C# WinForm程序 PDF文档分割代码实现
C#使用itextsharp对PDF分割处理
程序运行界面:
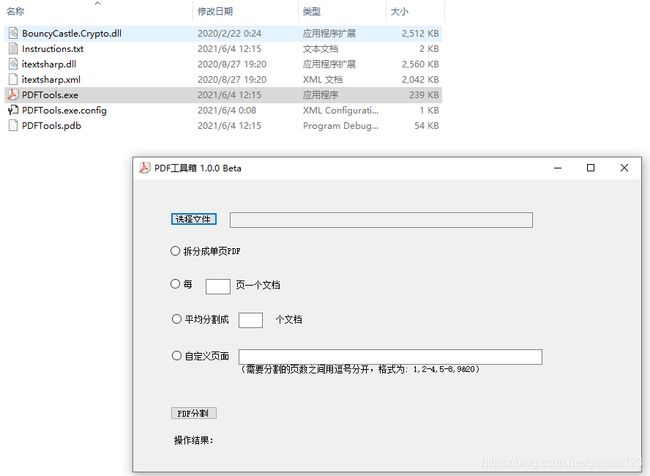
PDF分割操作共有以下几个步骤:
1.运行文件夹里面的PDFTools.exe文件
2.点击浏览按钮选择需要分割的PDF文件
3.选择分割方式,可以分割成单页的文档,或者固定多少页一个文档,或者自定义每个文档的页数
4.点击分割后,新的文件会生成在原始PDF的路径
PDF分割功能说明
能快速方便的把一个PDF文件任意分割成你所设想的多个PDF文件,简单、高效;一键操作,快速、方便
可以把文件转换成单页的PDF,比如一个文件有20页,就可以分割成20个文件
也可以分割成固定页数一个文档,比如20页的文档分割成每5页一个文档,就是拆分成4个文档
当然页可以自定义页面分割,
比如 1-5,6-8 这样就是分割成3个文档,分别是第1页到第5页的内容合并到一个文档、第6页到第8页的内容合并到一个文档。
比如 1&3,3&10 这样就是分割成2个文档,分别是第1页和第3页的内容合并到一个文档,第3页和第10页内容合并到一个文档。
比如 1&2,1&2,3-5,14 这样就是分割成5个文档,分别是第1页和第2页的内容合并到一个文档,第1页和第2页内容合并到一个文档、第3-5页的内容合并到一个文档、第14页单独一个文档。
PDF文档分割 关键性代码
using System;
using System.Collections.Generic;
using iTextSharp.text;
using iTextSharp.text.pdf;
using System.Text;
namespace PDFTools
{
///
/// 从已有PDF文件中拷贝指定的页码范围到一个新的pdf文件中 使用pdfCopyProvider.AddPage()方法
///
/// 文件路径+文件名
public void SplitPDF(string sourcePdfPath, string outputPdfPath, int startPage, int endPage)
{
PdfReader reader = null;
Document sourceDocument = null;
PdfCopy pdfCopyProvider = null;
PdfImportedPage importedPage = null;
try
{
reader = new PdfReader(sourcePdfPath);
sourceDocument = new Document(reader.GetPageSizeWithRotation(startPage)); pdfCopyProvider = new PdfCopy(sourceDocument, new System.IO.FileStream(outputPdfPath, System.IO.FileMode.Create));
sourceDocument.Open();
for (int i = startPage; i <= endPage; i++)
{
importedPage = pdfCopyProvider.GetImportedPage(reader, i); pdfCopyProvider.AddPage(importedPage);
}
sourceDocument.Close();
reader.Close();
}
catch (Exception ex) {
throw ex; }
}
///
/// 将PDF文件分割成单页
///
/// 文件路径+文件名
public void Split2SinglePage(string sourcePdfPath)
{
PdfReader reader = null;
try
{
string fileNameWithoutExtension = System.IO.Path.GetFileNameWithoutExtension(sourcePdfPath);
string outputPdfFolder = System.IO.Path.GetDirectoryName(sourcePdfPath);
reader = new PdfReader(sourcePdfPath);
for (int i = 1; i <= reader.NumberOfPages; i++)
{
PdfCopy pdfCopyProvider = null;
PdfImportedPage importedPage = null;
Document sourceDocument = null;
string outputPdfPath = outputPdfFolder + "\\" + fileNameWithoutExtension + "_" + i + ".pdf";
sourceDocument = new Document(reader.GetPageSizeWithRotation(i));
pdfCopyProvider = new PdfCopy(sourceDocument, new System.IO.FileStream(outputPdfPath, System.IO.FileMode.Create));
sourceDocument.Open();
importedPage = pdfCopyProvider.GetImportedPage(reader, i);
pdfCopyProvider.AddPage(importedPage);
sourceDocument.Close();
}
reader.Close();
}
catch (Exception ex) {
throw ex; }
}
///
