一、lateinit
变量的关键字,可以不用在定义变量的时候就设置初始值
二、原有项目一些涉及到apt的第三方库,改为kotlin后,报错,resource中没有相关类
使用到apt相关的第三方,比如arouter,要使用kapt,但是如果你的项目用到了很多第三方,并且有些第三方不支持kapt的话就不行,比如lombok。有一种很土的办法就是把kapt和java annotation配置分成两个目录,我没试过感觉有点恶心。
但是如果支持kapt可以这改造一样就能用:
1、apply plugin: 'kotlin-kapt'
2、有kotlin的代码,javaCompileOptions改为kapt的
defaultConfig{
...
// javaCompileOptions {
// annotationProcessorOptions {
// arguments = [ moduleName : project.getName() ]
// }
// }
kapt {
arguments {
arg("moduleName", project.getName())
}
}
}
3、有kotlin的代码,需要依赖配置修改annotationProcessor改为kapt
compile 'com.alibaba:arouter-api:1.3.1'
// annotationProcessor 'com.alibaba:arouter-compiler:1.1.4'
kapt 'com.alibaba:arouter-compiler:1.1.4'
三、let、with、run和apply
对象?.let{} 方便不为空的时候用来使用这个对象,等同于省去if(null != 对象){}的判断;
with(对象){} 方便一些配置信息,比如变量赋值,设置是否可以显示,设置点击事件等等,用来代替builder的链式调用,这对安卓开发中操作控件极其好用,因为控件没有builder来让你链式;
或者对一个对象连续多次操作后返回任意东西(lambda最后一行代码返回值就是整个with返回值)都可以用with来简化代码。
with(bt) {
this.visibility = View.VISIBLE
this.text = "填充按钮文字"
this.onClick { bt.handleKeyboard() }
}
对象.run 和with用法一样,只不过with是传对象进去,run是由对象.调用,返回值也是lambda最后一行代码。
对象.apply 和run用法一样,不过返回值不再是最后一行代码了,而是返回调用对象本身。
with、run、apply都非常相似,仅有一点小区别,使用上灵活选择即可。
四、标签 @
@标签 可以理解成标记一下来源
对于嵌套for循环来说,可以指定跳出哪一层循环,比java好用,比如:
//用标签来指定需要跳出哪个循环,比java中好用
// firstLoop@ for (i in 1..10) {
// println("第一层循环i=${i}")
// secondLoop@ for (j in 1..10) {
// println("第二层循环j = ${j}")
// if (j > 6) break@firstLoop
// for (x in 1..6) {
// if (x < 2) break@secondLoop
// }
// }
// }
但是对于嵌套的lamda表达式foreach来说,用return+标签并不是跳出标签的foreach循环,debug了一下,发现是continue,例子:
fun foo() {
ints.forEach {
if (it == 2) {
println("满足条件,直接下一次循环")
return@forEach
}
println(it)
}
println("------foo")
}
打印结果是:
1
满足条件,直接下一次循环
3
------foo
如果return不带标签,则是直接结束方法,例子:
fun foo() {
ints.forEach {
if (it == 2) {
println("满足条件,直接下一次循环")
return
}
println(it)
}
println("------foo")
}
打印结果是:
1
满足条件,直接下一次循环
五、有时候用print打印输出的时候,控制台会打印出一串“kotlin.Unit”
研究了一下和print中打印的内容有关,如果打印的是一个有返回值的方法,则输出返回值,如果打印的是一个没有返回值的方法,就会打印出一串“kotlin.Unit”,而不是什么都不打印,为什么呢?因为print调用Unit的toString方法, Unit的toString方法内容:
public object Unit {
override fun toString() = "kotlin.Unit"
}
六、final和open
类默认是final,如果需要被继承,需要加open关键字
fun声明的函数默认是final,如果需要被重写,需要加open,子类重写是用override关键字
为什么默认是final?因为kotlin这么设计就是为了不重蹈java覆辙。java中对final是不强制的,这其实是非常不安全的。java不强制,开发者就基本不会主动加final关键字,即使这个类一个子类都没,在项目越来越大之后,这种不规范的写法就变得很危险,你无法知道别人会不会去继承这个类从而导致一些不可控的错误。
七、关于kotlin中方法和变量的override
方法:
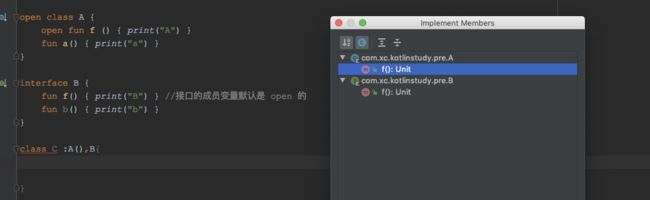
Kotlin的继承和实现中如果父类和接口有重复方法,使用super范型去选择性地调用父类的实现:
class C() : A() , B{
override fun f() {
super.f()//调用 A.f()
super.f()//调用 B.f()
}
}
和java区别比较大,java如果继承的类和实现的接口中有相同方法,接口需要实现的方法默认会被父类实现,子类可以继续重写父类这个方法;而kotlin一定需要子类去实现接口的方法。
变量:
因为kotlin的继承不允许子类有和父类一样的变量名。。。除非父类里面变量是private或者子类override这个变量。。。
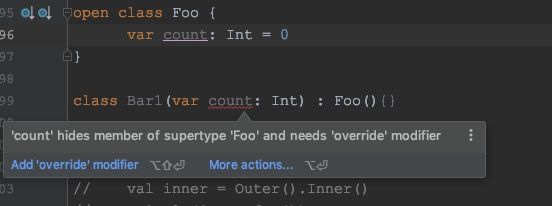
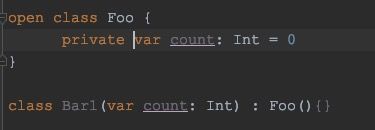
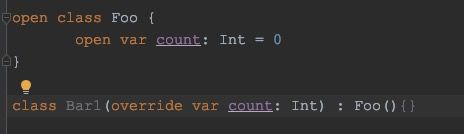
属性的继承这里有一个特别要注意的点,否则一不小心就空指针:
IDE报的是:Accessing non-final property name in constructor
不继承就没事
八、kotlin中的接口与java中的接口
Kotlin 接口与 Java 8 类似,使用 interface 关键字定义接口,允许方法有默认实现接口中的属性只能是抽象的,不允许初始化值,接口不会保存属性值,实现接口时,必须重写属性,,这和java中不同,java中接口中定义的属性都是常量
九、kotlin中的扩展
Kotlin中可以很方便的对一个类的属性或方法进行扩展,不用像java一样使用继承或者装饰模式Decorator去实现。扩展不会对原有类进行修改,注意这不是修改,只是一种静态的行为。
在调用扩展函数时,具体被调用的的是哪一个函数,由调用函数的的对象表达式来决定的,而不是动态的类型决定的,这和java中方法的静态分配是一样的。
