大家共同修补打造适合我们自己团队的“开发手册”。这样我们编写的代码无论谁读起来都好像一个人写的,后续不管是项目移交、维护、优化重构、版本迭代、紧急代替开发 都会省劲许多,不会受过多的个人编码习惯的限制。
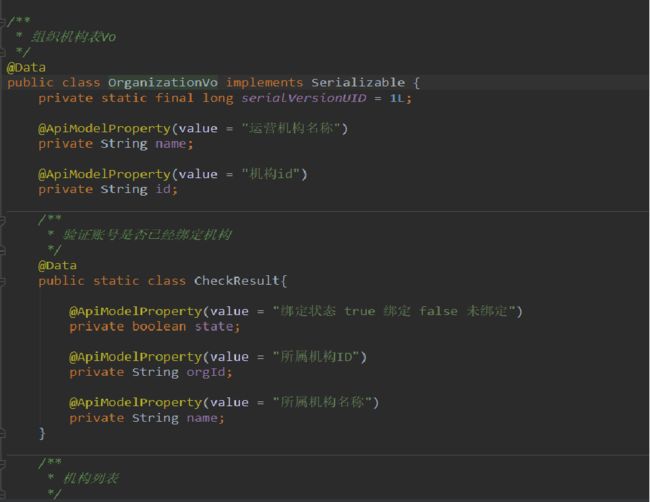
关于模型类定义
对于常用领域模型统一规约
数据映射对象:xxxDO (xxx为表名,如:OrderDetail)
数据传输对象:xxxDTO (xxx为业务领域,如:UserAddress)
数据显示对象:xxxVO (xxx为页面/接口名称,如:OrderInfo)
另,POJO 是 DO / DTO / BO / VO 的统称,我们一般不会对某类命名为 xxxPOJO
首先强烈要求不能将映射对象全属性返回前端/服务调用者 所以swagger等文档插件的注解最好不要加到映射对象里。
区分命名并建立不同的包路径管理有助于目录结构的清晰,降低项目的整体维护难度,不会出现随意命名又混合管理弊端,如:多个接口混用同一出参类,改动时为了不影响其余功能,只能多加字段,导致一个类变得属性很多维护起来很难处理。或者为每个接口都定义一个出参类,这样违背了代码复用的原则,也很容易重复编码。
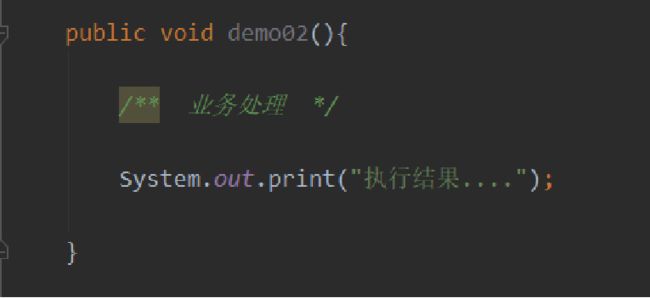
TODO 标记
特别是在项目开发初期,需求多功能杂,编程人员的开发习惯大多是一条主业务写到底,这期间对于次要业务顺手打个待实现标记,不用过多精力关注分支业务,待一条业务写完,回过头直接填充待办业务,开发工具也可以设置提醒。有利于提高代码开发质量和速度。

日志
一个项目必不可少的元素,是针对程序出现预料之外错误时的唯一有效定位和排错手段。无论项目大小,需要优先完善日志功能,对于后续开发收益甚大。包括对于关键功能错误日志预警、集成Kibana Elasticsearch 做大量的规范数据日志采集分析等。
建议集成logback 日志插件 ,功能性和执行效率优于log4j ,配置简单使用方便,基本可以满足大部分项目的日志需求。
所以切勿程序中不打印日志或使用System直接输出。
当然日志细讲起来就很庞大了,我们只需要遵循基本的约定即可。
不可以打印敏感信息如银行卡号、账号、密码等
不可以随意配置日志级别,影响日志文件的大小和信息安全
debug 开发阶段的打印级别非常详细,包括执行sql等
info 主要记录 关键节点流转深度 或 关键参数
warn 记录一些非规范异常,比如用户输入错误的账号密码验证码等
error 主要记录报错信息
日志文件应该适当保留15天,因为有些bug复现周期较长,超过15天的文件应压缩统一保存,节约磁盘空间。
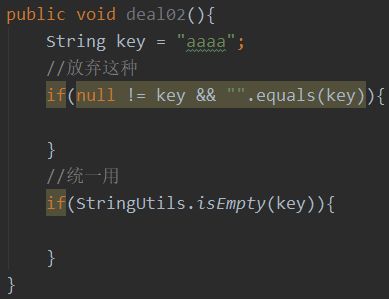
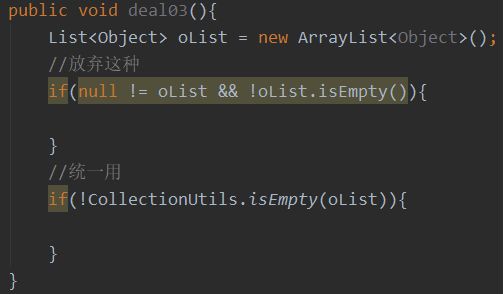
校验统一
避免重复造轮子,请直接使用
CollectionUtils、ListUtils、SetUtils、MapUtils、StringUtils ...
