最新论文笔记(+2):Scaling Nakamoto Consensus to Thousands of Transactions per Second / arXiv 2018
Scaling Nakamoto Consensus to Thousands of Transactions per Second (将中本聪共识的吞吐率提升到每秒数千次交易)
本篇论文主要涉及到了中本聪共识(Nakamoto Consensus,NC)、有向无环图(Directed Acyclic Graph, DAG)结构等基础知识,通过将传统NC共识进行改进,由单链形式转变为了网络拓扑结构,且不丢弃任何分叉的区块的对交易进行排序。本篇论文的主旨就是围绕处理并发交易或区块,以及对全部延迟的交易进行排序,其核心思想主要是解决两种问题,一类是交易排序问题,与传统NC共识先确定交易顺序再确定区块顺序不同,该共识协议是先确定区块顺序,再确定交易顺序;第二类是异常交易处理问题,对有冲突或双花的交易,始终只保留前一笔交易。
- 原文链接:Scaling Nakamoto Consensus to Thousands of Transactions per Second
一、背景及贡献
| 论文名称 | 作者 / 单位 | 来源 | 年份 | 简要内容 |
|---|---|---|---|---|
| Scaling Nakamoto Consensus to Thousands of Transactions per Second | Chenxing Li (清华大学) | arXiv | 2018 | 通过改进NC共识的交易排序问题,将吞吐率提升到每秒数千次交易 |
本篇论文提出的系统取名为Conflux,意为汇流。其主要的贡献为:
- (1)共识协议:作者提出了一个快速的、可扩展的基于DAG结构的NC共识协议。Conflux能有效地处理并发的区块,同时惰性地协调交易的总顺序。
- (2)Conflux实现:作者提出了基于Bitcoin核心代码库的Conflux原型实现。Conflux是第一个基于DAG结构的NC共识协议的区块链系统。它可以实现每秒处理数千笔交易。
- (3)实现结果:对Conflux进行系统性的大规模评估。当运行2w个全节点时,Conflux达到的交易吞吐量为2.88 ~ 5.76GB/h,确认时间为4.5 ~ 7.4分钟,交易速度是Bitcoin的11.62倍。
二、预备知识
2.1 共识算法
共识算法简述为普遍应用于像区块链一样的分布式网络当中,使其所有的节点对某个方案达成一致性协议。这里重点讲一下NC共识,以及其他共识。
(1) 中本聪共识(简称,NC共识) = PoW共识 + 时间戳 + 激励机制 + 最长链原则
- PoW共识:即工作量证明(PoW),表示全网所有节点共同求解一道数学难题,寻找一个随机数使得区块头的哈希值小于等于目标哈希值,并将满足条件的区块存储在区块链上,使得全网的节点认可这个区块,即完成PoW共识。
- 时间戳:表示生成区块的时间,能有效的对交易进行排序,防止双花(double spending)交易。
- 激励机制:表示系统对生成区块的矿工给予奖励,以提供动力,从而增加网络节点的规模,防止51%攻击。
- 最长链原则:系统始终会选择链条最长的链来作为主链,但是会导致区块确认时间较长和资源浪费等缺点。(该论文主要是解决这个问题)

(2) 其他共识还有PoS、DPoS和PBFT,以及最新的几种对共识算法改进的方案(如Dumb-BFT,“小飞象”和NC-MAX)等,如下表。
| 共识算法 | PoW (工作量证明) | PoS (权益证明) | DPoS (委托权益证明) | PBFT (实用型拜占庭容错共识) | Dumbo-BFT (“小飞象”) | NC-MAX(改进NC共识) |
|---|---|---|---|---|---|---|
| 容错率 | 50% | 50% | 50% | 33% | 33% | 50% |
| 出块时间 | >500s | <100s | <100s | <10s | ? | 动态 |
| 吞吐量(TPS) | <10 | <1000 | <1000 | <2000 | <18000 | <2500 |
| 可扩展性 | 强 | 强 | 强 | 弱 | 中 | 强 |
| 缺点 | 效率低 | TPS小 | 投票繁琐 | 扩展性差 | ? | ? |
2.2 有向无环图(DAG)
有向无环图(Directed Acyclic Graph, DAG):指一个无闭环且有方向的图。具体内容见另一篇笔记介绍。
- 目前主要分为:PoW公有链中的DAG结构、PoS公有链中的DAG结构和联盟链中的DAG结构三种。
- 在DAG网络中,交易的驱动力是希望自己的交易尽快确认,其拓扑结构由以前的单链形式转变成了网络结构,且不丢弃任何的分叉区块,保证了区块利用率,则就会存在一个重要的问题,也就是如何对交易进行排序问题?