先举一个kotlin例子:
open class C
class D : C()
//扩展C
fun C.foo() = "c"
//扩展D
fun D.foo() = "d"
//方法入参C
fun printFoo(c: C) {
println(c.foo())
}
fun main() {
//实际传入D实例
printFoo(D())
}
打印结果:c
再来一个java的例子对比一下:
public class MyTest5 {
//方法的入参类型就是静态类型,编译期就可以完全确定
public void test(Grandpa grandpa) {
System.out.println("grandpa");
}
public void test(Father father) {
System.out.println("father");
}
public void test(Son son) {
System.out.println("son");
}
public static void main(String[] args) {
Grandpa g1 = new Father();
Grandpa g2 = new Son();
MyTest5 myTest5 = new MyTest5();
myTest5.test(g1);
myTest5.test(g2);
}
}
class Grandpa {
}
class Father extends Grandpa {
}
class Son extends Father {
}
打印结果:
//grandpa
//grandpa
我们从字节码上分析一下:
main方法的Code属性字节码为:
0 new #7
3 dup
4 invokespecial #8 >
7 astore_1
8 new #9
11 dup
12 invokespecial #10 >
15 astore_2
16 new #11
19 dup
20 invokespecial #12 >
23 astore_3
24 aload_3
25 aload_1
26 invokevirtual #13
29 aload_3
30 aload_2
31 invokevirtual #13
34 return
看26、31行,invokevirtual 指令的意思是调用虚方法(存在运行期动态查找的过程),调用谁的方法呢,是com/xuchun/bytecode/MyTest5.test方法,MyTest5里有三个test方法,是哪个呢,再看#13对应的常量池里的常量信息:

可以看到方法的Name是test,参数类型是Lcom/xuchun/bytecode/Grandpa;方法返回值是void,同样是方法的静态分配。
静态类型是不会变化,但是实际类型是可以再运行期间变化的,这也是多态的体现。
在举个例子加深记忆:
//扩展函数可以被申明为open,可以被其子类覆写,扩展对于被扩展函数的类是静态的,但是对于扩展方是虚拟的。
open class D
class D1 : D()
open class C {
open fun D.foo() {
println("D.foo in C")
}
open fun D1.foo() {
println("D1.foo in C")
}
fun caller(d: D) {
d.foo()//调用扩展函数
}
}
class C1 : C() {
override fun D.foo() {
println("D.foo in C1")
}
override fun D1.foo() {
println("D1.foo in D1")
}
}
fun main() {
C().caller(D())//D.foo in C
C1().caller(D())//D.foo in C1
C().caller(D1())//D.foo in C
C1().caller(D1())//D.foo in C1
}
扩展方法中的this:
扩展方法中的this就是被扩展的对象实例:
fun User.printName() {
println(name)
}
fun User.cName(n: String) :User{
name = n
return this
}
fun main() {
User("测试扩展函数").cName("用扩展方法重新给变量赋值").printName()
}
输出:用扩展方法重新给变量赋值
十、用kotlin创建的类或者接口,java调用时报找不到
检查你的kotlin类或者接口中的第一行有没有特别的符号,比如:`
原因是可能你用了关键字作为文件夹名称,这个文件夹中的类或者接口不会报错,kotlin会自动把第一行的package翻译成kotlin不报错的形式,比如你用interface做了文件夹的名称,下面的接口第一行:package com.xuchun.floatingview.`interface`,这样的话kotlin之间互相可以使用没问题,java来使用就不行了。
解决方法:不用关键字做文件夹名称。
十一、kotlin中单例怎么写:
class Floater private constructor() : IFloater {
companion object {
val instance: Floater by lazy {
Single.instance
}
}
private object Single {
val instance = Floater()
}
}
kotlin调用:Floater.instance
java调用:Floater.Companion.getInstance()
十二、kotlin中的泛型
1、泛型约束:
对泛型的上界进行约束可以让你可以把泛型当做它的上界类型,从而直接调用上界类型的方法,很快乐
fun oneHalf(value:T):Double{
return value.toDouble()//直接就可以用Number的方法
}
所以当你如果定义多个约束,你就可以获得多倍快乐:
fun ensureTrailingPeriod(seq:T) where T:CharSequence,T:Appendable{
//CharSequence和Appendable的方法你都可以直接用
}
快乐的代价就是要守规矩:这里表示你的seq实际传入的类型必须要同时实现T:CharSequence和T:Appendable。
需要注意的是:kotlin中没有指定上界的泛型会有一个默认上界:Any? ,此时你的泛型参数是可空的,即使并没有在T后面写问号标记,如果此时想要设为不为空,就显示的设定上界为Any替换掉默认的Any?即可。
2、泛型型变:
先看一下java中泛型的型变:
型变简单理解就是类型的变化。一个类型可能有子类型,可能有父类型,在不同情况下,类型的变化是有一定规则的,不是随心所欲的。
那么逆变与协变是什么呢?是用来描述类型变换后的继承关系,并且有一个公式可以套用:
如果、表示类型,(⋅)表示类型转换,≤表示继承关系(比如,≤表示是的子类):
(⋅)是逆变(contravariant)的,当≤时有()≤()成立;
(⋅)是协变(covariant)的,当≤时有()≤()成立;
(⋅)是不变(invariant)的,当≤时上述两个式子均不成立,即()与()相互之间没有继承关系。
换句话说,你如果想让你的泛型是可以变化的,那就必须要用逆变或者协变。老师敲黑板:注意,我要变型了!