来判断 List Set Map String ,校验不要每次都写 不为null & 不为空
有兴趣可以看下utils 工具类的源码 基本包含了我们能想到的所有验证,足够可靠
常量管理
针对常量,或者是缓存key前缀等 需要统一管理,方便维护和扩展。
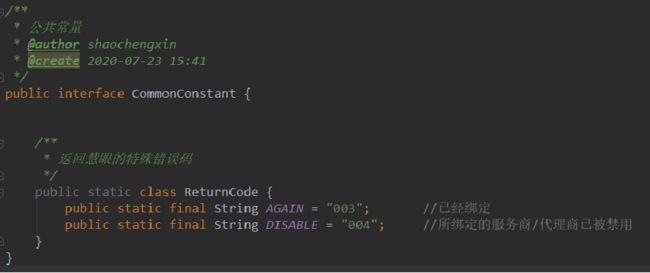
else 的使用
尽量少用else;
if(条件){}else{} 的方式都可以换为if(){return;}//继续 的方式;
就算一定要用else 方式 深度不可超过三层(强制要求)因为一般人读三层以上的代码都很难记住前面的支线逻辑;

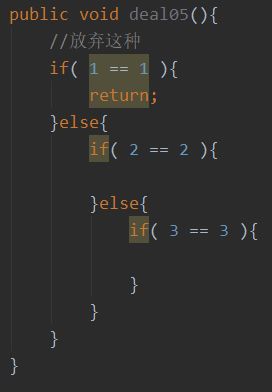
代码锁
锁 是一个很复杂的功能概念,对于在单机项目、集群项目、分布式项目中的锁应用都不尽相同,但是理念是一致的,都是为了在资源争竞情况下为数据一致性提供保证。
对于锁,锁的粒度越大,对程序性能的影响就越大,但是对数据就越安全,那为什么不对所有代码都加同步锁呢,虽然数据安全是保证了,但那样项目就成了个串行项目,不能支持多线程请求。所以锁资源的选择、粒度的选择、锁定/释放顺序的问题就需要格外注意。
简单来说 ,在满足业务需求的情况下,锁的粒度越小,性能影响越小,所以代码中尽可能的能不用锁就不用,能锁区块就别锁方法,能锁对象,就别锁类。
对于多资源加锁来说 ,加锁顺序必须一致,A线程对 资源1 和 资源2 加锁成功后执行逻辑,那么B线程加锁顺序也必须是先1后2,否则就可能出现死锁。应避免。
在单机项目中,资源争竞来自于多线程请求。推荐使用synchronized关键字加锁(jdk1.6之后java对它进行了优化,从轻量锁-自旋锁-重量锁的转化,不再是直接加锁就直接切换内核管理)。
在集群项目中,资源争竞来自于多应用请求。推荐使用分布式锁的思路。

事务
也是区分项目类型来说的,如果是单机项目@Transactional 注解是比较简单方便的开启事务的方式 ,对于分布式项目来说,需要自己写手动回滚方案或者借助一些成熟的事务框架如LCN等。
单机项目的事务是保证同一数据库同时操作多个资源变更的数据一致性问题。
分布式事务是保证不同数据库不同资源变更的最终一致性问题。
