1. 简述
- Hadoop:利用分布式集群实现 大数据文件存储系统DFS 和 MapReduce计算引擎。
- HBase:基于Hadoop的DFS系统,实现 非关系型 的 K-V键值对 形式存储的 分布式数据库。
- Flink:基于Hadoop的DFS系统或实时输入流,实现 批量作业处理 和 流式数据处理 的 分布式计算引擎,支持 实时处理。
三者关系如下图所示:
[图片上传失败...(image-e16016-1568608205958)]
注意:由于hadoop、hbase、flink三者之间兼容问题,安装前要先查好版本匹配情况,确定好匹配版本后再安装,本文选择版本情况:hadoop2.8.5 + hbase2.1.6 + flink1.7.2。
本文是在CentOs7系统上,安装部署Hadoop2.8.5 + HBase2.1.6 + Flink1.7.2,构建大数据分部署存储和计算引擎的集群系统。
2 JDK安装
略
3 SSH免密登录配置
在4台CentOs7机器上配置相互之间的SSH免密登录。
略
4 zookeeper安装和验证
在4台CentOs7机器上安装zookeeper,可以直接使用yum安装。
安装完后,配置环境变量、zoo.cfg配置文件、myid配置文件即可。
略
5 Hadoop安装和验证
5.1 部署规划
共4台CentOs7环境,规划如下表所示:
| 机器名 | 安装软件 | 进程 | 说明 |
|---|---|---|---|
| hadoop01-namenode | jdk, zookeeper, hadoop, hbase, flink | NameNode, JournalNode, DFSZKFailoverController, ResourceManager | Namenode和ResourceManager控制节点,与hadoop02-namenode机器互为主备 |
| hadoop02-namenode | jdk, zookeeper, hadoop, hbase, flink | NameNode, JournalNode, DFSZKFailoverController, ResourceManager, DataNode, NodeManager | Namenode和ResourceManager控制节点,与hadoop01-namenode机器互为主备;Datanode数据存储节点 |
| hadoop03-datanode | jdk, zookeeper, hadoop, hbase, flink | DataNode, NodeManager | Datanode数据存储节点 |
| hadoop04-datanode | jdk, zookeeper, hadoop, hbase, flink | DataNode, NodeManager | Datanode数据存储节点 |
说明:
- 在hadoop01-namenode和hadoop02-namenode两机器上构建NameNode和ResourceManager的高可用HA,互为主备;
- 在Hadoop02-namenode、hadoop03-datanode、hadoop04-datanode三台机器上做分布式文件存储;
5.2 版本下载和安装
说明:Hadoop版本安装和配置(包括环境变量),仅在其中一台上操作即可。安装和配置完成后,整体拷贝到其他三台机器上。本文中,是在hadoop01-namenode机器上安装和配置hadoop2.8.5版本的,然后使用scp命令拷贝到其他三台机器上。
-
下载Hadoop2.8.5b版本https://hadoop.apache.org/releases.html
可直接在CentOs7环境上使用wget命令下载:wget https://www-us.apache.org/dist/hadoop/common/hadoop-2.8.5/hadoop-2.8.5.tar.gz tar -zxvf ./hadoop-2.8.5.tar.gz -C /hadoop/使用tar命令解压至/hadoop/目录下。
执行效果如下图所示: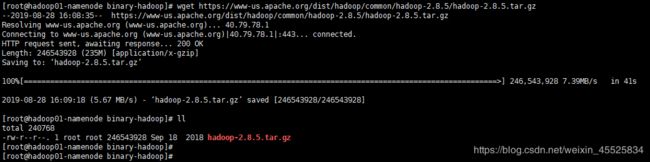 在这里插入图片描述
在这里插入图片描述 -
配置环境变量
vi /etc/profile source /etc/profile/etc/profile环境变量中增加如下
export HADOOP_HOME=/hadoop/hadoop-2.8.5/ export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$HADOOP_HOME/lib:$ZOOKEEPER_HOME/bin命令执行效果图如下所示:
 在这里插入图片描述
在这里插入图片描述
5.3 配置文件修改
-
修改配置文件$HADOOP_HOME/etc/hadoop/core-site.xml
fs.defaultFS hdfs://mycluster hadoop.tmp.dir /hadoop/hadoop-2.8.5/tmp ha.zookeeper.quorum hadoop01-namenode:2181,hadoop02-namenode:2181,hadoop03-datanode:2181,hadoop04-datanode:2181 注意:该配置文件中涉及的/hadoop/hadoop-2.8.5/tmp文件夹要手工创建出来。
-
修改配置文件$HADOOP_HOME/etc/hadoop/hdfs-site.xml
dfs.replication 2 dfs.datanode.data.dir /hadoop/hadoop-2.8.5/data dfs.nameservices mycluster dfs.ha.namenodes.mycluster nn1,nn2 dfs.namenode.rpc-address.mycluster.nn1 hadoop01-namenode:8020 dfs.namenode.rpc-address.mycluster.nn2 hadoop02-namenode:8020 dfs.namenode.http-address.mycluster.nn1 hadoop01-namenode:9870 dfs.namenode.http-address.mycluster.nn2 hadoop02-namenode:9870 dfs.namenode.shared.edits.dir qjournal://hadoop01-namenode:8485;hadoop02-namenode:8485/mycluster dfs.client.failover.proxy.provider.mycluster org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider dfs.ha.fencing.methods sshfence dfs.ha.fencing.ssh.private-key-files /root/.ssh/id_rsa dfs.journalnode.edits.dir /hadoop/hadoop-2.8.5/journalnode dfs.ha.automatic-failover.enabled true dfs.client.failover.proxy.provider.mycluster org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider dfs.ha.fencing.methods sshfence shell(/bin/true) dfs.ha.fencing.ssh.private-key-files /root/.ssh/id_rsa dfs.ha.fencing.ssh.connect-timeout 30000 注意:该配置文件中涉及的/hadoop/hadoop-2.8.5/data、journalnode文件夹要手工创建出来。
-
修改配置文件$HADOOP_HOME/etc/hadoop/mapred-site.xml
mapreduce.framework.name yarn yarn.app.mapreduce.am.env HADOOP_MAPRED_HOME=/hadoop/hadoop-2.8.5 mapreduce.map.env HADOOP_MAPRED_HOME=/hadoop/hadoop-2.8.5 mapreduce.reduce.env HADOOP_MAPRED_HOME=/hadoop/hadoop-2.8.5 mapreduce.application.classpath /hadoop/hadoop-2.8.5/share/hadoop/mapreduce/*, /hadoop/hadoop-2.8.5/share/hadoop/mapreduce/lib/* -
修改配置文件$HADOOP_HOME/etc/hadoop/yarn-site.xml
yarn.resourcemanager.ha.enabled true yarn.nodemanager.aux-services mapreduce_shuffle yarn.resourcemanager.cluster-id yrc yarn.resourcemanager.ha.rm-ids rm1,rm2 yarn.resourcemanager.hostname.rm1 hadoop01-namenode yarn.resourcemanager.hostname.rm2 hadoop02-namenode yarn.resourcemanager.zk-address hadoop01-namenode:2181,hadoop02-namenode:2181,hadoop03-datanode:2181,hadoop04-datanode:2181 yarn.resourcemanager.address.rm1 hadoop01-namenode:8032 yarn.resourcemanager.scheduler.address.rm1 hadoop01-namenode:8030 yarn.resourcemanager.webapp.address.rm1 hadoop01-namenode:8088 yarn.resourcemanager.address.rm2 hadoop02-namenode:8032 yarn.resourcemanager.scheduler.address.rm2 hadoop02-namenode:8030 yarn.resourcemanager.webapp.address.rm2 hadoop02-namenode:8088 yarn.nodemanager.vmem-check-enabled false yarn.nodemanager.resource.cpu-vcores 8 yarn.resourcemanager.ha.automatic-failover.enabled false -
修改配置文件$HADOOP_HOME/etc/hadoop/slaves
hadoop02-namenode hadoop03-datanode hadoop04-datanode -
修改配置文件$HADOOP_HOME/etc/hadoop/yarn-env.sh、hadoop-env.sh
增加下面配置项:export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.222.b10-0.el7_6.x86_64 export YARN_RESOURCEMANAGER_USER=root export HADOOP_SECURE_DN_USER=root export YARN_NODEMANAGER_USER=root
5.4 安装同步到其他三台机器上
-
将环境变量/etc/profile和安装配置好的hadoop2.8.5版本拷贝至其他3台CentOs7环境上:
scp /etc/profile root@hadoop02-namenode:/etc/ scp /etc/profile root@hadoop03-datenode:/etc/ scp /etc/profile root@hadoop04-datenode:/etc/ scp -r /hadoop/hadoop-2.8.5/ root@hadoop02-namenode:/hadoop/ scp -r /hadoop/hadoop-2.8.5/ root@hadoop03-datanode:/hadoop/ scp -r /hadoop/hadoop-2.8.5/ root@hadoop04-datanode:/hadoop/`注意:1. 为集群部署方便,集群中的所有机器环境上,jdk、zookeeper、hadoop软件安装目录要保持一致。
- 环境变量拷贝主其他机器上后,需要在相应机器上执行source命令使之即可生效。`
5.4 启动和验证Hadoop
-
启动zookeeper
在集群全部机器上都启动zookeeper:cd /usr/lib/zookeeper/bin ./zkServer.sh start ./zkServer.sh status命令执行效果如下截图所示:
 在这里插入图片描述
在这里插入图片描述 -
启动JournalNode,对NameNode和ZK进行格式化
A首先,启动JournalNode进程:
JournalNode规划在hadoop01-namenode和hadoop02-namenode上,故需要在这两个节点上都分别启动JournalNode,以便能进行Namenode格式化:cd /hadoop/hadoop-2.8.5/sbin/ ./hadoop-daemon.sh start journalnode如下截图所示:
[图片上传失败...(image-aa6e3b-1568608205959)]
B然后,对Namenode元数据进行格式化:cd /hadoop/hadoop-2.8.5/sbin/ hdfs namenode -format格式化执行过程中,会有两次确认Y/N,全部输入Y回车即可。
注意:namenode格式化在其中一台机器上执行即可,本例中式在hadoop01-namenode机器上执行。执行完成后,在$HADOOP_HOME/tmp命令下生成集群DFS相关标识信息,使用scp命令将该目录拷贝至其他三台机器相同目录下。scp -r /hadoop/hadoop-2.8.5/tmp/ root@hadoop02-namenode:/hadoop/hadoop-2.8.5/ scp -r /hadoop/hadoop-2.8.5/tmp/ root@hadoop03-datanode:/hadoop/hadoop-2.8.5/ scp -r /hadoop/hadoop-2.8.5/tmp/ root@hadoop04-datanode:/hadoop/hadoop-2.8.5/命令执行如下图所示:
 在这里插入图片描述
在这里插入图片描述
C最后,格式化zk:
cd /hadoop/hadoop-2.8.5/sbin/ hdfs zkfc -formatZK注意:本步骤中的对Namenode和ZK格式化,仅在版本安装后操作一次即可,以后正常启动Hadoop时,不要进行此操作,否则会导致之前存储的DFS数据丢失!!!正常使用情况下,只要依次执行start-dfs.sh和start-yarn.sh启动脚本即可。 -
启动并验证分布式文件系统DFS
A首先,启动dfs分布式文件系统cd /hadoop/hadoop-2.8.5/sbin/ ./start-dfs.sh命令执行效果如下截图所示:
 在这里插入图片描述
在这里插入图片描述B然后,访问DFS的web管理页面:http://http://10.141.212.140:9870
 在这里插入图片描述
在这里插入图片描述
 在这里插入图片描述
在这里插入图片描述C最后,使用HDFS命令,验证文件上传、下载、查看等操作:
hdfs dfs -ls hdfs://mycluster/ hdfs dfs -mkdir hdfs://mycluster/data hdfs dfs -ls hdfs://mycluster/ hdfs dfs -put /usr/zhang0908/testhdfs/wordcount/words hdfs://mycluster/data/words hdfs dfs -cat hdfs://mycluster/data/words如下截图所示:
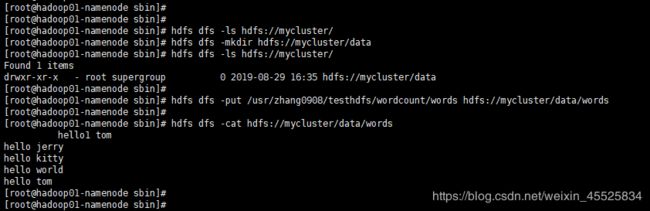 在这里插入图片描述
在这里插入图片描述
至此,Hadoop的分布式文件系统DFS安装和启动成功。
-
启动并验证YARN MapReduce分布式计算引擎
A首先,启动yarn:
cd /hadoop/hadoop-2.8.5/sbin/ ./start-yarn.sh命令执行效果如下图所示:
[图片上传失败...(image-365cf0-1568608205959)]
注意:在hadoop2.8.5版本中,ResourceManager不会自动在所有相关机器上启动,需要到hadoop02-namenode机器上手工执行如上同样的start-yarn.sh脚本来启动ResourceManager任务管理进程。B然后,文Yarn任务管理页面:http://10.141.212.140:8088
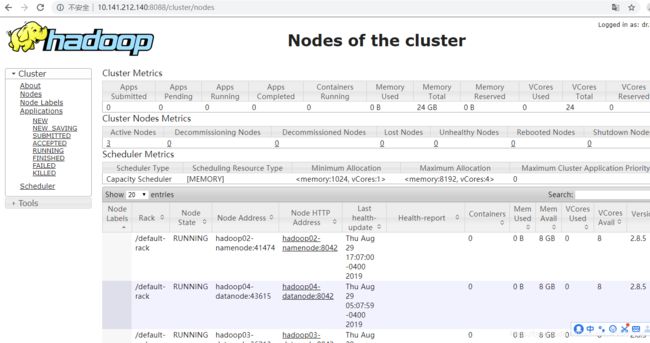 在这里插入图片描述
在这里插入图片描述
C最后,使用HDFS命令,验证Yarn分布式计算:
以Hadoop自带的单词数量统计为例,执行启动单词统计任务的shell脚本如下:hadoop jar ../share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.5.jar wordcount hdfs://mycluster/data/words hdfs://mycluster/data/result/启动和单词统计任务的执行效果过程如下图所示:
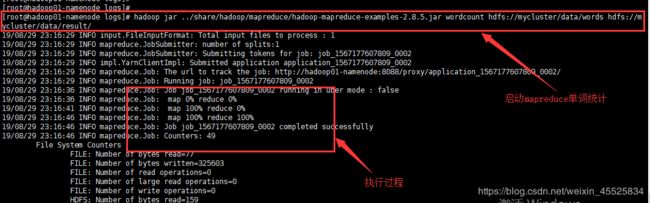 在这里插入图片描述
在这里插入图片描述
查看单词统计任务的执行结果: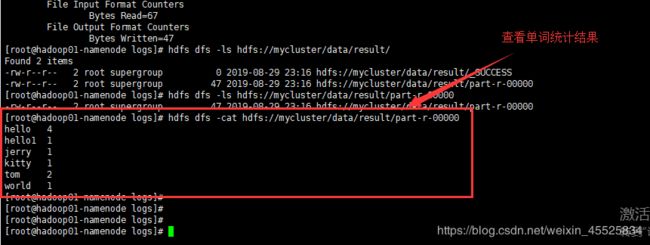 在这里插入图片描述
在这里插入图片描述至此,如果仅仅要用Hadoop的分布式文件系统DFS和Hadoop自带的Yarn-MapReduce分部式计算引擎,到这里就结束了,不需要进行下面的HBase分布式数据库和Flink流式计算引擎的安装操作。
6 HBase安装和验证
HBase分布式数据库,是以Hadoop的分布式文件系统DFS为基础的,所以,使用HBase前提需要安装并启动Hadoop的分布式文件系统DFS。
6.1 部署规划
共4台CentOs7环境,规划如下表所示:
| 机器名 | 安装软件 | 进程 | 说明 |
|---|---|---|---|
| hadoop01-namenode | jdk, zookeeper, hadoop, hbase | QuorumPeerMain, HMaster, | |
| hadoop02-namenode | jdk, zookeeper, hadoop, hbase | QuorumPeerMain, HMaster, HRegionServer | |
| hadoop03-datanode | jdk, zookeeper, hadoop, hbase | QuorumPeerMain, HRegionServer | |
| hadoop04-datanode | jdk, zookeeper, hadoop, hbase | QuorumPeerMain, HRegionServer |
说明:
- 在hadoop01-namenode和hadoop02-namenode两机器上构建HMaster主备高可用HA;
- 在Hadoop02-namenode、hadoop03-datanode、hadoop04-datanode三台机器上做基于DFS的数据存储节点;
6.2 下载及安装
注意,HBase与Hadoop有版本兼容问题,安装前先确认下与之匹配的版本:
http://hbase.apache.org/book.html#configuration