上面公式看不懂没关系,直接看例子:
举一个不规范但就是直观的简单例子:
public static class 爷爷 {
}
public static class 父亲 extends 爷爷 {
}
public static class 儿子 extends 父亲 {
}
public static class 孙子 extends 儿子 {
}
然后定一个List变量,声明列表容器接收儿子类型
List<儿子> list = new ArrayList<儿子>();
这样定义,编译和运行都不会报错,IDE甚至还好心提示你:Explicit type argument 儿子 can ben replaced with<>,什么意思呢,就是对你说,她很聪明的,你声明的时候已经明确告诉她类型了,后面实例化的时候就不用再写一遍类型了。
既然IDE都这么提示我了,那我只能......偏不,我就写,我还写个不一样的,比如:
List<儿子> list = new ArrayList<父亲>();
这次IDE直接报错了:incompatible types:List<儿子>,ArrayList<父亲>
这句英文什么意思呢,就是IDE骂人了:让你系安全带你不系,你xx!
不好意思翻译错了,实际意思说的是:这两个类型是矛盾的!
我们带入上面的公式,得到(儿子) = ArrayList<儿子>,(父亲) = ArrayList<父亲>,如果泛型是逆变,则ArrayList<儿子>是ArrayList<父亲>的父类,上面的例子报错已经证明了,ArrayList<儿子>并不是ArrayList<父亲>的父类型,同样泛型也不是协变,实际上泛型没有任何继承关系,也就是说泛型是不变的。
那怎么改呢?怎么申明类型才能又接收儿子又接受父亲呢?这样:
List list = new ArrayList<父亲>();
这个类型不知道到底是儿子还是爸爸,所以写成”?“(java通配符,代表任何类型),"? super 儿子"就表示这个类型可以是儿子或者是儿子的父类,那谁是儿子的父类呢,爸爸和爷爷,所以把爷爷捉过来放进去也没问题。(爷爷说:莫挨老子)
也就是说,泛型是不变的,但是我们用别的办法实现了泛型的逆变。
List list = new ArrayList<爷爷>();
“? super” 就实现了泛型的”逆变“,
那现在孙子还没用上呢,再改一下:
List<儿子> list = new ArrayList<孙子>();
果然不出所料,IDE又开骂了:你XX。
不对啊,儿子是孙子的父类,正常情况下,是可以声明一个父类变量给他赋值子类对象呀,比如儿子 erzi = new 孙子()。但是编译器已经报错告诉你了
List<儿子>和 ArrayList<孙子>类型是矛盾的!也就是说儿子是孙子的父类,不代表List<儿子>就是 List<孙子>的父类,所以没有继承关系当然不能类型转换,这里又验证了一遍泛型是不变的。
赶紧改吧:
List list = new ArrayList<孙子>();
不报错了,"? extends 儿子"就表示这个类型可以是儿子或者儿子的子类。孙子是儿子的子类,所以没问题。这就实现了泛型的”协变“。
上面的例子只做了赋值操作,在使用了协变或逆变后都可以让赋值操作编译正确。
但是当你想往list里存数据时,比如:
List list = new ArrayList<孙子>();
孙子 sunzi = new 孙子();
list.add(sunzi);
编译会报如下错误:
Error:(40, 13) java: 对于add(decorator.MainTest.孙子), 找不到合适的方法
方法 java.util.Collection.add(capture#1, 共 ? extends decorator.MainTest.儿子)不适用
(参数不匹配; decorator.MainTest.孙子无法转换为capture#1, 共 ? extends decorator.MainTest.儿子)
方法 java.util.List.add(capture#1, 共 ? extends decorator.MainTest.儿子)不适用
(参数不匹配; decorator.MainTest.孙子无法转换为capture#1, 共 ? extends decorator.MainTest.儿子)
意思就是不能把孙子类型存到list中。实际上这个list不能存除了null之外的任何类型,包括儿子。也就是说List丧失了”写“的能力!
相对应的:
List list = new ArrayList<父亲>();
父亲 fuqin = new 父亲();
list.add(fuqin);
一样会报上面的错误,但是和? extends有点区别的是,这个list可以存null和儿子类型及其子类型(孙子)!
不信我们操作一下:
儿子 erzi = new 儿子();
孙子 sunzi = new 孙子();
list.add(erzi);
list.add(sunzi);
list.add(null);
list.forEach(System.out::println);//打印一下
打印结果:
decorator.MainTest$儿子@7ef20235
decorator.MainTest$孙子@27d6c5e0
null
奇怪了,定义的类型明明是儿子和儿子的父类,不能往里添加父亲就算了,但是为啥可以往里添加儿子和儿子的子类?!