无论是单机的注解,还是分布式的事务框架,使用起来都很简易上手,这些在应用的时候学习一下就好,以后也可以拎出来单独做分享,这里要特别提一下的是:
A 对于事务不要滥用,加事务就势必影响数据库的QPS,性能施压,所以纯查询类的方法就不要加事务了;
B 对于事务补偿,不是仅将数据库的已提交未入库的数据回滚即可,实际情况是,在大型项目的开发中,很多地方都需要手动回滚事务,以及处理事务失败后影响到的所有功能,包含不仅限 缓存回滚、搜索引擎回滚、消息补偿、统计修正等等;
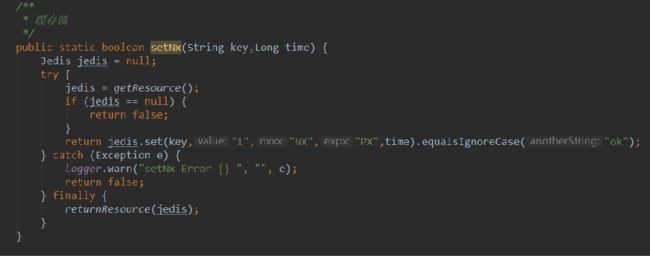
C 在实际开发过程中,需要注意事务传播和失效的问题。
例如,调用如下方法,如果调用方法没有事务,那么这个方法的事务注解是无效的。
异常
关于在编码中对待异常的方式,思路要清晰,重复和混淆往往不能达到我们预期的处理结果。
不要对异常进行捕获但不进行任何处理,最起码要打印异常信息;
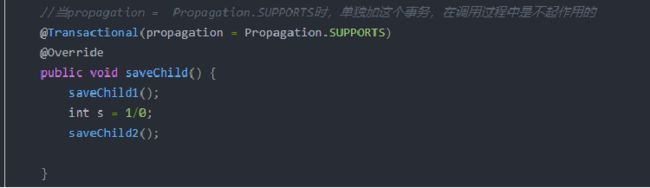
不能对大片的代码进行try catch 要分清哪些是稳定代码,哪些是容易出现异常的代码, try的代码块尽可能小,捕获的异常类型也要尽可能精确,比如对文件流的操作捕获IO异常等;
尽可能使用全局异常来拦截对外请求(对应web端、其他服务调用),在我们程序出现预期外的错误时,不能展示给调用方NEP等错误明细,统一异常捕获返回包括错误编码、错误信息 的消息体;
在使用了全局异常捕获后,如果又手动加了try 且希望请求因为该异常而停止,请主动将异常抛往异常切面层用于返回统一异常,直接return 和 不抛出,并不会触发全局异常处理。
如下,try代码块小,捕获异常明确,打印异常信息,中断并抛给上层:

接口规范
对于rest风格一直是比较流行的一种请求交互规范:
GET (SELECT):从服务器取出资源(一项或多项)
POST(CREATE):在服务器新建一个资源
PUT(UPDATE):在服务器更新资源(客户端提供改变后的完整资源)
PATCH(UPDATE):在服务器更新资源(客户端提供改变的属性)
DELETE(DELETE):从服务器删除资源
rest风格认为,任何信息都是一种“资源”,所以在定义请求路径的时候不要出现动词(如get/delete/select等),遵循用名词来拼接的规范,而对于请求路径的规范我们也应该约定,比如:
根路径{address}
GET {address}/customers 获取所有客户信息
POST {address}/customers 新增客户
GET {address}/customers/id 获取指定客户信息
PATCH {address}/customers/phone 更新某客户的手机号
同时对于不同环境 或者 不同版本应该在根路径加入环境参数或者版本参数,对此请参照腾讯 阿里 的开放文档,基本都是带版本号的,这样有利于服务管理和切换。
部分数据库相关的细节(mysql)
现在我们默认数据库表和字段都采用下划线拼接
表名 模块_业务 account_flow
字段 单词数<3 user_account_id
映射对象采用驼峰规则,并在项目中配置下划线驼峰的转换。
为了防止精度丢失,小数类型都用decimal,特别是金额
不要使用外键、级联(除非银行项目),效率太低了,互联网项目的任何外键概念都应该放在应用层约束。
请放心使用索引(但是单表不建议超过5个,否则影响增删性能,如果真的需要5个以上的索引,请考虑表设计是否合理),正常来说只要是逻辑外键,就应该加索引。
主键规则一般来说都要使用自增主键(分库情况除外,跨库唯一请采用雪花算法),因为mysql 匹配数字比字符串快得多。
合理选择逻辑外键 还是 关联表,一般来说,对于关键性的操作要存留操作记录,选择关联表,否则使用逻辑外键。
理论来说,每一张表都应该包含这些基础字段,如id、create_time、create_user、update_time、update_user、is_deleted
理论来说,程序是不允许直接执行delete语句的,所以请务必将is_deleted 充分运用。
一般单表行数超过 500 万行或者单表容量超过 2GB,才推荐进行分库分表。mysql的性能在该量级下还是值得信赖的。如果预计三年后的数据量根本达不到这个级别,请不要在创建表时就分库分表。
适当违反三范式,冗余一些字段以优化性能,不能选择一些频繁修改的字段,并且注意随时同步更新最新数据。
不要使用 where 1=1
查询数量时请使用 count(*)
for循环查库
开发中很经常遇到一种情况,例如:查询所有订单信息,以及每条订单的商品详情:
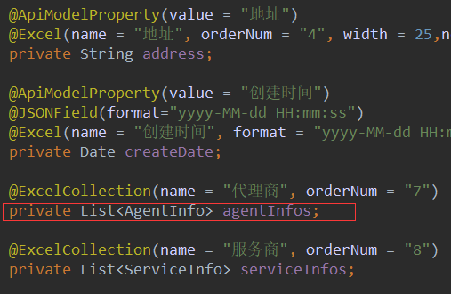
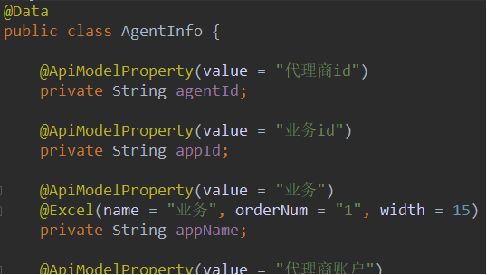
逻辑实现起来不难,第一步查询所有订单信息,第二部迭代订单查询商品详情并将商品数据存入订单集合。但是如果数据量较大,如下方式每执行一次循环,就要[建立]-[断开] 数次 的 数据库链接。很不友好,非常影响整体性能。
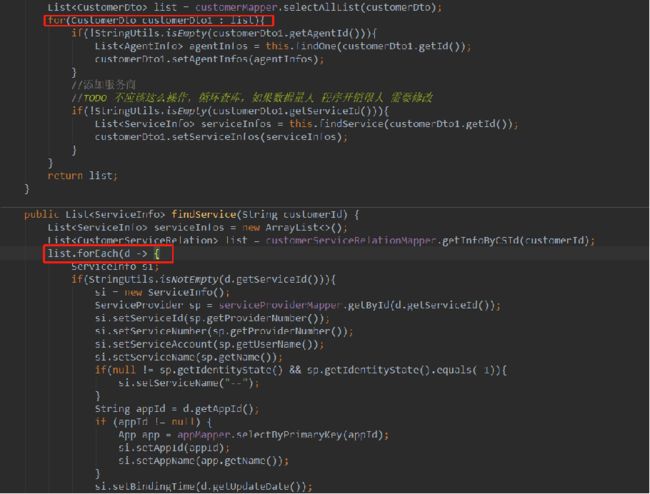
几种解决方案及优劣
1 将循环交给mybatis ,让它替我们完成,方式为(此为注解方式,xml同样可以)
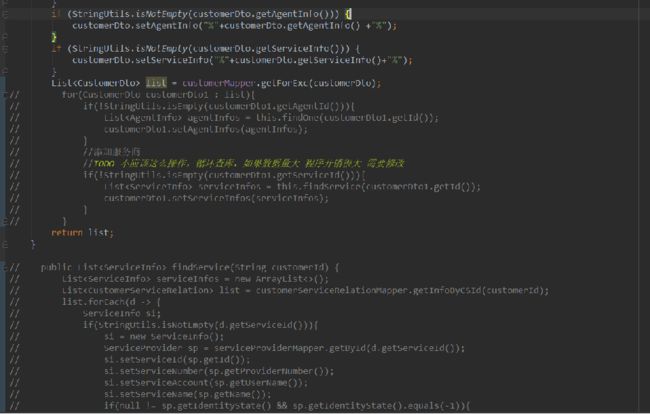
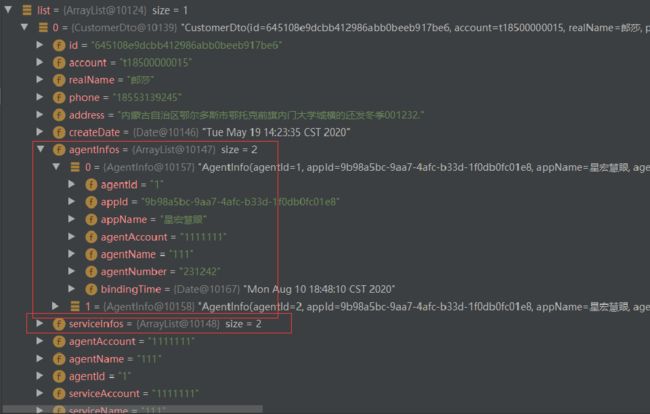
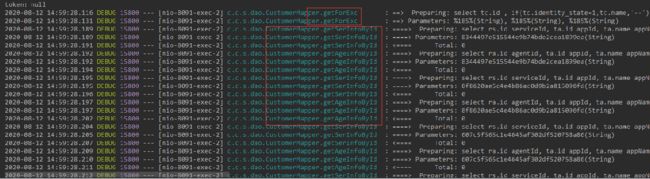
但是我们看控制台,发现跟之前的for循环一样,只不过是mybatis帮我们去写了重复调用而已。所以此方法只是使代码整洁,并没有从根本上解决问题。
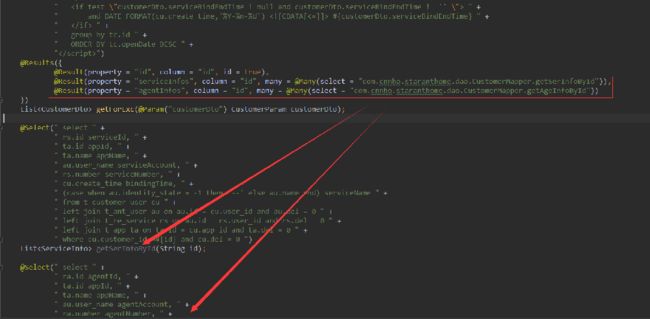
2 mybatis 属性自动封装
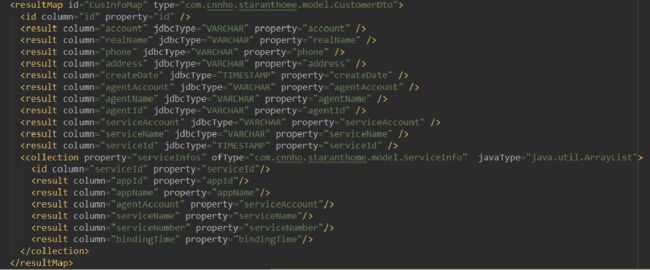
但是局限性,不能加 group by ,因为加上后,按照主键变成一行,就失效了。

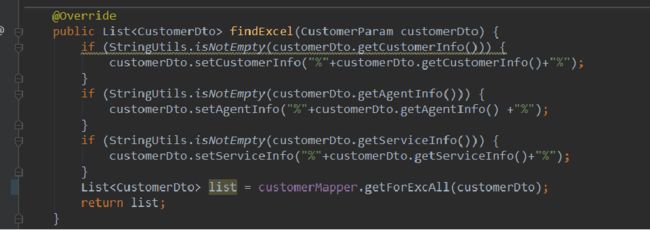

这种查询有局限性,因为没有grouy by 的分组,如果外层查询需要一些类似于统计分组的总金额,总条数 等等用到sum 等函数的时候 ,这个方案是不能满足需求的。并且日志打印的精准查询应该只查出一条主信息,现在查出两条,就是因为关联的表的结果集为两条,这样容易给读代码的人产生误区。
3 将数据取出,将循环交给程序

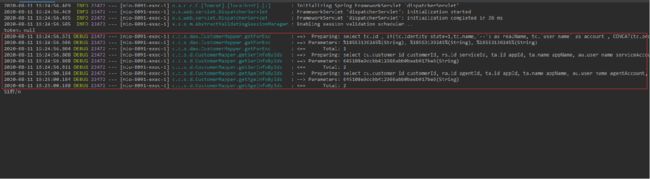
我们看控制台,执行了三次,一次获取外层信息集合,另外两次分别id in ()的方式查询结果集,同样能够达到效果。