拉链工具
1 拉链工具介绍
1.1 为什么要有拉链工具
拉链表,是维护历史状态,以及最新状态数据的一种表,实际是保留了任意一条数据从创建、到不断完成更新的整个生命周期,它对于数仓的建设有着重要意义。过去,我们基于sql实现的(以下统称为sql版)拉链表任务执行速度慢,资源耗费大,进而影响了同时段集群其它任务的执行;为优化拉链表整体任务,从拉链表任务执行效率、集群资源利用与开发成本方向出发,使用spark rdd 开发了一套拉链表工具(以下统称为rdd版),其包含了维度表、事实表拉链两种逻辑。
1.2 支持的几类表
拉链工具支持两类表,维度表和事实表,全部采用二级静态分区;
一级分区为天 dt ,即按天分区;
二级分区为 status,即状态分区,值为hot 或 cold ;
表种类不同,分区逻辑不同,回滚策略也不同。
1.2.1 维度表
维度表,就是基础表。相比事实表来说,一般不大。T+1处理, 每天滚动一个全量分区,以ods数据是否变化决定数据进入哪个状态分区,ods变化的进入hot分区,ods无变化的进入cold分区。回滚时,按照dt去drop掉dt分区即可。
1.2.2 事实表
事实表,就是交易表,一般都很大。 T+1 处理,dt分区由数据的创建时间决定,根据ods数据每天做增量处理。以数据是否闭链决定数据进入哪个状态分区,闭链数据进入cold分区,开链数据进入hot分区。回滚时,需要删除增量数据,不再能简单的drop掉dt分区。
对于事实表,拉链工具还记录了一张change表,change表记录了事实表里哪些分区的数据发生了变化。
2 实现方式比对
2.1 维度表
对比数据取自azkaban一周的任务执行记录(2019-12-06 至 2019-12-12)
sql版中代码逻辑只对supplier_id一个维度做了拉链
rdd版中代码逻辑对phone,supplier_id,status三个维度同时做了拉链
数据源表:ods.ods_yc_car_biz_driver_info_zip
sql版本与rdd版本实现逻辑基本一致,区别在于sql的语法和rdd算子选用的不同。
2.1.1 效率

sql版时长:1m 40s
rdd版时长 : 67s
| 分类 | 提升(%) |
|---|---|
| 时长提升(节约) | 33% |
提升(%)= ( a - b ) /a , a为优化前值 ,b为优化后值。
2.1.2 资源

sql版资源: 16c 21g
rdd版资源 : 16c 9g
| 分类 | 提升(%) |
|---|---|
| 资源提升(节约) | 57% |
提升(%)= ( a - b ) /a , a为优化前值 ,b为优化后值。
2.1.3 成本
开发人员只需设计拉链表结构、填写配置项;无需书写大篇sql代码,数据量核对以及拉链准确性校验。这极大提升了开发效率,降低了开发成本。
2.2 事实表
对比数据取自azkaban一周的任务执行记录
sql版取自 2019-07-01 至 2019-07-07
rdd版取自 2019-12-05 至 2019-12-11
数据源表:ods.ods_yc_car_fact_order_zip ,仅对status字段做拉链处理
sql版实现逻辑
| 任务拆解 | job |
|---|---|
| 获取源表快照数据 | dwb_yc_car_biz_fact_order_his_01 |
| 目标表数据拆分 | |
| ... | dwb_yc_car_fact_order_his_h0_02 |
| ... | dwb_yc_car_fact_order_his_h0_03 |
| ... | dwb_yc_car_fact_order_his_h1_02 |
| ... | dwb_yc_car_fact_order_his_h1_03 |
| ... | dwb_yc_car_fact_order_his_h2_02 |
| ... | dwb_yc_car_fact_order_his_h2_02_not_need |
| ... | dwb_yc_car_fact_order_his_h2_03 |
| ... | dwb_yc_car_fact_order_his_h2_03_not_need_1 |
| ... | dwb_yc_car_fact_order_his_h2_03_not_need_2 |
| ... | dwb_yc_car_fact_order_his_h2_03_not_need_3 |
| 拉链处理 | |
| ... | dwb_yc_car_fact_order_his_z0 |
| ... | dwb_yc_car_fact_order_his_z1 |
| ... | dwb_yc_car_fact_order_his_z2 |
以上 job 被拆解为三个部分:
从ods表里根据order_id开窗,按照status、创建时间、更新时间、offset降序排列取最新的一条数据
根据创建时间拆解分为 365天之前、180 - 365天、120 - 180天、60 - 120天、60天之内等时间块,从目标表对应的dt、active和history分区里取所有的数据,并行处理加快任务的执行
-
数据合并、开窗、lag ,最后根据是否闭链动态分区到对应dt 的active 或者history 分区
sql版慢在哪里?