下面来探究为什么这两个list不能完整的使用add方法,甚至不能使用add方法。
先打印下他们俩的类型:
List list = new ArrayList<父亲>();
List list2 = new ArrayList<孙子>();
System.out.println("list的类型是:" + list.getClass());
System.out.println("list2的类型是:" + list2.getClass());
打印结果:
list的类型是:class java.util.ArrayList
list2的类型是:class java.util.ArrayList
他两都是ArrayList类型!<父亲>,<孙子>这些都没了,那我还在上面费劲吧啦的定义类型干什么!
那我们指定的类型去哪了呢?会不会在List内部记录了这个类型。
Class c = list.getClass();
Field[] fields = c.getDeclaredFields();
for (Field f : fields) {
System.out.println("属性名= " + f.getName() + " 属性类型 = " + f.getType().getName());
}
打印结果:
属性名= serialVersionUID 属性类型 = long
属性名= DEFAULT_CAPACITY 属性类型 = int
属性名= EMPTY_ELEMENTDATA 属性类型 = [Ljava.lang.Object;
属性名= DEFAULTCAPACITY_EMPTY_ELEMENTDATA 属性类型 = [Ljava.lang.Object;
属性名= elementData 属性类型 = [Ljava.lang.Object;
属性名= size 属性类型 = int
属性名= MAX_ARRAY_SIZE 属性类型 = int
怎么肥事,elementData类型都是Object。也就是说这个list实际是可以存任意类型的!换句话说泛型的类型被抹去了,变成了Object(这也是为什么泛型不能是基本类型的原因,想存基本类型也只能用它的包装类)。虽然编译期在我们写代码的时候会检查提示错误,但是我们可以用反射绕过检查试一下:
List list2 = new ArrayList<孙子>();
孙子 sunzi = new 孙子();
// list2.add(sunzi);//会报错
list2.getClass().getMethod("add",Object.class).invoke(list2,sunzi);
System.out.println(list2.get(0));
打印结果:
decorator.MainTest$孙子@5e2de80c
说明确实可以存进去,并且,还可以突破? extends 儿子这个限制,把儿子的父类传进去都可以:
父亲 fuqin = new 父亲();
list2.getClass().getMethod("add",Object.class).invoke(list2,fuqin);
System.out.println(list2.get(1));
打印结果:
decorator.MainTest$父亲@5e2de80c
这不仅能验证运行期间可以存任意类型,而且还能说明,编译器对我们编写的代码,是先检查我们定义的泛型的类型,然后再去编译成可以存任意类型的,也就是对泛型的类型,编译器是先“检查”后“编译并抹去类型”。
看一下编译后生成的字节码文件局部变量表,也没有任何指定的泛型信息。

这里其实是java语言的一个特性,那就是java中的泛型是个伪泛型,编译后泛型信息就没了,只剩下了原始类型(原始类型是什么一会说),这个过程叫做”类型擦除”。
为什么要弄这个类型擦除呢,因为java5之前是没有泛型的,也就是说list的add可以放任何类型,那么java5之后为了既能向下兼容,又要解决类型安全和类型自动转换的问题,于是就设计成了类型擦除。
可是类型都被擦除了,我们调用add方法编译器还会给我们报错呢,原因上面我们已经验证过了:编译器是先检查后编译擦除的。这其实也是泛型出现的一个原因:把对类型的检查提前到编译之前,来确保类型安全,要知道泛型没出现之前,list的add可以放任何类型,是非常不安全的。
kotlin和java一样,也有类型擦除,所以你在运行时是没法检查你的泛型的:
if(value instanceof List)//java写法:报错
if(value is List)//kotlin写法:报错
正确写法就是java用不指定泛型实际类型或者使用通配符,kotlin用投影语法星号:
if(value instanceof List)//java写法1
if(value instanceof List)//java写法2
if(value is List<*>)//kotlin写法
到这里我们就知道了,设置的泛型类型其实并不会被带到运行期,只是为了编译前的一个安全检查,所以add方法为什么会报错实际和编译器的检查规则有关:
1、当定义为List时,也就是对加入的元素进行了上限限制,表示可以加入的元素是XXX和XXX的子类,此时编译器是不知道这个类型具体是哪一个的,编译器是很怕死的,于是为了类型安全和类型自动转换,编译器就禁止add除了null以外任何类型,举个例子:Integer和Double都extends了Number,那么当list定义为List时,add(100)是禁止的,因为你这个100到底是是Integer还是Double?
那可能会疑惑,add都不能用了,那肯定也没元素能取出来了,那这个list有什么意义呢,别忘了它是可以被赋值并取出元素的:
List list2 = new ArrayList<孙子>();
List<孙子> list3 = new ArrayList<>();
孙子 sunzi = new 孙子();
list3.add(sunzi);
list2 = list3;
System.out.println(list2.get(0) );
//打印:decorator.MainTest$孙子@60e53b93
也就是说? extends这个限定是具有只读特性的!
