易放在区块链上,而是可以通过 Layer2 协议在链下执行大部分交易。即链上的智能合约只需执行两个任务:处理存取款和验证链下交易的有效性。由此减轻链上负担,提高交易处理效率。
State channels vs plasma vs rollups
目前主要有三种 Layer2 扩容方案:State channels、Plasma 和 Rollups,这三种各有优劣。
译者注:译文中省略 State channels 和 Plasma 科普内容,主要讲述 Rollups 部分。
术语说明
Batch:批处理交易,指将 Layer2 交易批量打包并提交到 Layer1 的 Rollup 合约。
Sequencer:排序者,指在 Layer2 上打包排序交易的角色,类似 Layer1 的矿工。
State root:状态根,指 Layer2 上所有状态(账户余额、合约代码等)通过 Merkle Tree 生成的哈希值。
Rollups
参考:Optimistic rollups 和 ZK rollups。
Plasma 和 State Channels 是「完全」的 Layer2 方案,因为它们试图将数据和计算都转移至链下。然而,由于存在「数据可用性的博弈问题」,意味着这两种方案不可能安全地满足所有应用场景。
Plasma 和 State Channels 通过依赖所属权的 owner(译者注:因为提交欺诈性证明需要证明资产所属权,这也是为什么 Plasma 采用 UTXO 方案,所以无法解决像 Uniswap 资产所属权场景的问题。感谢 Chih Cheng Liang 指点)来解决该问题,但这使它们无法完全通用化。
另一方面,Rollups 是一种「混合」的 Layer2 方案。Rollups 将计算(以及状态存储)转移至链下,但同时将每笔交易的部分数据保留在链上。
为了提高效率,他们使用了不少 fancy 的压缩技巧,尽可能地使用「计算」代替「数据」。其结果是系统的扩容仍然受限于底层区块链的数据带宽,但效率是可观的:Ethereum ERC20 代币转账成本约为 45,000 gas,而 Rollup 中的 ERC20 代币转账仅使用 16 字节的链上空间,成本低于 300 gas。
事实上,数据上链是关键(注意:将数据放在 IPFS 上是行不通的,因为 IPFS 不提供任何给定数据是否可用的共识,所以数据必须放到区块链上)。将数据放在链上并获得共识,如果任何人愿意,他们可以在本地处理 rollup 中的所有操作,从而允许他们监测欺诈交易,请求提款,或亲自生成 transaction batches。
因为没有数据可用性问题,所以恶意或离线运营者所造成的损失会更少(比如他们不能造成 1 周的延迟),从而为谁有权发布 batches 打开了更大的设计空间,并简化 rollups 系统。最重要的是,没有数据可用性问题也意味着不再需要将资产映射到 owners。
这是 Ethereum 社区对 rollups 比以往的 Layer2 扩容方案更兴奋的关键原因:Rollups 是完全通用的,我们甚至可以在 rollup 内运行一个 EVM,使得现有的 Ethereum 应用不必编写过多新的代码就可以迁移到 rollups 上。
那么 Rollup 到底是如何工作的呢?