多job并行的运算带来的是多倍资源的消耗
目标表数据被拆分成了10个部分,每个job的完成都伴随一张临时表的生产,中间数据的落地必然会影响任务的执行速度
-
拉链处理中,闭链的数据又重新参加拉链,带来不必要的任务消耗
rdd版实现逻辑
取ods表所有数据的创建时间值,并去重,得到拉链表里哪些分区的数据发生了变化
根据变化的分区,找到拉链表对应的分区目录,逐个加载数据合并拉链表
ods表数据与拉链表做全外链接,拉链逻辑处理
-
save rdd
2.2.1 效率
- sql版任务时长
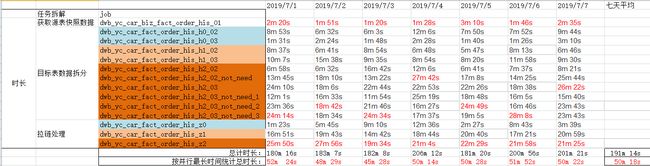
总计时长:所有job耗费的时长加和。
按并行最长时间统计总时长:取每个被拆解任务中最长执行时间,加和。(图中红色部分)
- rdd版任务时长

-
效率提升
sql版总时长:191m 14s
sql版按并行最长时间统计总时长:50m 18s
rdd版总时长:21m
分类 提升(%) 总时长提升(节约) 89% 并行最长时长提升(节约): 58% 提升(%)= ( a - b ) /a , a为优化前值 ,b为优化后值。
2.2.2 资源
- sql版资源使用
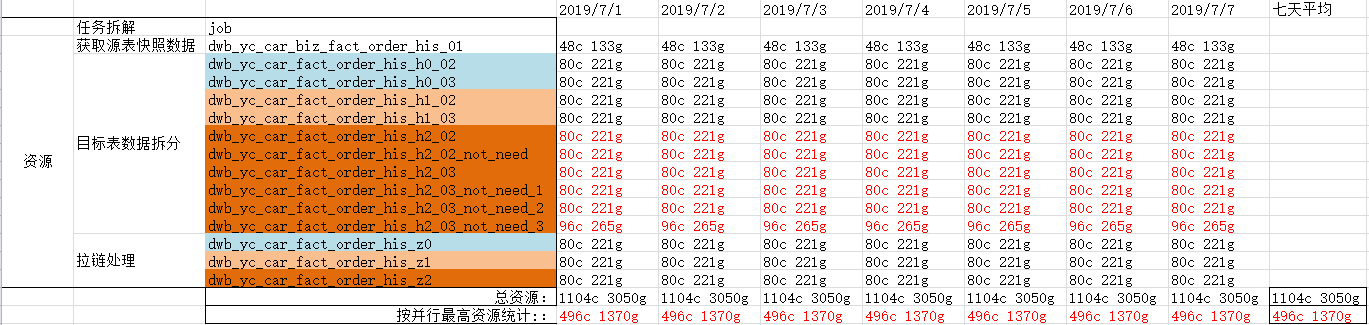
总资源:所有job耗费的资源加和。
按并行最高资源统计:同一时刻并行最大资源使用量。(图中红色部分)
- rdd版资源使用

- 资源使用提升
sql版总资源::1104c 3050g
sql版按并行最高资源统计:496c 1370g
rdd版总资源:80c 81g
| 分类 | 内存提升(%) | cpu提升(%) |
|---|---|---|
| 总资源提升(节约): | 97% | 92% |
| 并行最高资源接收(节约): | 94% | 83% |
提升(%)= ( a - b ) /a , a为优化前值 ,b为优化后值。
2.2.3 成本
开发人员只需设计拉链表结构、填写配置项;无需书写大篇sql代码,数据量核对以及拉链准确性校验。这极大提升了开发效率,降低了开发成本。
3 使用说明
3.1 维度表拉链
步骤1:创建表 zipper.ods_yc_car_biz_driver_info_zip
drop table zipper.ods_yc_car_biz_driver_info_zip;
CREATE TABLE zipper.ods_yc_car_biz_driver_info_zip(
driver_id bigint,
name string,
phone string,
supplier_id bigint,
status int,
update_date string,
create_date string,
bigdata_inner_utime string,
bigdata_inner_offset bigint,
enter_state_time string,
quit_state_time string
)
partitioned BY (
dt string,
bigdata_inner_status string
) ROW format delimited FIELDS TERMINATED BY '\001' LINES TERMINATED BY '\n' stored AS textfile;
步骤2:设置配置文件参数
{
"appName":"ods_yc_car_biz_driver_info_zip",
"source":{
"primaryColumn":"driver_id",
"schemaName":"ods",
"tableName":"ods_yc_car_biz_driver_info",
"partitionVal":""
},
"dimensionTarget":{
"primaryColumn": "driver_id",
"schemaName": "zipper",
"tableName": "ods_yc_car_biz_driver_info_zip",
"partitionVal":"",
"targetPartitionVal":""
},
"zipPolicy":{
"defaultZipperLastValue":"2999-12-31",
"enterStateColumn":"enter_state_time",
"quitStateColumn":"quit_state_time",
"sourceTableUpdateTimeColumn":"bigdata_inner_utime",
"zipBaseColumnList":["phone","supplier_id","status"],
"mappingColumnList":[{
"sourceColumn":"",
"targetColumn":""
}],
"orderByColumnList":[{
"name":"bigdata_inner_utime",
"type":"desc"