本文选择的是与hadoop2.8.5版本兼容配套的hbase2.1.6版本,
下载地址:https://mirrors.tuna.tsinghua.edu.cn/apache/hbase/2.1.6/hbase-2.1.6-bin.tar.gz
在hadoop01-namenode机器上使用wget命令下载、解压、配置完成后,再使用scp命令整体考本到其他三台机器上即可。
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hbase/2.1.6/hbase-2.1.6-bin.tar.gz
tar -zxvf hbase-2.1.6-bin.tar.gz -C /hadoop/
如下截图所示:
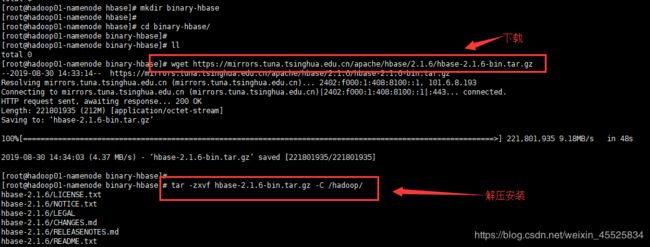
6.3 配置文件修改
-
修改系统环境变量
系统环境变量/etc/profile中增加HBase的根目录:$HBASE_HOME=/hadoop/hbase-2.1.6
。
系统环境变量文件中增加内容,如下截图所示:vi /etc/profile 在这里插入图片描述
在这里插入图片描述使环境变量修改即可生效:
source /etc/profile
-
修改配置文件$HBASE_HOME/conf/hbase-env.sh
增加JAVA_HOME和HBASE_CLASSPATH配置项:
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.222.b10-0.el7_6.x86_64 export HBASE_CLASSPATH=/hadoop/hbase-2.1.6/conf放开并修改HBASE_MANAGES_ZK配置项值为false:不使用HBase自带的zookeeper,而使用外置的zookeeper:
export HBASE_MANAGES_ZK=false -
修改配置文件$HBASE_HOME\conf\hbase-site.xml
增加以下配置:hbase.cluster.distributed true hbase.rootdir hdfs://mycluster/hbase hbase.zookeeper.quorum hadoop02-namenode:2181,hadoop03-datanode:2181,hadoop04-datanode:2181 hbase.unsafe.stream.capability.enforce false -
修改配置文件$HBASE_HOME\conf\regionservers文件
指定分布式数据存储节点机器,类似于hadoop中的datanode概念,数量为基数个。hadoop02-namenode hadoop03-datanode hadoop04-datanodeex -
新建$HBASE_HOME\conf\backup-masters文件
HBase的高可用是建立在zookeeper监控管理上的,新建backup-masters文件,配置备用的HMaster节点:hadoop02-namenode -
其他相关文件拷贝
下面三个文件也需要拷贝下,否则hbase启动会报错:cp $HBASE_HOME/lib/client-facing-thirdparty/htrace-core-3.1.0-incubating.jar $HBASE_HOME/lib/ cp $HADOOP_HOME/etc/hadoop/hdfs-site.xml $HBASE_HOME/conf/ cp $HADOOP_HOME/etc/hadoop/core-site.xml $HBASE_HOME/conf/
6.4 安装同步到其他三台机器上
-
将环境变量/etc/profile和安装配置好的HBase2.1.6版本拷贝至其他3台CentOs7环境上即可,其他三台机器无需逐一安装:
scp /etc/profile root@hadoop02-namenode:/etc/ scp /etc/profile root@hadoop03-datenode:/etc/ scp /etc/profile root@hadoop04-datenode:/etc/ scp -r /hadoop/hbase-2.1.6/ root@hadoop02-namenode:/hadoop/ scp -r /hadoop/hbase-2.1.6/ root@hadoop03-datanode:/hadoop/ scp -r /hadoop/hbase-2.1.6/ root@hadoop04-datanode:/hadoop/`注意:1. 为集群部署方便,集群中的所有机器环境上,jdk、zookeeper、hadoop、hbase软件安装目录要保持一致。
- 环境变量拷贝主其他机器上后,需要在相应机器上执行source命令使之即可生效。`
。
 在这里插入图片描述
在这里插入图片描述
 在这里插入图片描述
在这里插入图片描述
6.5 启动及验证
注意:HBase是在Hadoop的分布式文件系统DFS基础上的,所以需要先启动dfs后,再启动hbase。启动dfs方式参见伤处Hadoop安装章节。
-
启动Hbase
cd /hadoop/hbase-2.1.6/bin/ ./start-hbase.sh。
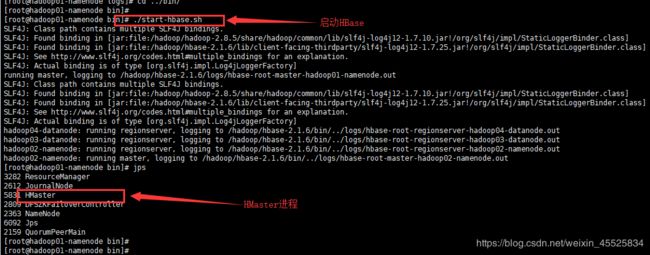 在这里插入图片描述
在这里插入图片描述
hadoop2-namenode机器既是HBase的HMaster备用节点,也是数据存储HRegionServer节点,jps查看进程信息如下:
 在这里插入图片描述
在这里插入图片描述 -
验证HBase----访问HBase的web管理页面
页面查看HBase运行状态:http://hadoop01-namenode:16010/
如下截图所示:
 在这里插入图片描述
在这里插入图片描述 -
验证HBase----命令行操作
输入hbase shell进入hbase 命令行模式,创建表、插入记录、查询记录:
[root@hadoop01-namenode bin]# hbase shell
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/hadoop/hadoop-2.8.5/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/hadoop/hbase-2.1.6/lib/client-facing-thirdparty/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
HBase Shell
Use "help" to get list of supported commands.
Use "exit" to quit this interactive shell.