/// 将PDF文件平均分割成多个文件,无法分尽,剩余页数就加到最后一个文档
///
/// 文件路径+文件名
/// 需要生成的文档数量
public void Split2AveragePage(string sourcePdfPath, int count)
{
PdfReader reader = null;
try
{
string fileNameWithoutExtension = System.IO.Path.GetFileNameWithoutExtension(sourcePdfPath);
string outputPdfFolder = System.IO.Path.GetDirectoryName(sourcePdfPath);
reader = new PdfReader(sourcePdfPath);
// int page = (reader.NumberOfPages / count);
// 计算每个文档的页数,总是舍去小数
int page = (int)Math.Floor((double)(reader.NumberOfPages) / (double)(count));
int startPage = 1;
int endPage = 1;
LogUtil.WriteLog("每个文档的页数:" + page.ToString());
for (int i = 1; i <= count; i++)
{
string outputPdfPath = outputPdfFolder + "\\" + fileNameWithoutExtension + "_" + i + ".pdf"; ;
if (i == 1)
{
startPage = 1;
endPage = page;
}
else
{
startPage = endPage + 1;
endPage = startPage + page - 1;
}
if (startPage > reader.NumberOfPages)
break;
if (endPage > reader.NumberOfPages)
endPage = reader.NumberOfPages;
if (i == count)
endPage = reader.NumberOfPages;
LogUtil.WriteLog(outputPdfPath + " > " + startPage.ToString() + "-" + endPage.ToString());
SplitPDF(sourcePdfPath, outputPdfPath, startPage, endPage);
}
reader.Close();
}
catch (Exception ex) {
throw ex; }
}
///
/// 将PDF文件按文档固定页数割成多个文件
///
/// 文件路径+文件名
/// 每个文档页数
public void Split2Page(string sourcePdfPath, int page)
{
PdfReader reader = null;
try
{
string fileNameWithoutExtension = System.IO.Path.GetFileNameWithoutExtension(sourcePdfPath);
string outputPdfFolder = System.IO.Path.GetDirectoryName(sourcePdfPath);
reader = new PdfReader(sourcePdfPath);
// int page = (reader.NumberOfPages / count);
// 计算按固定页数生成文档的数量 只要有小数都加1
int count = (int)Math.Ceiling((double)(reader.NumberOfPages) / (double)(page));
int startPage = 1;
int endPage = 1;
LogUtil.WriteLog("文档数量:" + count.ToString());
for (int i = 1; i <= count; i++)
{
string outputPdfPath = outputPdfFolder + "\\" + fileNameWithoutExtension + "_" + i + ".pdf"; ;
if (i == 1)
{
startPage = 1;
endPage = page;
}
else
{
startPage = endPage + 1;
endPage = endPage + page;
}
if (startPage > reader.NumberOfPages)
break;
if (endPage > reader.NumberOfPages)
endPage = reader.NumberOfPages;
if (i == count)
endPage = reader.NumberOfPages;
LogUtil.WriteLog(outputPdfPath + " > " + startPage.ToString() + "-" + endPage.ToString());
SplitPDF(sourcePdfPath, outputPdfPath, startPage, endPage);
}
reader.Close();
}
catch (Exception ex) {
throw ex; }
}
///
/// 从已有PDF文件中拷贝指定的页码范围到一个新的pdf文件中 使用pdfCopyProvider.AddPage()方法
///
/// 文件路径+文件名
/// 自定义的页数范围