},{
"name":"bigdata_inner_offset",
"type":"desc"
}]
}
}
3.2 事实表拉链
步骤1:创建两张表
表一: 拉链表 zipper.ods_yc_car_fact_order_zip
drop table zipper.ods_yc_car_fact_order_zip;
CREATE TABLE zipper.ods_yc_car_fact_order_zip(
order_id bigint,
order_no string,
type int,
status bigint,
create_date string,
update_date string,
bigdata_inner_utime string,
bigdata_inner_offset bigint,
enter_state_time string,
quit_state_time string
)
partitioned BY (
dt string,
bigdata_inner_status string
) ROW format delimited FIELDS TERMINATED BY '\001' LINES TERMINATED BY '\n' stored AS textfile;
表二: 记录事实表里发生变化的分区的表 zipper.ods_yc_car_fact_order_zip
drop table zipper.ods_yc_car_fact_order_zip_changed;
CREATE TABLE zipper.ods_yc_car_fact_order_zip_changed(
changed string comment '事实表里发生变化的分区'
)
partitioned BY (
dt string
) ROW format delimited FIELDS TERMINATED BY '\001' LINES TERMINATED BY '\n' stored AS textfile;```
步骤2:设置配置文件参数
{
"appName":"ods_yc_car_fact_order_zip",
"coalesce": 5,
"source":{
"primaryColumn":"order_id",
"schemaName":"ods",
"tableName":"ods_yc_car_fact_order",
"partitionVal":""
},
"factTarget":{
"primaryColumn": "order_id",
"schemaName": "zipper",
"tableName": "ods_yc_car_fact_order_zip"
},
"zipPolicy":{
"defaultZipperLastValue":"2999-12-31",
"enterStateColumn":"enter_state_time",
"quitStateColumn":"quit_state_time",
"sourceTableUpdateTimeColumn":"bigdata_inner_utime",
"zipBaseColumnList":["status"],
"partitionValPolicy":{
"columnName":"create_date",
"start":0,
"end":10
},
"mappingColumnList":[{
"sourceColumn":"",
"targetColumn":""
}],
"orderByColumnList":[{
"name":"bigdata_inner_utime",
"type":"desc"
},{
"name":"bigdata_inner_offset",
"type":"desc"
}]
}
}
3.3 事实表拉链回滚
--rollback-schema-name ${库名}
--rollback-table-name ${表名}
--rollback-to ${要回滚到的对应的分区值} , 默认值是前一天
示例:
if [ $# == 1 ]; then
rollbackTo=$1
else
rollbackTo=$(date -d"2 day ago" +%Y-%m-%d)
fi
echo "接收到参数:rollbackTo="$rollbackTo
spark-submit --class com.sqyc.bigdata.etl.zip.rollback.fact.FactZipRollbackMain \
--master local \
../platform-util-zip-1.0-SNAPSHOT-jar-with-dependencies.jar --rollback-schema-name zipper --rollback-table-name ods_yc_car_fact_order_zip --rollback-to $rollbackTo