For Reference, please visit: http://hbase.apache.org/2.0/book.html#shell
Version 2.1.6, rba26a3e1fd5bda8a84f99111d9471f62bb29ed1d, Mon Aug 26 20:40:38 CST 2019
Took 0.0028 seconds
hbase(main):001:0> list
TABLE
0 row(s)
Took 0.3541 seconds
=> []
hbase(main):002:0> create 'test','cf1','cf2'
Created table test
Took 2.3501 seconds
=> Hbase::Table - test
hbase(main):003:0> put 'test','row1','cf1:name','zhang'
Took 0.3023 seconds
hbase(main):004:0> put 'test','row1','cf1:age','30'
Took 0.0215 seconds
hbase(main):005:0> put 'test','row1','cf2:graduate','1'
Took 0.0212 seconds
hbase(main):006:0> scan 'test'
ROW COLUMN+CELL
row1 column=cf1:age, timestamp=1567150906738, value=30
row1 column=cf1:name, timestamp=1567150896250, value=zhang
row1 column=cf2:graduate, timestamp=1567150961294, value=1
1 row(s)
Took 0.1412 seconds
hbase(main):007:0>
效果如下截图所示:
[图片上传失败...(image-5f4630-1568608205959)]
6.6 Java API连接和操作HBase数据库
- pom.xml引入hbase相关jar包
org.springframework.data spring-data-hadoop-hbase 2.5.0.RELEASE org.apache.hbase hbase-client 1.3.1 org.apache.hbase hbase-server 1.3.1 org.apache.hbase hbase-common 1.3.1 - application.yml中配置hbase相关信息
hbase: zookeeper: quorum: 10.141.212.142,10.141.212.147,10.141.212.135 property: clientPort: 2181 - 加载configuration和connection
@Bean public Connection hbaseConnection() { org.apache.hadoop.conf.Configuration conf = new org.apache.hadoop.conf.Configuration(); conf.set("hbase.zookeeper.quorum", zookeeperQuorum); conf.set("hbase.zookeeper.property.clientPort", clientPort); // conf.set("zookeeper.znode.parent", znodeParent); // conf.set("zookeeper.sasl.client", "false"); // conf.set("hbase.master","10.141.212.140:60000"); try { return ConnectionFactory.createConnection(conf); } catch (IOException e) { e.printStackTrace(); } return null; } - Java操作HBase数据库样例
@Autowired private Connection conn; public void fetchDataFromHBase(String tableName, String rowKey, String day, String colFamily) { try { Table table = conn.getTable(TableName.valueOf(tableName)); Get get = new Get(Bytes.toBytes(rowKey + day)); get.addFamily(Bytes.toBytes(colFamily)); Result rs = table.get(get); Cell[] cells = rs.rawCells(); for (Cell cell : cells) { System.out.println(new String(CellUtil.cloneQualifier(cell))); System.out.println(new String(CellUtil.cloneFamily(cell))); System.out.println(new String(CellUtil.cloneRow(cell))); System.out.println(new String(CellUtil.cloneValue(cell))); } System.out.println("sdf"); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } public void createAndPutData(String tableName) { try { Admin baseAdmin = conn.getAdmin(); TableName tName = TableName.valueOf(tableName); HTableDescriptor tableDesc = new HTableDescriptor(tName); HColumnDescriptor colDesc = new HColumnDescriptor("cf1"); tableDesc.addFamily(colDesc); baseAdmin.createTable(tableDesc); Put put1 = new Put("0001".getBytes()); put1.addColumn("cf1".getBytes(), "col1".getBytes(), "value1".getBytes()); put1.addColumn("cf1".getBytes(), "col2".getBytes(), "value2".getBytes()); put1.addColumn("cf1".getBytes(), "col3".getBytes(), "value3".getBytes()); Put put2 = new Put("0002".getBytes()); put2.addColumn("cf1".getBytes(), "col1".getBytes(), "value1".getBytes()); put2.addColumn("cf1".getBytes(), "col2".getBytes(), "value2".getBytes()); put2.addColumn("cf1".getBytes(), "col3".getBytes(), "value3".getBytes()); Table hTable = conn.getTable(tName); hTable.put(put1); hTable.put(put2); } catch (IOException e) { e.printStackTrace(); } } public void deleteRowData(String tableName, String rowKey) { TableName table = TableName.valueOf(tableName); Delete delete = new Delete(rowKey.getBytes()); try { conn.getTable(table).delete(delete); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } }
6.7 高可用HA说明及验证
HBase是基于zookeeper实现高可用HA,即一个Active状态的主HMaster,一个StandBy状态的从HMaster。当Active状态的主HMaster节点宕机时,zookeeper会自动将StandBy状态的节点切换为Active。
如,kill掉hadoop01-namenode机器上的主HMaster节点:
[root@hadoop01-namenode bin]#
[root@hadoop01-namenode bin]# jps
7456 Jps
3282 ResourceManager
2612 JournalNode
6774 HMaster
2809 DFSZKFailoverController
2363 NameNode
2159 QuorumPeerMain
[root@hadoop01-namenode bin]# kill -9 6774
[root@hadoop01-namenode bin]#
如下图所示,kill掉hadoop01-namenode机器上的HMaster进程后,hadoop02-namenode自动切换为Active状态的Master节点。
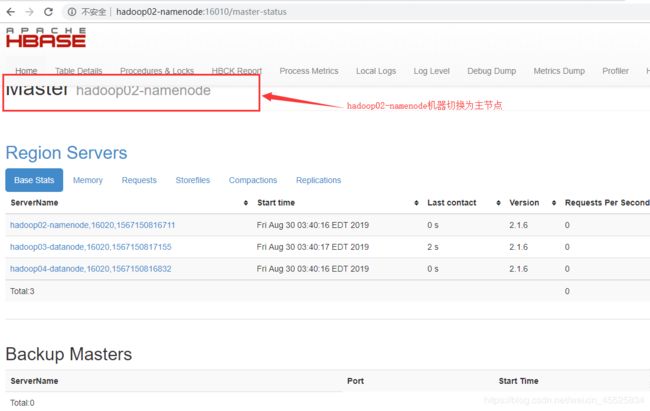
至此,高可用HA分布式数据库HBase安装及验证完成。
7 Flink安装和验证
Flink有三种安装方式:单机版、Standlone HA高可用集群、Yarn HA高可用集群。
单机版:多用于验证阶段,一般不用于实际业务场景;
Standlone HA高可用集群:依赖于zookeeper实现Master主备,进而实现HA高可用。初始时,即启动时即确定出主备Master(JobManager)资源、任务处理机TaskManager资源,资源固定;
Yarn HA高可用集群:依赖于Hadoop Yarn实现动态创建、分配资源。配置方式与Standlone HA一致,只是任务启动方式不同;
本文使用Standlone HA方式构建高可用计算引擎集群。
备注:
- Flink多用于历史批任务处理和实时流数据批处理,而其中历史批任务处理是以Hadoop DFS作为数据源的(HBase也可以),故安装使用Flink前需要安装好Hadoop DFS环境;如果是用于实时流数据处理,可以不用安装启动Hadoop DFS环境;
- Flink on Yarn是以Hadoop Yarn为基础的,如果想部署Flink on Yarn的高可用环境,需先安装好Hadoop Yarn环境;
- Flink与Hadoop有版本兼容问题,故要先选定好兼容版本再安装,本文使用Flink1.7.2版本;
7.1 部署规划
共4台CentOs7环境,规划如下表所示:
| 机器名 | 安装软件 | 进程 |
|---|---|---|
| hadoop01-namenode | jdk, zookeeper, hadoop, flink | QuorumPeerMain, StandaloneSessionClusterEntrypoint, |
| hadoop02-namenode | jdk, zookeeper, hadoop, flink | QuorumPeerMain, StandaloneSessionClusterEntrypoint, TaskManagerRunner |
| hadoop03-datanode | jdk, zookeeper, hadoop, flink | QuorumPeerMain, TaskManagerRunner |
| hadoop04-datanode | jdk, zookeeper, hadoop, flink | QuorumPeerMain, TaskManagerRunner |
说明:
- 在hadoop01-namenode和hadoop02-namenode两机器上构建Cluster Master(JobManager)主备高可用HA;
- 在Hadoop02-namenode、hadoop03-datanode、hadoop04-datanode三台机器上做任务处理节点;
7.2 下载及安装
注意,Flink与Hadoop有版本兼容问题,安装前先确认下与之匹配的版本;
本文选择的是与hadoop2.8.5版本兼容配套的Apache Flink 1.7.2 with Hadoop® 2.8 for Scala 2.11 (asc, sha512)版本,注意是选择with Hadoop版本。
下载地址:https://www-eu.apache.org/dist/flink/flink-1.7.2/flink-1.7.2-bin-hadoop28-scala_2.11.tgz
在hadoop01-namenode机器上使用wget命令下载、解压、配置完成后,再使用scp命令整体考本到其他三台机器上即可。
wget https://www-eu.apache.org/dist/flink/flink-1.7.2/flink-1.7.2-bin-hadoop28-scala_2.11.tgz
tar -zxvf flink-1.7.2-bin-hadoop28-scala_2.11.tgz -C /hadoop/
7.3 配置文件修改
-
修改系统环境变量
系统环境变量/etc/profile中增加Flink的根目录:$FLINK_HOME=/hadoop/hbase-2.1.6
并使生效。vi /etc/profile如下截图所示:
 在这里插入图片描述
在这里插入图片描述
使环境变量即可生效:
source /etc/profile。
 在这里插入图片描述
在这里插入图片描述 修改配置文件$FLINK_HOME/conf/flink-conf.yaml
增加或修改下述配置项:
jobmanager.web.port: 8081
jobmanager.heap.size: 4096m
fs.overwrite-files: true
fs.output.always-create-directory: true
taskmanager.heap.size: 4096m
taskmanager.numberOfTaskSlots: 8
parallelism.default: 8
state.backend: filesystem
state.backend.fs.checkpointdir: hdfs://mycluster/flink/checkpoints
fs.hdfs.hadoopconf: /itcast3.1.0/hadoop-3.1.1/etc/hadoop
recovery.mode: zookeeper
recovery.zookeeper.quorum: hadoop01-namenode:2181,hadoop02-namenode:2181,hadoop03-datanode:2181,hadoop04-datanode:2181
recovery.zookeeper.storageDir: hdfs://mycluster/flink/recovery
recovery.zookeeper.path.root: /flink
recovery.zookeeper.path.namespace: /flink
- 修改配置文件$FLINK_HOME/conf/masters
配置高可用HA主备节点JobManager:
hadoop01-namenode:8081
hadoop02-namenode:8081
- 修改配置文件$FLINK_HOME/conf/slaves文件
配置任务执行节点TaskManager:
hadoop02-namenode
hadoop03-datanode
hadoop04-datanode
7.4 安装同步到其他三台机器上
- 将系统环境变量配置文件和Flink版本整体拷贝到其他三台机器上即可,其他三台机器无需逐一安装。
注意:环境变量拷贝到其他机器后,要在相应志气上执行source命令使即刻生效。
scp /etc/profile root@hadoop02-namenode:/etc/
scp /etc/profile root@hadoop03-datanode:/etc/
scp /etc/profile root@hadoop04-datanode:/etc/
scp /hadoop/flink-1.7.2/ root@hadoop02-namenode:/hadoop/
scp /hadoop/flink-1.7.2/ root@hadoop03-datanode:/hadoop/