链上会有一个智能合约维护着 state root:rollup 状态的 Merkle root(即 rollup 内部的账户余额、合约代码等信息的 Merkle 化)。
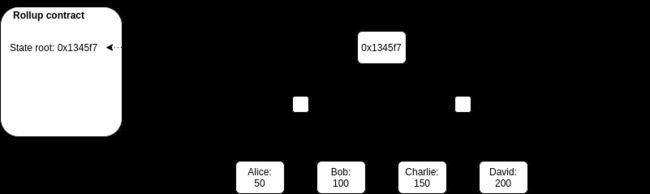
任何人都可以发布一笔 batch 交易,这是一个高度压缩的交易集合,包含旧的 state root 和新的 state root。合约会检查 batch 中的旧 state root 是否匹配当前的 state root,如果匹配,则将 state root 更新到新的 state root。
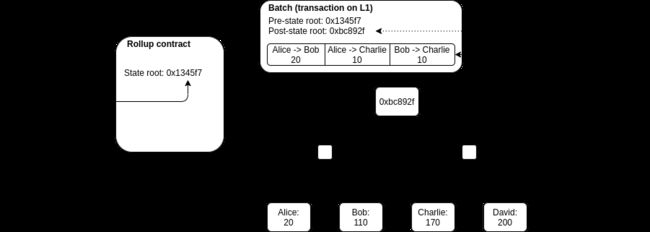
为了支持存款和提款,我们增加了交易的能力,其输入或输出是「外部」的 rollup 状态。如果一个 batch 来自外部的输入,那么提交该 batch 的交易也需要将这些资产转移到 rollup 合约中。如果一个 batch 有对外的输出,那么在处理该 batch 时,智能合约将会执行「提现」操作。
这一切就这么简单! 除了一个主要的细节:如何知道 batch 中的 post-state roots 是正确的呢? 如果有人可以用任意 post-state root 提交一个 batch 而没有任何惩罚,他们就可以直接将 rollup 内的全部资产转给自己。这个问题有两种截然不同的解决思路,从而衍生出两种「口味」的 rollup 方案。
Optimistic rollups VS ZK rollups
以下是这两种「口味」的 rollups 方案描述:
Optimistic rollups,采用欺诈性证明:rollup 合约会跟踪历史的 state roots 和每一个 batch 的哈希值。如果有人发现某个 batch 的 post-state root 不正确,那么他们可以向合约提交证明,证明该 batch 计算错误。合约验证该证明有效后,会对该 batch 和之后的所有 batch 进行回滚。
ZK rollups,采用有效性证明:每一个 batch 都包含一个称为 ZK-SNARK 的密码学证明(例如采用 PLONK 协议),它可以证明 post-state root 是执行该 batch 的正确结果。无论计算量有多大,合约都可以迅速地在链上验证证明。
但两种「口味」的 rollup 之间有着复杂的权衡:
方案权衡
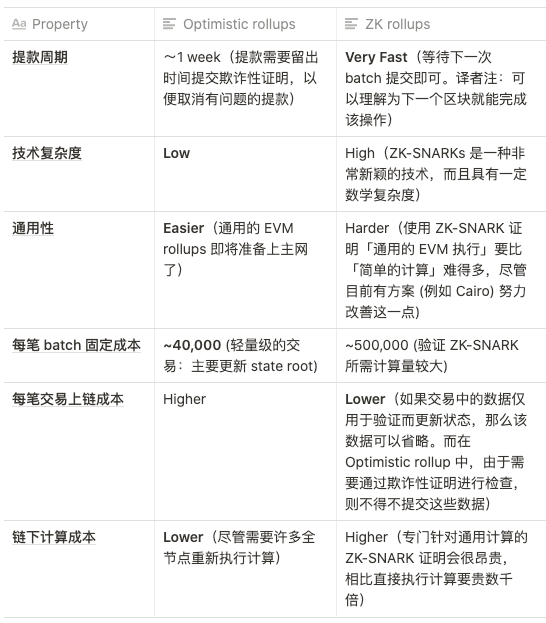
总的来说,我的观点是:
短期内,Optimistic rollups 很可能在通用的 EVM 计算中胜出,而 ZK rollups 则可能在简单的支付、交易和其他特定应用场景中胜出,但最终从中长期来看,随着 ZK-SNARK 技术的改进,ZK rollups 将在所有场景中胜出。
欺诈性证明剖析
Optimistic rollup 的安全性主要取决于:如果有人将一个无效 batch 发布到 rollup 合约中,那么保持跟踪链上信息并发现欺诈的任何人都可以发布欺诈性证明,向合约证明该 batch 无效并回滚。

如图所示,声称某 batch 无效的欺诈性证明将会包含这些绿色数据:该 batch 本身(对照存储在链上的哈希值核对)和 Merkle tree 的部分内容,从而证明该 batch 读取或修改特定账户。
而该树中的黄色节点可以从绿色的节点重建,所以不必提供。这些数据足以执行该 batch 并计算 post-state root(注:类似 stateless clients 验证单个区块的方式)。如果计算出的 post-state root 和该 batch 中提供的 post-state root 不一样,那么说明该 batch 具有欺诈性。
如果一个 batch 存在错误,但之前所有的 batches 都是正确的,那么就可以创建一个欺诈性证明以表示该 batch 是错误的。
请注意对旧的 batches 声称无效的处理:如果存在多笔无效 batches 提交到 rollup 中,那么最好尽量证明最早无效的 batch。当然,如果一个 batch 是正确的,那么永远不可能创建一个欺诈性证明以表示其无效。
Rollups 是如何压缩数据的?
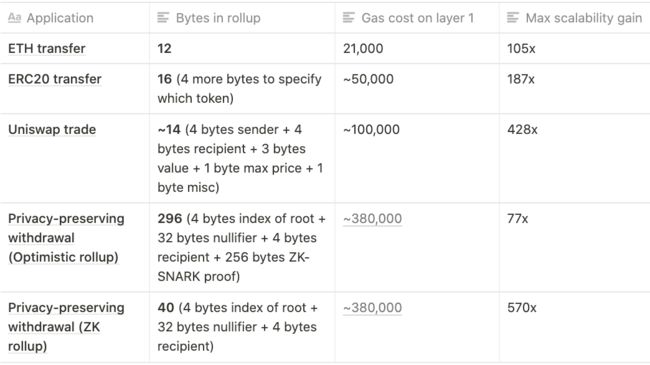
一笔简单的 Ethereum 交易(比如发送 ETH)通常消耗约 110 字节。然而,在 Rollup 上发送 ETH 仅仅消耗约 12 字节。
字节消耗对比
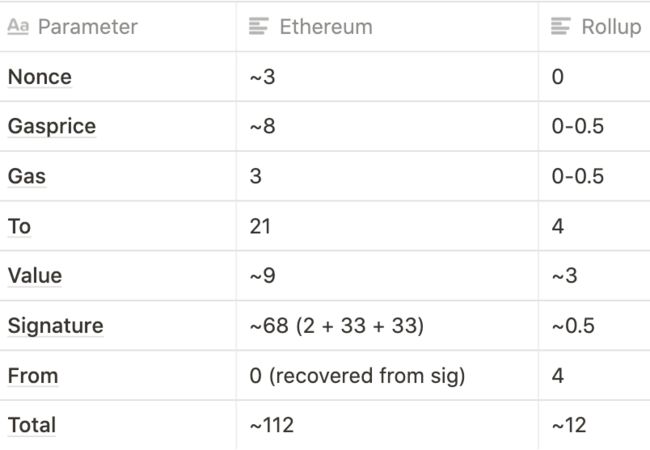
为了达到这样的压缩效果,一方面是采用了更简单高级编码,而目前 Ethereum 的 RLP 在每个值的长度上都浪费了 1 字节。另一方面,还有一些巧妙的压缩技巧:
Nonce:该参数的目的是为了防止「重放」。如果账户的当前 nonce 是 5,那么该账户的下一笔交易必须使用 nonce 5,但一旦交易被处理,那么该账户中的 nonce 就会被递增到 6,这样采用 nonce 5 的交易就不会被执行。在 rollup 中,我们可以完全省略 nonce,因为我们只是从 pre-state 中恢复 nonce。同时由于签名会采用最新的 nonce 进行检查,如果有人试图使用旧的 nonce 重放交易,那么签名将无法通过验证。
Gasprice:我们可以允许用户使用固定范围的 gasprices 进行支付,例如 2 的 16 次幂(译者注:主要为了节省字节)。或者,我们也可以在每笔 batch 中收取固定费用,甚至可以将 gas 支付完全移到 rollup 协议之外,让交易者通过特定渠道向 batch 创建者支付费用。
Gas:我们同样也可以将 gas 设置为 2 的多次幂。另外,我们也可以在 batch 层面设置 gas 限制。
To:我们可以使用「索引」来代替 20 字节的地址(例如:一个地址是「树」中的第 4,527 个地址,我们就可以用索引 4,527 来表示它,同时我们也会在状态中添加一个子树来存储索引到地址的映射)。
Value:我们可以用科学计数法存储 value。在大多数情况下,转账仅需 1 ~ 3 有效位。
Signature:我们可以使用 BLS 聚合签名,它允许许多签名聚合成一个约 32 - 96 字节的签名(取决于协议)。然后,这个签名可以一次性对整个消息集和发送者进行 batch 检查。表中的 ~ 0.5 表示一个区块中可验证的聚合签名的数量是有限制的,因为它需要在一次欺诈证明中验证签名。
ZK rollups 特有的一个重要压缩技巧:如果交易的一部分仅用于验证,并与计算状态更新无关,那么这部分可以省略。这在 Optimistic rollup 中是做不到的,因为该数据仍然需要包含在链上,以防将来欺诈性证明检查所需,而在 ZK rollup 中,证明数据正确性的 SNARK 已经提供了任何验证所需的数据。
一个重要的例子是隐私保护 rollups:在 Optimistic rollup 中,每笔交易中 ~ 500 字节用于隐私的 ZK-SNARK 需要上链,而在 ZK rollup 中,覆盖整个 batch 的 ZK-SNARK 已经足以表明「内部」的所有 ZK-SNARKs 是有效的。
这些压缩技巧是 rollup 扩容的关键,如果没有这些技巧,rollup 或许只能在基础链的扩容上有大约 10 倍的提升(在一些特定的计算量大的应用中,简单的 rollup 也已经很强大),但有了这些压缩技巧,几乎所有应用的扩容系数都可以超过 100 倍。
谁可以提交 batch?
关于哪些人可以在 Optimistic rollup 或 ZK rollup 中提交 batch 的问题存在许多流派。一般来说,大家都认为提交 batch 的用户必须先交纳一大笔押金,如果该用户提交欺诈性的 batch(例如采用一个无效的 state root),那么这笔押金的一部分将被烧掉,另一部分作为奖励给到提交欺诈性证明的用户。但除此之外,还存在许多可能性:
Total anarchy:任何人都可以在任何时候提交 batch。这是最简单的方法,但它有一些严重的缺点,比如存在这样的问题:多个参与者同时生成并试图提交 batch,而其中仅有一个 batch 可以成功被收录。这将导致大量的浪费,比如没有意义的生成 batch 证明或者提交 batch 到链上。
中心化的 Sequencer:通过 Sequencer 这样的角色提交 batch(除了提现操作:首先由用户自己提交提现请求,如果 Sequencer 在下一个 batch 中没有处理该提现交易,那么用户可以亲自提交一个 batch 处理提现)。这是最「高效」的,但它依赖于一个中心化的角色。
Sequencer 拍卖:通过拍卖(比如每天)来决定谁有权利成为第二天的 Sequencer。这种方案的优点是可以筹集资金,而这些资金可以通过 rollup 的 DAO 来分配(参考:MEV 拍卖)。
从 PoS 集合中随机选择:任何人都可以将 ETH(或者 rollup 协议的代币)存入 rollup 合约中,每一个 batch 的 sequencer 都会从其中一个存款人中随机选择,被选中的概率与存款金额成正比。这种方案的主要缺点是大量资产被锁定,导致资金效率低。
DPoS 投票:Sequencer 通过拍卖选中,但如果他们表现不佳,那么代币持有者可以投票将其踢出,并举行新的拍卖来替代他们。
改进提交 batch 和 state root 的方式
目前一些正在开发的 rollup 方案采用的是 “split batch” 模式,即提交 Layer2 batch 的动作和提交一个 state root 的动作分开执行,这会有一些关键优势:
你可以允许许多 sequencers 并行发布 batch,以提高抗审查能力,而不用担心一些 batch 会因为其他 batch 已经被打包而无效。
如果一个 state root 存在欺诈,你不需要回滚所有 batch,仅恢复该 state root 即可,并等待有人为该 batch 提供新的 state root。这样可以更好地保障交易发送者的交易不会被回滚。
总的来说,这是一个相当复杂的技术组合,它们试图在涉及效率、简单性、抗审查和其他目标的复杂权衡中获得平衡。但现在谈哪种组合最有效还为时过早,而时间会证明一切。
Rollups 将会带来多大的扩容?
目前 Ethereum 的 gas limit 是 1,250 万,交易中每个字节的数据需要消耗 16 gas。那么如果一个区块仅包含一个 batch(我们假设使用 ZK rollup,将会消耗 50 万 gas 用于验证证明),那么该 batch 会有(1,200 万 / 16)= 75 万字节。如上图所示,每一位用户转账 ETH 仅消耗 12 字节,那么也就是说,该 batch 最多可以包含 62,500 笔交易。
在平均区块时间为 13 秒的情况下,这相当于达到约 4,807 TPS(对比 Ethereum 目前 ETH 转账的 1,250万 / 21,000 / 13 约为 45 TPS)。
部分用例扩容提升规模
那么扩容上限可以这么计算:
(L1 gas cost) / (bytes in rollup * 16) * 12million / 12.5million
现在值得注意的是这些数字还是过于乐观,原因有几个:
首先,最重要的是一个区块几乎永远不会仅包含一个 batch,因为将可能会存在多个 rollup 方案同时运作。第二,存款和提款将持续存在。第三,短期内使用量会很低,所以固定成本成为主要消耗。但即使将这些因素考虑在内,预计扩容规模也会超过 100 倍。
现在,如果我们想要超过 ~ 1,000 - 4,000 TPS,该怎么办呢?这就是 ETH 数据分片的意义所在,sharding 建议每 12 秒开辟一个 16MB 的空间,这个空间可以被任何数据填满,系统保证对这些数据的可用性达成共识,而这些数据空间可以被 rollup 使用。
这个约 1,398 kB/s 的数据量比当前 Ethereum 60 kB/s 提高了 23 倍,从长远来看,数据容量有望进一步增长。因此,使用 Eth2 分片数据的 rollup 可以处理高达约 100k TPS,未来甚至会更多。
Rollup 还有哪些尚未解决的挑战?
虽然现在 Rollup 的基本概念已经被大家所熟知,我们也很确认它们从根本上是可行的、安全的,以及已有多个 rollup 方案被部署到主网上,但 rollup 的设计仍然存在许多地方没有被很好地探索,将 Ethereum 生态系统的大部分内容完全迁移到 rollup 上以利用其扩容能力也存在不少挑战:
User and ecosystem onboarding - 使用 rollups 的应用不多,用户对 rollups 也不熟悉,目前很少有钱包开始整合 rollups,而商家和慈善机构还不接受它们用于支付。
Cross-rollup transactions - 有效地将资产和数据 (例如 oracle 输出) 从一个 rollup 转移到另一个 rollup 中,而不会产生经过 Layer1 的费用。
Auditing incentives - 如何最大限度地提高至少一个诚实节点会真正全面验证一个 Optimistic rollup 的概率,以便出错时他们会发布欺诈性证明。对于小规模的 rollup(几百个 TPS 以下)来说,这不是一个重要的问题,可以简单地借助利他主义,但对于更大规模的 rollup 来说,需要更严谨地推理这个问题。
Exploring the design space in between plasma and rollups - 是否存在一些方法可以将状态更新的相关数据放在链上,而不是所有的数据。
Maximizing security of pre-confirmations - 许多 rollup 为了更快的用户体验,提供了一个「预确认」的概念,即 sequencer 立即给予一个承诺,交易将被包含在下一个 batch 中,如果他们食言,sequencer 的押金将被销毁。但这种方案的经济安全性是有限的,因为可能同时向许多用户做出承诺,这种机制能否获得改进?
Improving speed of response to absent sequencers - 如果一个 rollup 的 sequencer 突然下线,那么快速和经济地从这种情况中恢复过来将是非常有价值的:要么快速且经济地大规模退出到另一个 rollup,要么更换 sequencer。
Efficient ZK-VM - 生成通用 EVM 代码的 ZK-SNARK 证明(或者将现有的智能合约编译适配到其他 VM)可以被正确执行,并且有一个明确结果。
结论
Rollups 是一种强大的 Layer2 扩容范式,预计将成为 Ethereum 短期和中期(甚至长期)扩容的基石。我们已经看到了 Ethereum 社区对此感到大大的兴奋,因为这与之前的 Layer2 扩容方案不同,它们可以支持通用的 EVM 代码,允许现有的智能合约轻松迁移。
这是通过一个关键的妥协来实现的:放弃将数据和计算完全放在链下,而是将每笔交易的少量数据留在链上。
Rollups 方案有很多种,在设计空间上会有很多选择:可以采用欺诈性证明的 Optimistic rollup,或者采用有效性证明的 ZK rollup(又名 ZK-SNARKs)。Sequencer(可以将交易 batch 发布到链上的用户)可以是一个中心化的角色,也可以是一个去中心化的角色,或者是介于两者之间的其他选择。
总的来说,Rollup 仍然是一项早期阶段的技术,一切仍在迅速发展,特别是 Loopring,ZKSync 和 DeversiFi 已经运作了几个月。
期待在未来的几年内,Rollup 领域会出现更多令人兴奋的工作成果。