public void SplitPDFCustPage(string sourcePdfPath, string custpages)
{
// string[] strArray = custpages.Trim().Split(",");
string[] strArray = custpages.Trim().Split(new Char[] {
',' });
string fileNameWithoutExtension = System.IO.Path.GetFileNameWithoutExtension(sourcePdfPath);
string outputPdfFolder = System.IO.Path.GetDirectoryName(sourcePdfPath);
int startPage;
int endPage;
for (int i = 0; i < strArray.Length; i++)
{
LogUtil.WriteLog("自定义页面范围:" + strArray[i]);
// 横杠-相连的页码,抽取连续的范围内的页码生成到一个文档
if (strArray[i].Contains("-"))
{
// string[] array = strArray[i].Split("-");
string[] array = strArray[i].Split(new Char[] {
'-' });
startPage = int.Parse(array[0]);
endPage = int.Parse(array[1]);
string outputPdfPath = outputPdfFolder + "\\" + fileNameWithoutExtension + " " + startPage + "-" + endPage + ".pdf";
LogUtil.WriteLog(outputPdfPath);
SplitPDF(sourcePdfPath, outputPdfPath, startPage, endPage);
}
// and &相连的页码,抽取指定页码生成到一个文档
else if (strArray[i].Contains("&"))
{
// int[] intArray = Array.ConvertAll(strArray[i].Split("&"), int.Parse);
int[] intArray = Array.ConvertAll(strArray[i].Split(new Char[] {
'&' }), int.Parse);
string pages = string.Join("&", intArray);
string outputPdfPath = outputPdfFolder + "\\" + fileNameWithoutExtension + " " + pages + ".pdf";
LogUtil.WriteLog(outputPdfPath);
SplitPDF2ExtractPages(sourcePdfPath, outputPdfPath, intArray);
}
else
{
startPage = int.Parse(strArray[i]);
endPage = int.Parse(strArray[i]);
string outputPdfPath = outputPdfFolder + "\\" + fileNameWithoutExtension + " " + strArray[i] + ".pdf"; ;
LogUtil.WriteLog(outputPdfPath);
SplitPDF(sourcePdfPath, outputPdfPath, startPage, endPage);
}
}
}
///
/// 将已有pdf文件中 不连续 的页拷贝至新的pdf文件中。其中需要拷贝的页码存于数组 int[] extractThesePages中
///
/// 文件路径+文件名
/// 页码集合
/// 文件路径+文件名
public void SplitPDF2ExtractPages(string sourcePdfPath, string outputPdfPath, int[] extractThesePages)
{
PdfReader reader = null;
Document sourceDocument = null;
PdfCopy pdfCopyProvider = null;
PdfImportedPage importedPage = null;
try
{
reader = new PdfReader(sourcePdfPath);
sourceDocument = new Document(reader.GetPageSizeWithRotation(extractThesePages[0]));
pdfCopyProvider = new PdfCopy(sourceDocument, new System.IO.FileStream(outputPdfPath, System.IO.FileMode.Create));
sourceDocument.Open();
foreach (int pageNumber in extractThesePages)
{
importedPage = pdfCopyProvider.GetImportedPage(reader, pageNumber); pdfCopyProvider.AddPage(importedPage);
}
sourceDocument.Close();
reader.Close();
}
catch (Exception ex)
{
throw ex;
}
}
}
}
代码会后续开源,上传到github。