scp /hadoop/flink-1.7.2/ root@hadoop04-datanode:/hadoop/
7.5 启动及验证
- 启动Flink Standalone HA
有三种使用模式:
A. Flink Standalone HA高可用集群,用于处理实时数据流时,不依赖Hadoop dfs,可以直接起动即可;
B. Flink Standalone HA高可用集群,基于Hadoop的分布式文件系统作为任务的数据源,多用于历史处理批量任务处理;
C. Flink on Yarn HA高可用集群,基于Hadoop的分布式文件系统DFS作为任务的数据源,Yarn管理资源JobManager、ApplicationMaster和TaskManager的动态申请创建,进而实现硬件资源的高利用率。
本例中,使用上述B方式,基于Hadoop的分布式文件系统作为任务的胡娟,进行批量任务执行,即需要先启动hadoop dfs系统,再启动flink集群,命令如下:
cd /hadoop/hadoop-2.8.5/sbin/
./start-dfs.sh
cd /hadoop/flink-1.7.2/bin/
./start-cluster.sh
启动完成后,使用jps命令查询hadoop01-namenode机器上的进程信息如下:
[root@hadoop01-namenode bin]# jps
8465 StandaloneSessionClusterEntrypoint
8561 Jps
7321 NameNode
7753 DFSZKFailoverController
7581 JournalNode
2159 QuorumPeerMain
[root@hadoop01-namenode bin]#
hadoop02-namenode机器上的进程信息如下:
[root@hadoop01-namenode bin]# jps
[root@hadoop02-namenode hadoop]# jps
19937 DFSZKFailoverController
20929 TaskManagerRunner
20450 StandaloneSessionClusterEntrypoint
19830 JournalNode
19611 NameNode
19694 DataNode
21070 Jps
2159 QuorumPeerMain
[root@hadoop02-namenode hadoop]#
hadoop03-datanode和hadoop04-datanode机器上的进程信息相同,如下所示:
[root@hadoop03-datanode hadoop]# jps
3698 QuorumPeerMain
28948 TaskManagerRunner
27962 DataNode
31310 Jps
[root@hadoop03-datanode hadoop]#
上述命令执行如下截图所示:
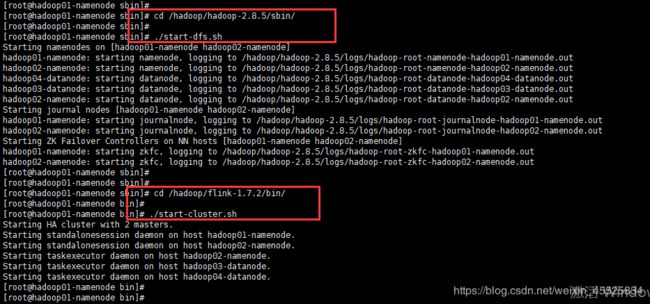
- 验证Flink
A. 首先通过web管理页面确认Hadoop DFS运行正常:http://hadoop01-namenode:9870/
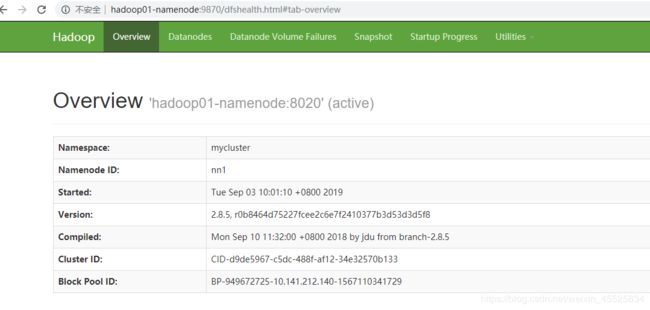
B. 通过web管理页面确认Flink运行正常:http://hadoop01-namenode:8081
[图片上传失败...(image-47342b-1568608205959)]
C. 验证Flink自带的单词统计批量任务
首先,上传一个大文件至dfs系统中,本例中上传了一个427.5M的日志log文件到dfs中;
hdfs dfs -put /usr/zhang0908/hadoopdata/tmp/kieker-001.log hdfs://mycluster/data/flink/wordcount/
其次,执行Flink单词统计批量任务:
./flink run -m hadoop01-namenode:8081 ../examples/batch/WordCount.jar --input hdfs://mycluster/data/flink/wordcount/kieker-001.log --output hdfs://mycluster/data/flink/wordcount/output
查看任务执行结果:
hdfs dfs -ls hdfs://mycluster/data/flink/wordcount/output
执行过程如下截图所示,从执行结果来看,该427.5M大小的日志文件,单词统计共耗时36秒。

批量任务执行过程中,在web管理页面中可以看见该任务的执行过程详细情况:

8 安装过程中碰到的坑
虽然hadoop大数据处理已经出来很久了,但总的感觉整个生态圈还不成熟、不稳定,存在各种版本、兼容和配置问题。
下面记录了安装过程中碰到的问题:
(1)DFS文件夹权限不够
错误提示:

解决方法:

(2) yarn-site.xml配置问题
错误提示:
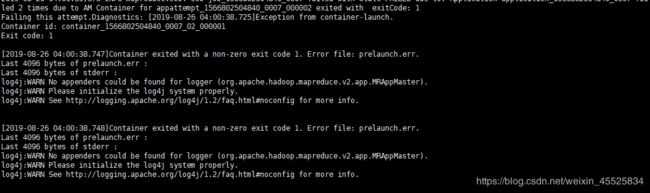
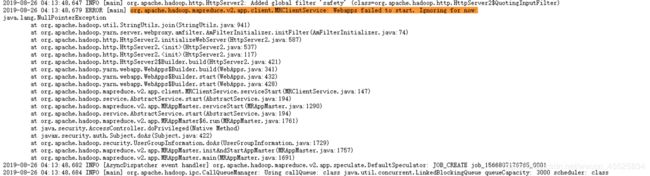
解决方法:
在hadoop3.X版本中,yarn-site.xml文件中需要显示配置scheduler端口,增加以下配置:

https://blog.csdn.net/danielchan2518/article/details/85887597
http://www.mamicode.com/info-detail-2419068.html
(3)集群机器时间同步
错误提示如下:
Application application_1567491341696_0003 failed 2 times in previous 10000 milliseconds due to Error launching appattempt_1567491341696_0003_000003. Got exception: org.apache.hadoop.yarn.exceptions.YarnException: Unauthorized request to start container. This token is expired. current time is 1567535049881 found 1567492518315 Note: System times on machines may be out of sync. Check system time and time zones. at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62) at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) at java.lang.reflect.Constructor.newInstance(Constructor.java:423) at org.apache.hadoop.yarn.api.records.impl.pb.SerializedExceptionPBImpl.instantiateExceptionImpl(SerializedExceptionPBImpl.java:171) at org.apache.hadoop.yarn.api.records.impl.pb.SerializedExceptionPBImpl.instantiateException(SerializedExceptionPBImpl.java:182) at org.apache.hadoop.yarn.api.records.impl.pb.SerializedExceptionPBImpl.deSerialize(SerializedExceptionPBImpl.java:106) at org.apache.hadoop.yarn.server.resourcemanager.amlauncher.AMLauncher.launch(AMLauncher.java:123) at org.apache.hadoop.yarn.server.resourcemanager.amlauncher.AMLauncher.run(AMLauncher.java:250) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) . Failing the application.