2、当定义为List时,也就是对加入的元素进行了下限限制,此时可以加入的元素是XXX和XXX的父类,XXX的父类可能很多,鬼知道你要传哪一个,因此此时编译器还是不知道你传的具体类型是哪一个,所以不允许add这个XXX类的父类,即使是Object这个上帝父类也不行,那么为什么允许add这个XXX类的子类呢?因为java中继承的特性,XXX类的子类可以被看做XXX类,所以可以被当做XXX存放进去,只要不是XXX类的父类就行,因为编译器不知道你要放哪个父类,它怕死啊。
那么原始类型是什么呢?就是泛型被擦除后的类型(如果没有限定就是Object,有限定就是限定后的第一个)因为字节码文件是被类型擦除后的,所以我们看一下字节码文件:
List list = new ArrayList<父亲>();
List list2 = new ArrayList<孙子>();
因为两个list我是直接定义在main方法中,所以去找一下main方法的局部泛型变量表(LocalVariableTypeTable这个表是专门保存泛型变量签名的)看一下这两个list的原始类型:
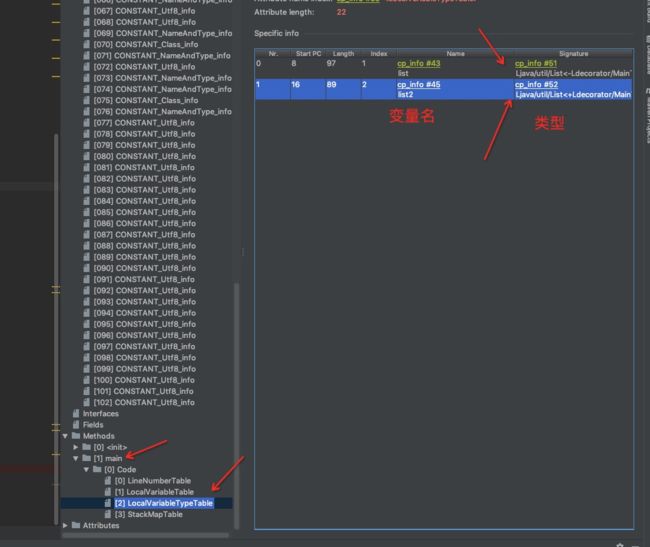
这里类型没有显示完整,但是告诉我们对应的是51和52索引的常量,我们跳转过去看一下:


其中“儿子”就是原始类型:
“+”表示的就是“? extends”,表示上限限定,不可写;
“-”表示的就是“? super”,表示下限限定,可写入其和其子类。
在原始类型这一块,kotlin和java使用上有一些不同,因为kotlin一开始就被设计成是有泛型概念的,所以kotlin中泛型定义是不支持把泛型定义成不指定类型的,你必须要指定泛型类型,举例:
java中可以不指定泛型类型,表示这个列表中可以存放任意类型:
List numberList = new ArrayList<>(); //编译通过
而kotlin不能这么写,必须指定泛型类型:
val numberList:MutableList = mutableListOf() //编译报错:One type argument expected for interface MutableList
val numberList:MutableList = mutableListOf() //正确写法
val numberList = mutableListOf() //正确写法
在kotlin中,消费者(逆变)用关键字in,相当于java中的super;生产者(协变)用关键字out,相当于java中的extends。
(对于in和out两个关键字,个人记忆的方式:协变是生产者,生产者是输出生成的东西,所以是out,相反逆变是消费者,消费者是消费进来的东西,就是in。其实out和in分别也对应着函数的返回值位置和入参位置,这是编译器强制限制的)
最后再强调一下,协变不可写,逆变可写。需要从泛型“读”用协变,需要往泛型“写”用逆变。
来对比一下java中的List
从类定义上可以看出java中的List是泛型不变的,所以可读可写,而kotlin中的List是协变的,所以只读,看一下类结构:
java.util.List:

确实是可读可写;
kotlin.collections.List:
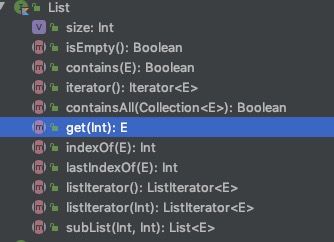
只有读的方法,没有写(add/set/remov等)的方法。
所以在kotlin中你如果想让你的列表可以动态增减数据就不能用List,而需要用无型变的MutableList。
3、kotlin中的泛型实化(泛型具体化reified)
泛型实化或者叫泛型具体化,是kotlin中对泛型扩展出的一种能力,优点是让原本会报错的一些便捷写法变成可能,比如:a as T,T::class.java
,直接的好处就是可以让你的代码写起来更便捷。举例:
比如请求网络,使用了Retrofit,一般都会写一个Retrofit的单例类,对外提供一个方法,传入某个ServiceApi的类型来生成一个serviceApi的对象。
object ServiceCreator {
private const val BASE_URL = ""
private val retrofit = Retrofit.Builder()
.baseUrl(BASE_URL)
.addConverterFactory(GsonConverterFactory.create())
.build()
fun create(serviceClass: Class): T {
return retrofit.create(serviceClass)
}
}
外部在使用的时候就写成:
ServiceCreator.create(AppService::class.java)
这样写不够便捷,::class.java这么一大段实际都是为了机器更方便阅读,对人来说不直观,利用泛型具体化来让它更便捷和直观:
再写一个方法:(泛型具体化的语法:inline和reified关键字)
inline fun create():T = create(T::class.java)
外部在使用的时候就写成:
ServiceCreator.create()
十三: Lambda
正常方法的入参都是一个个变量,lambda用白话说就是可以当方法入参的代码块。(当然你也可以把lambda表达式赋值给一个变/常量)
kotlin中Lambda表达式的语法结构:{参数1:类型,参数2:类型 ->函数体}
首先是一个大括号包裹全部,内部是参数列表,-> 符号表示参数列表结束,后面紧跟函数体,并且函数体中最后一行代码就是这个lambda表达式的返回值。
如果定一个lambda表达式的变/常量,它的类型就是很长一串:(参数1类型,参数2类型)->最后一行代码返回值类型
这其实是kotlin中的一个概念,叫做”函数类型“,是一种特殊的类型,用于高阶函数,简单的理解就是这个类型声明了一个函数的出入参类型分别是什么。
举例:
已有一个列表:val list: List
需求:定义一个取长度的Lambda并且用一个常量保存它:
val lengthLambda = {fruit:String -> fruit.length}//类型:(String)->Int
lengthLambda是常量名,大括号中有一个参数fruit,参数类型是String,函数体只有一段代码,fruit.length,所以lambda的返回值就是String。
现在需要写一个方法,接收一个lambda当做入参,返回一个列表中长度最大的值:
思路:
因为涉及到列表循环,所以我们直接用Iterable扩展函数;又因为涉及到比较,所以用于比较的那个类型一定会继承Comparable;我们用泛型来使方法适用于更多场景:
fun > Iterable.myTestMaxBy(selector: (T) -> R) : T?
上面是我们的方法定义,首先是fun关键字,表示这是一个方法;
接着<>表示这个方法是一个泛型方法,尖括号里面的内容:T,R : Comparable
再往后Iterable
继续往后,方法入参是关键,我们需要定义的是一个lambda入参,那怎么写呢?很简单,按正常的参数名:参数类型 这种格式写即可。所以参数名我们叫selector,那么参数类型是什么?它的类型按我们上面定义的lengthLambda常量可以推导出是:(T) ->R;
最后这个方法需要返回列表里面长度最大的那个值,所以返回值类型就是列表的泛型T,允许为空T?。
(myTestMaxBy方法的入参是一个函数类型,说明它是一个高阶函数)
具体实现:
fun > Iterable.myTestMaxBy(selector: (T) -> R): T? {
val iterator = iterator()
if (!iterator.hasNext()) return null//如果集合中没有元素,直接返回null
var maxElement = iterator.next()
if (!iterator.hasNext()) return maxElement//如果集合中只有一个元素。返回它
var maxValue = selector(maxElement)
do {
val element = iterator.next()
val value = selector(element)
if (value > maxValue) {
maxElement = element
maxValue = value
}
} while (iterator.hasNext())
return maxElement
}
其中if里面的比较就用到了Comparable方法的compareTo方法,可能有人说没看到compareTo呀,那是因为compareTo是一个operator方法,我们在用大于小于符号的时候其实就是再调用这个方法,不信你别让R继承Comparable,if那里就报错了。
最后可以把我们定义的lambda常量传入到这个方法中:
val lambda:(String)->Int = { fruit: String -> fruit.length }
val maxLength :String?= list.myTestMaxBy(lambda)
println("列表里名字最长的水果 = ${maxLength}")//Banana
这个方法实际上和kotlin自带的集合函数式API一样:_Collections.kt:maxBy
上面的写法可以简化一下,因为一开始我们就说,lambda就是一种可以当入参的代码块,所以不需要定义一个常量来保存它,直接把它全部复制往方法里一传就完事了:
val maxLength = list.myTestMaxBy({ fruit: String -> fruit.length })
此时IDE会给你弹出一个建议:Lambda argument should be moved out of parentheses,意思是Lambda参数应该移到圆括号外面,实际上这是Kotlin中一个规定:当Lambda参数是函数最后一个参数时候,可以把Lambda移到括号外面:
val maxLength = list.myTestMaxBy(){ fruit: String -> fruit.length }
此时括号里没有任何参数定义,括号也可以省了。
又因为Kotlin中类型会自动推导,所以fruit的类型也不用写:
val maxLength = list.myTestMaxBy { fruit -> fruit.length }
kotlin中还有一个特性:当lambda表达式的参数列表只有一个时,参数定义都不用写,可以用关键字it代替,当然这个随便你,你要是觉得定义一些参数名更直观,就保留好了:
val maxLength = list.myTestMaxBy { it.length }
可以尝试自己实现一下集合的另一个API:map。
注意其中涉及到对集合的写入,所以需要用到泛型逆变。逆变的原理在这篇文章第#十二。
列出几个常用的集合函数式API:
map:把集合元素根据条件转为另一种元素排出,和JAVA8 STREAM里的map一样。
filter:返回符合过滤条件的元素。
any:判断集合中是否至少存在一个元素满足条件,返回boolean。
all:判断集合中是否所有元素都满足条件,返回boolean。
经常能见到高阶函数这样定义:
fun SharedPreferences.edit(commit: Boolean = false, action: SharedPreferences.Editor.() -> Unit)
一、这个函数类型前面有一个“SharedPreferences.Editor.”,
1、含义和优点:首先,这也是函数类型定义的一种语法规则。
这表示把函数类型定义在了SharedPreferences.Editor这个类中,并且这个函数类型内部会自动拥有这个类的上下文。这是这种写法的一个优点,让你可以在lambda中通过this(可省略)直接调用这个类的所有可用方法。
(看起来有点像扩展函数,但是其实不是,你没法在这个高阶函数之外调用这个函数类型,因为它始终本身就是个特殊类型(函数类型))。
调用这个高阶函数:
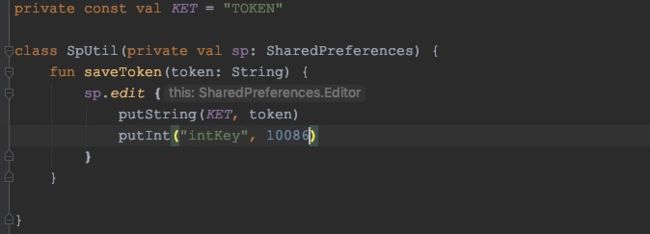
在使用的地方看到IDE提示的this类型就是SharedPreferences.Editor类。
(此时lambda中如果用it调用可以吗?答案是不行。后续分析会用到这个结论)
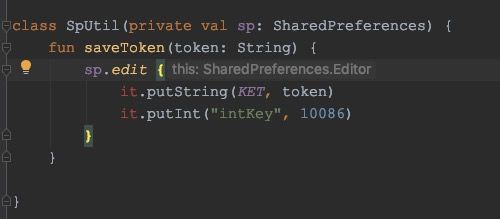
2、使用:用这种语法来定义函数类型声明时,高阶函数内部调用它时有两种写法:
fun SharedPreferences.edit(commit: Boolean = false, action: SharedPreferences.Editor.() -> Unit) {
val editor = this.edit()
action(editor)//这样调用没问题
editor.action()//这样调用没问题
}
3、原理:可以看到上面两种调用方式,一个有入参一个没有入参,我们定义的时候也是一个空的括号,那么它到底有没有入参呢?实际上是有的,看一下反编译后的代码:

首先看到原本函数类型的位置现在是一个接口类型Function1:
public interface Function1 : Function {
/** Invokes the function with the specified argument. */
public operator fun invoke(p1: P1): R
}
这个接口只有一个函数,这个函数只有1个入参(Function2表示有2个入参,其他数字同理类推),并且是个泛型接口,定义了两个泛型P1和R,分别用在了invoke方法的入参类型和返回类型。但是因为字节码的类型擦除机制导致这里是看不到具体类型(不知道类型擦除机制的,往上看第十二条)
然后两个调用的位置实际最后都被转换成了调用Function1的invoke方法。实际入参就是它所在的类的实例对象(返回参数是Unit)。
用大白话说就是你定义的函数类型被Function1类型替代了,你的函数类型调用的地方被Function1的invoke方法替代了。
再反编译调用这个高阶函数的SpUtil类:
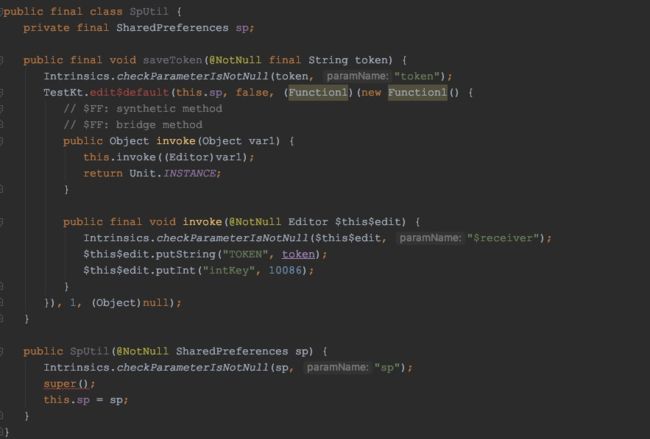
调用SharedPreferences.edit时,new了一个 Function1对象进去,并且实现了invoke方法,invoke方法的入参被强转成了Editor类型使用,最后返回一个Unit对象,invoke方法内部又调用了一个final方法(桥接),这个方法接收一个Editor类型,内部的逻辑就是我们写在lambda中的逻辑,一模一样。
用大白话说就是你在lambda中写的逻辑都被封装成另一个方法,在invoke中被调用了。
二、在函数作用不变的前提下,如果换一种定义方式呢?
1、定义:
fun SharedPreferences.edit(commit: Boolean = false, action: (SharedPreferences.Editor) -> Unit) {
val editor = this.edit()
action(editor)//这样调用没问题
editor.action()//这样调用不行
}
2、和上一种写法的区别:
这时候的action函数类型是(SharedPreferences.Editor) -> Unit,和上面写法的区别是没有把这个函数类型指定在某个类中了,那说明lambda中不可能在有这个类的上下文了,并且调用action的时候也只有传入一个SharedPreferences.Editor类型的参数才能正确编译了。
看一下反编译:

和上一个写法反编译后的逻辑没区别,同样是调用Function1的invoke方法,传入一个Editor实例。
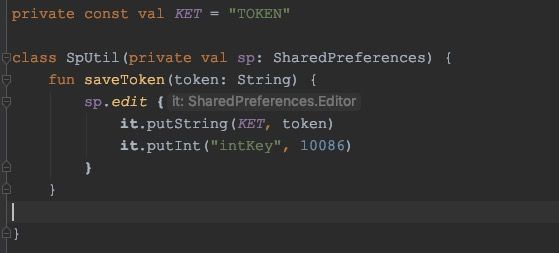
那看一下调用这个高阶函数的地方有没有什么变化:

变化很大,原先的this已经变成了it,虽然类型都还是SharedPreferences.Editor,但是已经享受不到this带来的省略写法了,putString和putInt已然飘红,需要用it.来调用它们。
把这个反编译看一下:
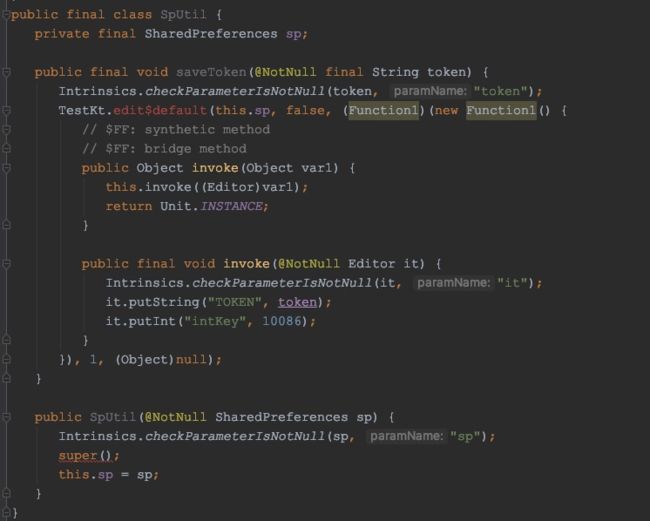
和上一个写法没有本质区别。
所以这种写法和上一种写法除了在你写lambda内部逻辑时有些区别(第一种写法可以使用this,写起来更方便),其他没有区别。
三、现在想把第一和第二种写法结合在一起,也就是在第二种写法的基础上,同时把这个函数类型给定义到SharedPreferences.Editor类中:

可以看到在使用action的两个地方都报错了:No value passed for parameter 'p2',意思是参数2没有传值。
啥也不管了直接看反编译:(先把使用action的两个地方注释了)

可以看到之前是Function1的入参变成了Function2:
/** A function that takes 2 arguments. */
public interface Function2 : Function {
/** Invokes the function with the specified arguments. */
public operator fun invoke(p1: P1, p2: P2): R
}
Function2这个接口的invoke方法有两个入参,p1和p2,所以当我们使用action(editor)时会提示我们参数2没有传值,那我们给传一下参数2:

这就不用反编译看了吧,这两个使用action的地方肯定都会转变成action.invoke(editor, editor);
那么在使用这个高阶函数的地方,lambda中是this还是it呢?
用it:
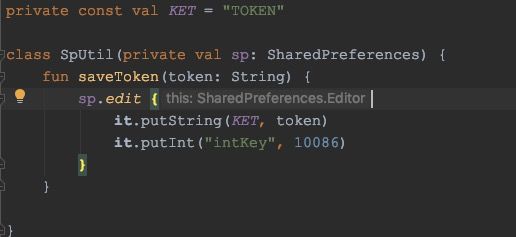
用this:

都可以!这和第一和第二种写法就有区别了,第一种写法只能用this,第二种写法只能用it。
这样其实没啥意义,只是为了分析写法的区别。/笑哭
四、现在还是用第三种写法,但是我不把函数类型定义到Editor类中,我给它换个家,给它定义到String中,看看会咋样:

反编译:

这其实可以得到一个结论:如果这个函数类型被指定到了某一个类中,那么编译后invoke的第一个入参都是这个类的实例。
注意,下面开始好玩了:
在使用这个高阶函数的地方,lambda中this和it两种方式还可以使用吗?可以使用的话this和it还是同一个类型吗?
使用it:
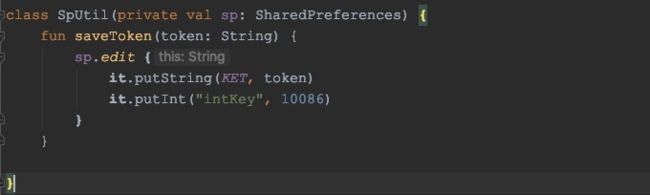

可以看到it是Editor类型。
使用this:
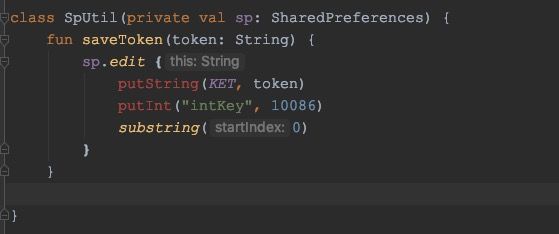
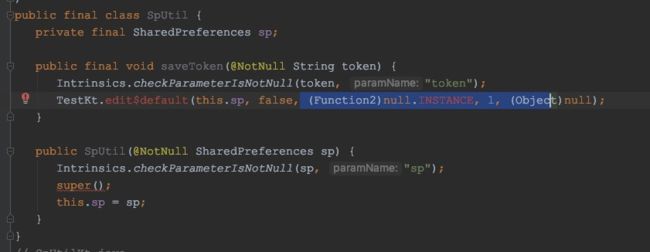
可以看到this是String类型,并且Function2传的是一个null的实例,那这样的话lambda中的内容是不是没有被执行?并不是,会被执行,不信你打个log看一下。
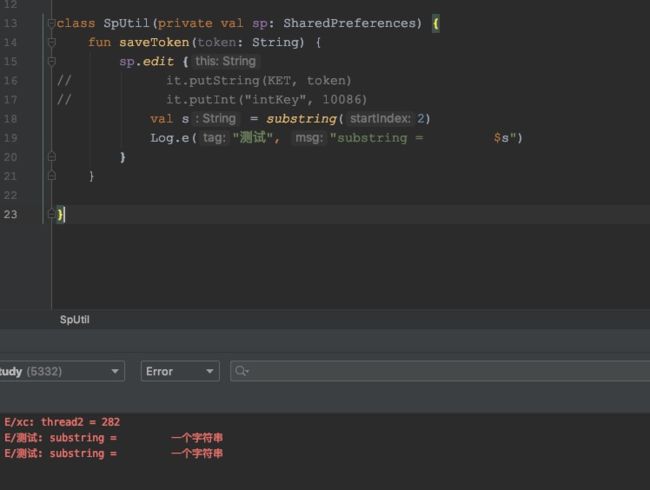
明明传进去是(Function2)null.INSTANCE,invoke方法都被看到被覆写,怎么就执行了呢?我也不知道,有知道的希望评论回复我,感谢!
最后总结下,在不涉及泛型的情况下还是用第一种(也即是把函数类型指定到某一个类中)的写法既规范又简便,使用起来更方便。
十四、密封类的作用
当你使用when时,kotlin语法会强制要求你写else,即使你能确定这个else永远用不上,这样不方便的同时会有一个很大的风险:当你新增了一个条件,但是忘记在when对应的地方添加对应条件分支,编译器也不会提醒你,这时候你新增的条件就会走到else中,这不是我们想要的,这个问题的本质就是这个else,如果不用写它就不会有这个问题,并且我还想要编译器可以提醒我去在when中添加对应条件分支,这时候就可以用密封类来解决这个问题。
当when中传入的是一个密封类,语法就允许我们不用写else,并且当你新增一个密封类的子类时,编译器会报错,提醒你要在when中增加对应的条件分支。
十五、可见性控制
什么叫可见性,举个安卓源码中的例子:ActivityThread是一个public的类,但是应用层开发者却访问不到这个类,因为用了可见性注解修饰@hide,表示其不作为对外Api被访问。
在kotlin中对应internal关键字,比如在某个module中给某个类加了internal关键字,module中可以用这个类,但是在你的app工程就无法使用这个类了。