机器视觉 零基础Python OpenCV MediaPipe手势识别教程(二)代码模块化
本文禁止转载,如需转载需征得本人同意。
目录
- 前言
- 1.上篇代码回顾
- 2.代码模块化
前言
为什么要将代码模块化呢?
代码模块化之后,我们就可以在项目中直接调用需要的东西,不必再重复进行没有必要重复的操作,将变得非常方便。
文章大部分问题可以在以下几个链接中解决:
https://www.liaoxuefeng.com/wiki/1016959663602400
(廖雪峰Python教程)
https://opencv-python-tutroals.readthedocs.io/en/latest/py_tutorials/py_gui/py_video_display/py_video_display.html
(opencv简单入门)
https://google.github.io/mediapipe/solutions/hands.html
(mediapipe参考)
https://www.cnblogs.com/chengd/articles/7287528.html
(Python入门类)
1.上篇代码回顾
先附上上篇教程中的手势识别代码,详情实现可见本人主页文章的教程(一)手势识别基础入门。
import cv2
import mediapipe as mp
import time
cap = cv2.VideoCapture(0)
mpHands = mp.solutions.hands
hands = mpHands.Hands()
mpDraw = mp.solutions.drawing_utils
pTime = 0
cTime = 0
while True:
success, img = cap.read()
imgRGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # 2 = to
results = hands.process(imgRGB)
# print(results.multi_hand_landmarks)//检查手坐标输出
if results.multi_hand_landmarks:
for handLms in results.multi_hand_landmarks:
for id, lm in enumerate(handLms.landmark):
# print(id, lm)
h, w, c = img.shape
cx, cy = int(lm.x * w), int(lm.y * h)
print(id, cx, cy)
# if id == 4:
cv2.circle(img, (cx, cy), 15, (255, 0, 255), cv2.FILLED)
mpDraw.draw_landmarks(img, handLms, mpHands.HAND_CONNECTIONS)
cTime = time.time()
fps = 1 / (cTime - pTime)
pTime = cTime
cv2.putText(img, str(int(fps)), (10, 70), cv2.FONT_HERSHEY_PLAIN, 3,
(255, 255, 255), 2)
cv2.imshow("Image", img)
cv2.waitKey(1)
2.代码模块化
首先新建文件,我们将它命名为"HandTrackingModule"
回车确认后,我们先将原来Min中的代码全部复制到新的py文件中,以便进行下一步改造。
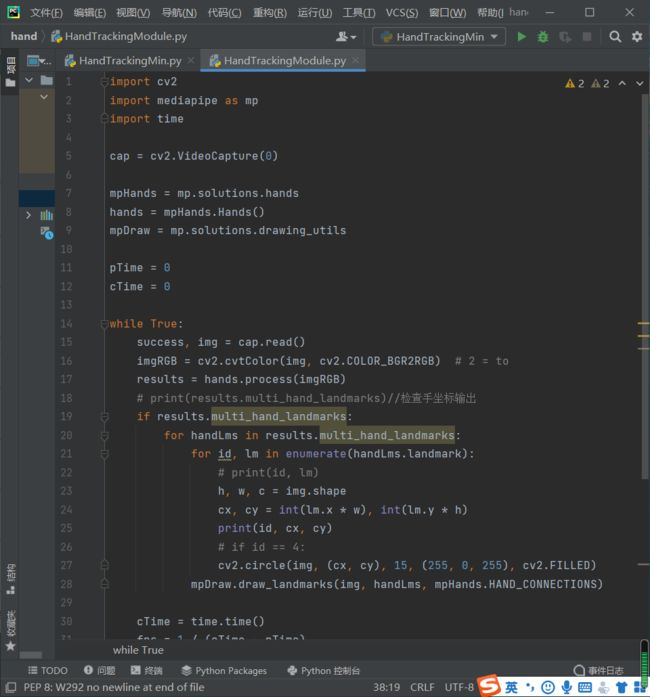
接着,我们在底部加上代码
if __name__ == "__main__":
main()
#当运行“if __name__=='__main__':”语句时,如果当前模块时被直接执行,__name__的值就是__main__,
#条件判断的结果为True,“if __name__=='__main__':”下面的代码块就会被执行
就是这样
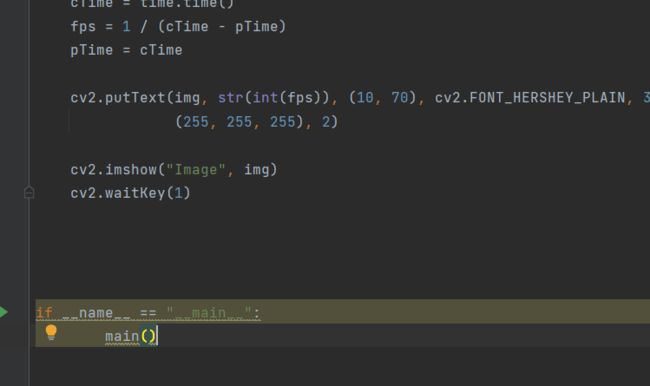
接着用def main(),将上面的代码剪切下来
def main():
pTime = 0
cTime = 0
cap = cv2.VideoCapture(0)
while True:
success, img = cap.read()
cTime = time.time()
fps = 1 / (cTime - pTime)
pTime = cTime
cv2.putText(img, str(int(fps)), (10, 70), cv2.FONT_HERSHEY_PLAIN, 3,
(255, 255, 255), 2)
cv2.imshow("Image", img)
cv2.waitKey(1)
if __name__ == "__main__":
main()
或许创建类更方便?
Python从设计之初就已经是一门面向对象的语言,正因为如此,在Python中创建一个类和对象是很容易的。
接下来我们先来简单的了解下面向对象的一些基本特征。
类(Class): 用来描述具有相同的属性和方法的对象的集合。它定义了该集合中每个对象所共有的属性和方法。对象是类的实例。
类变量:类变量在整个实例化的对象中是公用的。类变量定义在类中且在函数体之外。类变量通常不作为实例变量使用。
数据成员:类变量或者实例变量用于处理类及其实例对象的相关的数据。
方法重写:如果从父类继承的方法不能满足子类的需求,可以对其进行改写,这个过程叫方法的覆盖(override),也称为方法的重写。
实例变量:定义在方法中的变量,只作用于当前实例的类。
继承:即一个派生类(derived class)继承基类(base class)的字段和方法。继承也允许把一个派生类的对象作为一个基类对象对待。例如,有这样一个设计:一个Dog类型的对象派生自Animal类,素以Dog也是一个Animal。
实例化:创建一个类的实例,类的具体对象。
方法:类中定义的函数。
对象:通过类定义的数据结构实例。对象包括两个数据成员(类变量和实例变量)和方法。
和其它编程语言相比,Python 在尽可能不增加新的语法和语义的情况下加入了类机制。
面向对象编程是一种编程方式,此编程方式的落地需要使用 “类” 和 “对象” 来实现,所以,面向对象编程其实就是对 “类” 和 “对象” 的使用。
类就是一个模板,模板里可以包含多个函数,函数里实现一些功能
对象则是根据模板创建的实例,通过实例对象可以执行类中的函数
举例:
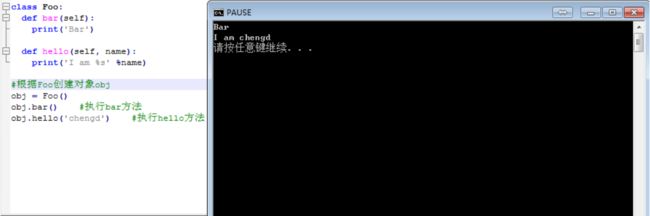
诶,你在这里是不是有疑问了?使用函数式编程和面向对象编程方式来执行一个“方法”时函数要比面向对象简便
面向对象:【创建对象】【通过对象执行方法】
函数编程:【执行函数】
观察上述对比答案则是肯定的,然后并非绝对,场景的不同适合其的编程方式也不同。
总结:函数式的应用场景 --> 各个函数之间是独立且无共用的数据
面向对象的三大特性是指:封装、继承和多态。
一、封装
封装,顾名思义就是将内容封装到某个地方,以后再去调用被封装在某处的内容。
所以,在使用面向对象的封装特性时,需要:
将内容封装到某处
从某处调用被封装的内容
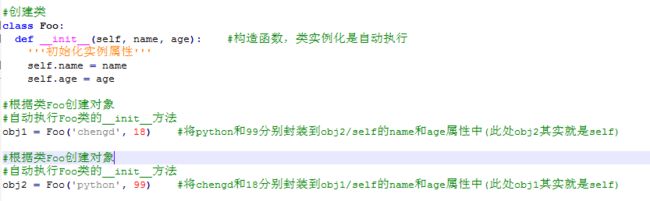
self 是一个形式参数,
当执行 obj1 = Foo(‘wupeiqi’, 18 ) 时,self 等于 obj1
当执行 obj2 = Foo(‘alex’, 78 ) 时,self 等于 obj2
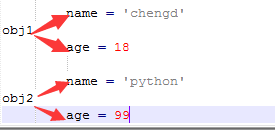
所以,内容其实被封装到了对象 obj1 和 obj2 中,每个对象中都有 name 和 age 属性,在内存里类似于下图来保存。
第二步:从某处调用被封装的内容
调用被封装的内容时,有两种情况:
通过对象直接调用
通过self间接调用
1、通过对象直接调用被封装的内容
上图展示了对象 obj1 和 obj2 在内存中保存的方式,根据保存格式可以如此调用被封装的内容:对象.属性名
2、通过self间接调用被封装的内容
执行类中的方法时,需要通过self间接调用被封装的内容
class Foo:
def __init__(self, name, age):
self.name = name
self.age = age
def detail(self):
print(self.name)
print(self.age)
obj1 = Foo('chengd', 18)
obj1.detail() # Python默认会将obj1传给self参数,即:obj1.detail(obj1),所以,此时方法内部的 self = obj1,即:self.name 是 chengd ;self.age 是 18
obj2 = Foo('python', 99)
obj2.detail() # Python默认会将obj2传给self参数,即:obj1.detail(obj2),所以,此时方法内部的 self = obj2,即:self.name 是 python ; self.age 是 99x
执行结果:
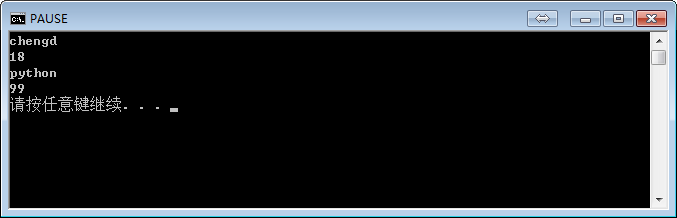
至此,类简要介绍完毕,接着我们的项目。
建立手部检测初始化
class handDetector():
def __init__(self, mode=False, maxhands=2, detectionCon=0.5, trackCon=0.5):
"""
初始化参数
:param mode: 是否输入静态图像
:param maxhands: 检测到手的最大数量
:param detectionCon: 检测手的置信度
:param trackCon: 追踪手的置信度
"""
self.mode = mode
self.maxhands = maxhands
self.detectionCon = detectionCon
self.trackCon = trackCon
self.mpHands = mp.solutions.hands
self.hands = self.mpHands.Hands(self.mode, self.maxhands,
self.detectionCon, self.trackCon)
self.mpDraw = mp.solutions.drawing_utils
初始化完成,我们进入检测
def findHands(self, img, draw=True):
"""
检测手掌
:param img:要识别的一帧图像
:param draw:是否对手的标志点进行绘图
:return:绘画完成的一帧图像
"""
imgRGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
self.results = self.hands.process(imgRGB)
if self.results.multi_hand_landmarks:
for handLms in self.results.multi_hand_landmarks:
if draw:
self.mpDraw.draw_landmarks(img, handLms, self.mpHands.HAND_CONNECTIONS)
return img
至此,完整代码为
import cv2
import mediapipe as mp
import time
class handDetector():
def __init__(self, mode=False, maxHands=2, detectionCon=0.5, trackCon=0.5):
self.mode = mode
self.maxHands = maxHands
self.detectionCon = detectionCon
self.trackCon = trackCon
self.mpHands = mp.solutions.hands
self.hands = self.mpHands.Hands(self.mode, self.maxHands,
self.detectionCon, self.trackCon)
self.mpDraw = mp.solutions.drawing_utils
def findHands(self, img, draw=True):
imgRGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # 2 = to
results = self.hands.process(imgRGB)
# print(results.multi_hand_landmarks)//检查手坐标输出
if results.multi_hand_landmarks:
for handLms in results.multi_hand_landmarks:
if draw:
self.mpDraw.draw_landmarks(img, handLms,
self.mpHands.HAND_CONNECTIONS)
return img
# for id, lm in enumerate(handLms.landmark):
# # print(id, lm)
# h, w, c = img.shape
# cx, cy = int(lm.x * w), int(lm.y * h)
# print(id, cx, cy)
# # if id == 4:
# cv2.circle(img, (cx, cy), 15, (255, 0, 255), cv2.FILLED)
def main():
pTime = 0
cTime = 0
cap = cv2.VideoCapture(0)
detector = handDetector()
while True:
success, img = cap.read()
img = detector.findHands(img)
cTime = time.time()
fps = 1 / (cTime - pTime)
pTime = cTime
cv2.putText(img, str(int(fps)), (10, 70), cv2.FONT_HERSHEY_PLAIN, 3,
(255, 255, 255), 2)
cv2.imshow("Image", img)
cv2.waitKey(1)
if __name__ == "__main__":
main()
是不是感觉比之前更清晰明了,接下来我们运行试试
说明模块化是没问题的。
接下来,我们对手各个位置点的数据进行处理。
Python List append()方法
描述
append() 方法用于在列表末尾添加新的对象。
语法
append()方法语法:
list.append(obj)
参数
obj – 添加到列表末尾的对象。
返回值
该方法无返回值,但是会修改原来的列表。
实例
以下实例展示了 append()函数的使用方法
aList = [123, ‘xyz’, ‘zara’, ‘abc’];
aList.append( 2009 );
print "Updated List : ", aList;
以上实例输出结果如下:
Updated List : [123, ‘xyz’, ‘zara’, ‘abc’, 2009]
def findPosition(self, img, handNo=0, personDraw=True):
"""
检测手的标志点
:param img: 要识别的一帧图像
:param handNo: 手的编号
:param personDraw: 是否对手的标志点进行个性化绘图
:return: 手的21个标志点位置
"""
lmList = []
if self.results.multi_hand_landmarks:
myhand = self.results.multi_hand_landmarks[handNo]
for id, lm in enumerate(myhand.landmark):
h, w, c = img.shape
cx, cy = int(lm.x * w), int(lm.y * h)
lmList.append([id, cx, cy])
if personDraw:
cv2.circle(img, (cx, cy), int(w / 50), (255, 0, 255), cv2.FILLED)
return lmList
至此,我们的模块编写完毕,完整代码如下:
import cv2
import mediapipe as mp
import time
class handDetector():
def __init__(self, mode=False, maxhands=2, detectionCon=0.5, trackCon=0.5):
"""
初始化参数
:param mode: 是否输入静态图像
:param maxhands: 检测到手的最大数量
:param detectionCon: 检测手的置信度
:param trackCon: 追踪手的置信度
"""
self.mode = mode
self.maxhands = maxhands
self.detectionCon = detectionCon
self.trackCon = trackCon
self.mpHands = mp.solutions.hands
self.hands = self.mpHands.Hands(self.mode, self.maxhands,
self.detectionCon, self.trackCon)
self.mpDraw = mp.solutions.drawing_utils
def findHands(self, img, draw=True):
"""
检测手掌
:param img:要识别的一帧图像
:param draw:是否对手的标志点进行绘图
:return:绘画完成的一帧图像
"""
imgRGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
self.results = self.hands.process(imgRGB)
if self.results.multi_hand_landmarks:
for handLms in self.results.multi_hand_landmarks:
if draw:
self.mpDraw.draw_landmarks(img, handLms, self.mpHands.HAND_CONNECTIONS)
return img
def findPosition(self, img, handNo=0, personDraw=True):
"""
检测手的标志点
:param img: 要识别的一帧图像
:param handNo: 手的编号
:param personDraw: 是否对手的标志点进行个性化绘图
:return: 手的21个标志点位置
"""
lmList = []
if self.results.multi_hand_landmarks:
myhand = self.results.multi_hand_landmarks[handNo]
for id, lm in enumerate(myhand.landmark):
h, w, c = img.shape
cx, cy = int(lm.x * w), int(lm.y * h)
lmList.append([id, cx, cy])
if personDraw:
cv2.circle(img, (cx, cy), int(w / 50), (255, 0, 255), cv2.FILLED)
return lmList
if __name__ == "__main__":
pTime = 0 # 开始时间初始化
cap = cv2.VideoCapture("example.mp4")
detector = handDetector()
while True:
success, img = cap.read()
img = detector.findHands(img, draw=True)
lmList = detector.findPosition(img, personDraw=False)
if len(lmList) != 0:
print(lmList[4]) # 食指最上部点的坐标
cTime = time.time()
fps = 1 / (cTime - pTime)
pTime = cTime
cv2.putText(img, str(int(fps)), (10, 70), cv2.FONT_HERSHEY_PLAIN, 3,
(255, 0, 255), 1)
cv2.imshow("Image", img)
cv2.waitKey(1)
编写好后,如果我们需要在其他项目中使用,只需要在其代码前添加import HandTrackingModule,即可使用我们编写好的findHands()以及findPosition()
文章到此结束,接下来将更新的文章有人体姿势识别,人脸识别,以及用手势控制音量的应用。