问题原因:
集群中机器时间不同步导致,主要是namenode和datanode机器时间不同。
解决办法:
在每台服务器执行如下两个命令进行时间同步:
1)输入“cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime”
2)输入“ntpdate pool.ntp.org”
(4)HBase异常:hdfs未知
如下截图所示:
regionserver启动失败,错误信息如下,找不到hdfs服务主机。

解决方法:
复制hdfs-site.xml、core-site.xml到$HBASE_HOME/conf下。
(5)如下异常
java.lang.IllegalStateException: The procedure WAL relies on the ability to hsync for proper operation during component failures, but the underlying filesystem does not support doing so. Please check the config value of 'hbase.procedure.store.wal.use.hsync' to set the desired level of robustness and ensure the config value of 'hbase.wal.dir' points to a FileSystem mount that can provide it.
解决方法:
在hbase-site.xml增加配置
hbase.unsafe.stream.capability.enforce
false
(6)hadoop集群启动,在datanode上需要先启动zookeeper,所以在hbase中需要禁用hbase自带的zookeeper,使用hadoop datanode上的外置zookeeper。
方法:
(7)修改:vi conf/hbase-env.sh
export HBASE_MANAGES_ZK=false#设置为false,禁用hbase自带的zookeeper
修改:vi conf/hbase-site.xml
增加下面的配置,否则regionserver会启动失败:
(8)复制htrace-core-3.1.0-incubating.jar到$HBASE_HOME/lib下
错误提示如下图所示:
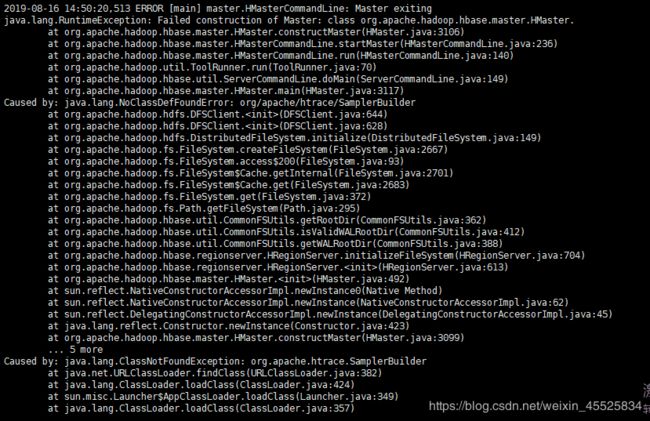
解决方法:
cp $HBASE_HOME/lib/client-facing-thirdparty/htrace-core-3.1.0-incubating.jar $HBASE_HOME/lib/
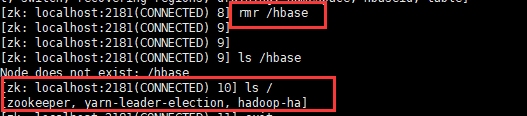
(9)重置zookeeper的zNode:hbase
错误提示如下:
master.HMaster: hbase:meta,,1.1588230740 is NOT online; state={1588230740 state=OPEN,ts=1543610616273, server=regionserver1.domain.com,41213,1543389145213}; ServerCrashProcedures=true.Master startup cannot progress, in holding-pattern until region onlined
解决方法:
zookeeper节点都启动的状态下,任选一个节点执行以下命令:
zookeeper/bin/zkCli.sh -server localhost:2181
rmr hbase
如下截图所示:

(10)Java API操作HBase,发起请求,但长时间无响应、无返回、无报错日志
解决方法:
Java工程缺少相关Jar包导致出错,但系统并没有能打印出相应的错误提示或终止,导致长久无响应、无返回。
检查确认下面的三个Jar包都已引入,如果都已引入依然长时间无响应,可将$HBASE_HOME/lib下的所有jar包引入工程。

(11)Java API操作HBase,Windows环境下,控制台报错显示HBase所在linux hostname无法识别
解决办法:
在windows环境下,也需要在host配置文件中增加linux hbase所在环境的hostname与IP地址映射关系,同linux下的配置方式,如下截图所示:
[图片上传失败...(image-d22c53-1568608205959)]
ipconfig /flushdns -----即可生效,无效重启电脑
(12) flink运行在yarn上需要额外下载的几个jar包:
https://github.com/dounine/flink-1.8-depends/tree/master/lib
[图片上传失败...(image-fedf71-1568608205959)]
(13)flink搭配hadoop的dfs使用,需要下载Apache Flink X.X.X with Hadoop® X.X for Scala X.XX版本,即with hadoop的版本,否则报hdfs文件系统找不到,如下截图所示:
