1.mysql原子性和持久性怎么保证
2.innodb和myisam区别
3.索引分类
4.innodb的底层数据结构
5.为什么底层使用B+树不用B树
索引:
https://www.bilibili.com/video/BV1u7411v7wK?from=search&seid=2075506451452551219
1、索引是什么?索引应该存储的是什么样的数据?
文件 偏移量 定位数据 ,索引存在于内存or磁盘? ->磁盘 放在内存中被使用
知识前提:用户空间 内核空间
程序的访问有聚集的倾向
局部性原理 :时间、空间局部性
磁盘预读:读取1bit 以页为单位
IO性能:影响因素 1、量; 2、次数
磁盘与内存 网络:带宽 网卡(硬件因素)
优化IO 减少量,减少次数
·索引是帮助MYSQL高效获取数据的数据结构
·索引存储在文件系统中
·索引的文件存储形式与存储引擎有关
·索引文件的机构
·hash 适合memory
·二叉树
·B树
·B+树
存储引擎:表示不同的表数据文件在磁盘中以不同的组织形式存在
innodb 数据和索引文件放在一个文件中,支持事务,支持表锁,行锁,有外键
myisam 不同文件中,不支持事务,只支持表锁,没有外键
memory
数据结构:
·hash表
索引格式:
01234
数组 :取模存元素,key冲突 在对应下标下面拼接 以链表存储 减少hash冲突问题
扰动函数:存储 0-15 需要4个二进制位
1 1 1 0 |0 1 0 1
1 0 1 0 |0 1 0 1
后面四位一直 于是 判断前面四位 减少hash冲突
·hash 缺点
耗费内存空间
不适合范围查询
树:背景:遍历节点 比较 很慢 二叉树分支少 排序插入,有利于二分查找 从而演变中 BST 二叉搜索树
BST:左小 右大
类似于链表,(极端情况下) 很局限,不平衡
AVL树:二叉平衡树
要求 最短子树,与最长子树 高度差 不能超过一;
插入时 会进行左右旋转操作,
特点 : 查询性能高(以插入性能为代价)
红黑树:特殊的二叉平衡树
最长子树 不超过最短子树2倍(子树指的是节点的个数)
插入和查询性能都比较好
随着元素越来越多 树也就越来越高 IO次数也就高
为什么变深 因为 分支少
B树
degree 阶 每个节点对应放置的元素
树也会变深 造成查询性能变低
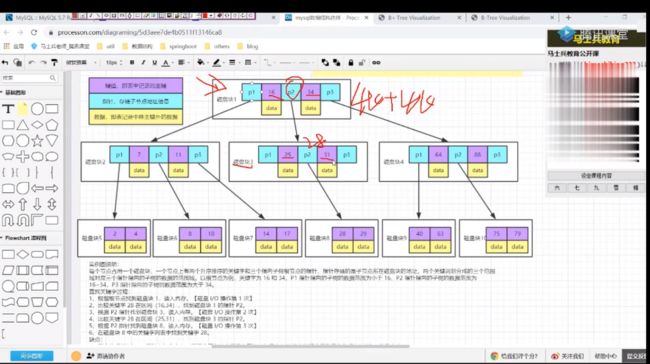
缺点:1、每个节点都有key,同时也包含data,而每个页存储空间是有限的,如果data比较大的话会导致每个节点存储的key数量变小
2、当存储的数据量很大的时候 会导致深度较大,增大查询时磁盘的IO次数,进而影响性能
B+树
与B树区别:
把索引和数据放在不同的磁盘块
存储的数据量比较大,树不深
为什么说B+树比B浅
归根结底还是因为B树得非叶子节点中也含有数据块,导致能够包含得key值 变少 那么就会变深。

页分裂 维护成本比较高(不自增的情况下)
mysql - 存储引擎 innoDB 叶子节点 存放的就是 整行数据(数据文件和索引文件放在一起)
mysql - 存储引擎 myisam 叶子节点 存放的是 数据地址
索引的分类
·主键索引:主键是一种唯一索引,但它必须指定为primary key,每个表只能有一个主键。
·唯一索引:索引列的所有值都只能出现一次,即必须唯一,值可以为空
·普通索引:基本的索引类型,值可以为空,没有唯一性的限制
·全文索引:全文索引的索引类型为FULLTEXT。全文索引可以在varchar,char,text类型的列上创建
·组合索引:多列值组成一个索引,专门用于组合搜索。
关键字 :回表、最左匹配原则、索引覆盖、索引下推
回表
普通索引的B+树的叶子节点中 存储的不是整行数据而是 当前数据的主键
意味着 遍历两课B+树
第一次 根据普通索引的那一列 ,B+ 查找主键值
第二次 根据主键值 去主键的B+树 查找整行数据
这就是 回表。 没有主键去找唯一键 没有唯一键 去找rowId。(用户不可见,oracle 直接看到rowId)
索引覆盖举个例子
select * from t1 where name = 'ma'; (1)
select id from t1 where name = 'ma' (2)
id是主键
所以(1) 第一次遍历B+树查找到id 值 ,又根据id值 遍历B+树查找整行数据
(2) 遍历B+树查找id值 返回。
最左匹配
组合索引,当查询的sql语句中的条件都是其中某些列的时候,可以根据这些列来创建组合
age,gender
select * from t1 where age = ? and gender =?
select * from t1 where gender =? and age = ?
select * from t1 where gender =?
select * from t1 where age = ?
mysql 优化器 会帮助mysql 调整匹配顺序
索引下推
5.7 之前 先根据age字段从存储引擎层 将数据拉去回server层,然后在server层进行gender的筛选
5.8 再从存储引擎层拉取数据的时候,就直接根据age,gender一起进行筛选
谓词下推
select t1.name ,t2.name from t1, join t2 on t1.id = t2.id;
1、t1 和 t2根据id字段进行关联 然后从关联的所有字段中取出两个name
2、把当前sql语句中用到的所有字段都取出来,然后再根据id进行关联。 IO少
MVCC
https://www.jianshu.com/p/8845ddca3b23
事务隔离级别
read uncommiter
read commited
default 级别:repeatable Read
serilizable 串行的
for update 行锁; mysql隐式的 列
事务的丢失更新:
https://blog.csdn.net/sun8112133/article/details/89853755