三、方案构造
本篇论文主要提出了Conflux框架、共识协议和共识算法实现等三个方面。
3.1 Conflux框架
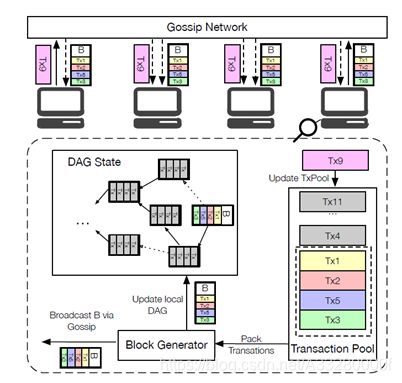
如图,Conflux框架中主要包含了三个实体,Gossip Network、Transaction Pool和Block Generator。如果需要将一笔交易上传至网络的具体运行过程为:
- (1)将交易广播至gossip网络中,其他节点接收后,将其存储在自身的transaction pool中。
- (2)节点可通过block generator打包交易,并生成区块。
- (3)生成区块后,更新本地的DAG状态,并从transaction pool中删除该区块中的交易。(注意,transaction pool中的交易是无顺序的)
- (4)通过gossip network把区块广播给其他节点,如此往复。
因此,可以看出Conflux的目标主要是维护每个节点的本地DAG,以便使得所有节点最终对区块和交易的总顺序达成一致。
3.2 共识协议
如下图,为含有多个区块的DAG图例。

排序原则:
- (1)Parent Edge(实线、父边):除了创世区块,其他区块都有且仅有一条parent edge。
(例如,区块C指向A,F指向B) - (2)Reference Edge(虚线、引用边):每个区块有多条reference edge,表示区块的时间先后顺序关系。
(例如,区块E指向D,表示区块D先于区块E产生,所以D排在E的前面) - (3)Pivot Chain(主链):该共识并不是找到最长链,而是选择包含子树尺寸最大的链(最重链原则)。
(例如,创世区块后的子区块A包含DGCEH五个子区块,而子区块B包含FJIK四个子区块,所以主链选择A,而A的子区块为D、G、C,返回C,最后一直到H,所以主链就为创世区块、A、C、E、H) - (4)生成新区块:节点计算出本地DAG图的主链,新区快指向主链最后一个区块,作为父边。
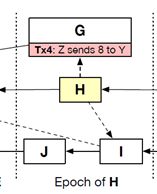
(例如,new block指向主链最后一个区块H) - (5)Epoch(时期):主链每个区块负责一个epoch,先对epoch排序,再对epoch内的区块进行排序,若没有顺序的区块则根据hash值大小排序。
(例如,E的epoch包含了区块D、E、F三个区块,而由E指向D、F的引用边可知,E排在D、F的后面,再比较D、F的hash值谁小,谁就放前面,所以最后的排序为D、F、E)
特别注意:为何J是归纳到H的epoch,而不是E的epoch内呢?是因为论文中提到需要可以通过父边和引用边从主链指向到达的区块或者不包含在以前的epoch中的区块。
- (6)交易排序:最后剔除冲突或双花的交易,生成交易顺序。
(例如,Tx2与Tx3是双花交易,则只保留先前一笔交易,而Tx4(区块B中的)和Tx4(区块G中的)是冲突交易,也只保留前一笔,后一笔交易剔除掉,则最后的顺序为Tx0、Tx1、Tx2、Tx4(区块B))
以上标黄的四个是非常重要的概念,需要记住,以便理解这个协议是干嘛的。
3.3 共识算法实现
Conflux协议是DAG图:
G = < B , g , P , E > G=
其中,B表示区块集合,g表示创世区块,P表示映射函数,E表示边的集合。以及还有一些函数的定义。
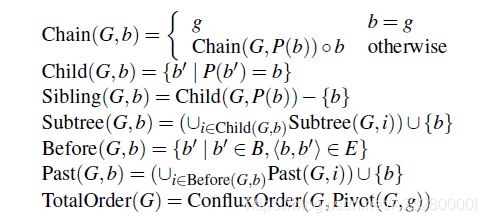
| 函数 | 功能 |
|---|---|
| P ( b ) P(b) P(b) | 将区块b映射到它的父块 |
| C h a i n ( G , b ) Chain(G, b) Chain(G,b) | 从创世区块到区块b的主链 |
| C h i l d ( G , b ) Child(G, b) Child(G,b) | 区块b所有子块的集合,且包含b本身 |
| S i b i l i n g ( G , b ) Sibiling(G, b) Sibiling(G,b) | 区块b的同级块,即除区块b之外的 C h i l d ( ) Child() Child() |
| S u b t r e e ( G , b ) Subtree(G, b) Subtree(G,b) | 区块b的子树,且包含区块b本身 |
| B e f o r e ( G , b ) Before(G, b) Before(G,b) | 区块b指向的区块,包含父边和引用边 |
| P a s t ( G , b ) Past(G, b) Past(G,b) | 区块b之前所有区块的集合,包含b本身 |
| T o t a l O r d e r ( G , ) TotalOrder(G,) TotalOrder(G,) | DAG图G里所有区块的排序 |
下面将具体介绍下三个主要的功能函数,包括 P i v o t ( ) Pivot() Pivot()算法、主循环共识操作和 C o n f l u x O r d e r ( ) ConfluxOrder() ConfluxOrder()算法。
(1) P i v o t ( ) Pivot() Pivot()算法:返回主链的最后一个区块
如下面伪代码所示,实线的功能为选择拥有子树区块最多的那条链,然后通过迭代,直到计算到叶子节点。

- (1)选择拥有子树区块最多的那条链
- (2)通过迭代,直到计算到叶子节点
例如,如何计算 P i v o t ( G , g ) Pivot(G, g) Pivot(G,g)呢?首先计算 g g g的子块有A和B,而A的子树区块总数为A、C、D、E、H、G共6个,而B的子树区块只有B、F、J、I、K共5个,所以选择A,继续比较A的子树D、G、C,C被返回,以此比较下去,直至返回H。
(2) Conflux中节点不断执行的主循环,即共识操作
主要是处理更新DAG状态和生成新区块两类事件,前半部分,节点收到更新信息后更新本地的DAG图,并将本地G广播给其他节点。后半部分在生成新区块后计算主链的最后一个区块 a a a,然后将创建新区块 b b b到当前所有还没有入边区块t的边,然后添加新区快 b b b到 a a a的父边。

- (1) 更新本地DAG状态:节点更新本地的DAG图;将本地G广播给其他节点。
- (2) 生成新区快:计算主链最后一个区块 a a a;创建新区块 b b b到未入边的区块t的边;添加新区块 b b b到 a a a的父边。
伪代码中有一个小错误,这里应该是半角字符a,而不是 a a a,虽然这不影响整体,但是提一下,便于理解。
(3) C o n f l u x O r d e r ( ) ConfluxOrder() ConfluxOrder()算法:区块排序算法,返回某区块epoch中或之前出现所有区块的序列表。
该算法是从后往前递归的,先找到 a a a的父块,再将 a a a的父块epoch内的顺序赋值给L,然后计算 a a a的epoch中所有区块的排序。

- (1)对区块 P ( a ) P(a) P(a)的epoch之前的所有区块排序
- (2)找到 a a a的父块,并将它的 C o n f l u x O r d e r ConfluxOrder ConfluxOrder赋值给L
- (3)计算 a a a的epoch中所有区块的顺序
例如,如何对H的epoch里的区块G、H、J、I进行排序呢,没有出边的区块有G、J,根据哈希值进行排序,那就把G、J放入L当中,然后剔除这两个区块,对剩下的H、I排序,又因为剔除后,I就没有了出边,且H指向I,所以I排在H的前面,即G、J、I、H,用同样的办法对其他的epoch中区块进行排序。
3.4 协议假设
(1)区块生成率假设
网络总的区块生成率为 λ \lambda λ,则有
λ = λ h + λ a , λ a = q λ h , 0 ≤ q < 1 \lambda=\lambda_h+\lambda_a,\lambda_a=q\lambda_h,0\leq q<1 λ=λh+λa,λa=qλh,0≤q<1
其中, λ a \lambda_a λa表示攻击节点的区块生成率, λ h \lambda_h λh表示诚实节点的区块生成率,这是比较合理的假设。
(2)d-同步
假设网络为所有节点提供d-同步通信。即在时间t内,诚实节点通过广播一个区块或交易,则在t+d之前,所有诚实节点都会收到这个区块,并将其添加到自身的本地状态。
(3)敌手模型
假设攻击者的能力有两个限制,即
- 攻击者不具备反向密码函数的能力(即,反向推出hash函数的输入),诚实节点可以在攻击者在场的情况下可靠地验证区块的完整性。
- 所有的诚实节点加在一起比攻击者具有更强的区块生成能力。
可以从上面的比例关系看出,始终 λ h > λ a \lambda_h>\lambda_a λh>λa,这也是比较合理的假设。
3.5 正确性
(1)安全性
- Conflux采用了GHOST规则选择主链,因此满足与GHOST相同的安全性;
- 只要攻击者控制不到50%的区块生成量,就不太可能恢复所有诚实节点生成的主链;
- 由于始终满足 λ h > λ a \lambda_h>\lambda_a λh>λa,攻击者不可能在主链块的子树中锻造出一条比主链的子树更重的子树。
(2)确信度
- 只要区块b在主链上不可逆,就可确信b的epoch中 b ′ b^{'} b′的交易。以下约束,是来确定b的风险。
- 假设b是在[t-d, t]时期内主链上的区块, P ( b ) P(b) P(b)在零时生成。则b被其他同级区块 a a a剔除主链的概率不会超过:
∑ k = 0 n − m ξ k q n − m − k + 1 + ∑ k = n − m + 1 ∞ ξ k , 其 中 ξ k = e − q λ h t ( q λ h t ) k k ! \sum_{k=0}^{n-m}\xi_kq^{n-m-k+1}+\sum_{k=n-m+1}^{\infty}\xi_k, 其中\xi_k=e^{-q\lambda_ht}\frac{(q\lambda_ht)^k}{k!} k=0∑n−mξkqn−m−k+1+k=n−m+1∑∞ξk,其中ξk=e−qλhtk!(qλht)k
其中n为在[t-d]之前b的子树数量,m为 a a a的子树数量。
四、定量分析
本篇论文分别对Conflux的吞吐量、确认时间和可扩展性做了定量分析。
(1)对比吞吐量
实验环境:400台8核Amazon EC2虚拟机,每台模拟25个全节点,共运行1w个节点。
影响吞吐量的三个影响因素:区块大小限制、区块生成速率和区块利用率。

- 如上图所示,固定区块生成率为每块20s,观察区块大小与区块利用率的关系。由于比特币和GHOST都有分叉,所以利用率并不高,且随着区块大小增大,利用率更低,而Conflux因为计算了所有的区块,所以利用率一直是100%。
- 另外,固定区块大小为4MB,观察区块生成率与区块利用率的关系。因此,可以看出随着区块大小和区块生成率的增加,Conflux会并行生成更多的区块。
(2)区块的确认时间
实验环境:假设攻击者控制的网络区块生成率小于20%(则诚实节点控制的区块生成率为大于80%,即 q < 0.25 q<0.25 q<0.25)
影响区块的确认时间:节点必须等待一段时间以获得较高的置信度,即块的总顺序不会变。
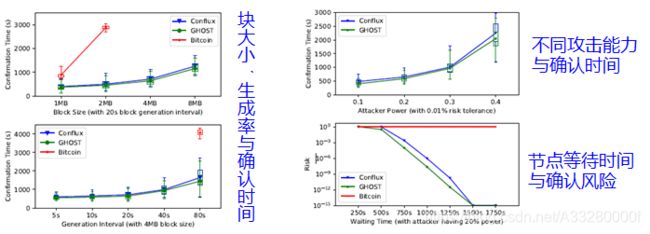
- 从上图可知,增加区块生成能更快确认区块,但频繁的并发区块又会减慢确认的速度。
- 另外,不同攻击能力与确认时间的关系,以及节点等待时间与确认风险的关系,随着节点等待时间的延长,攻击者还原已确认区块的几率呈指数下降。
(3)可扩展性
实验条件:1)改变全节点的数量,从2.5k扩展到2w;2)改变带宽,从20Mbps扩展到40Mbps。
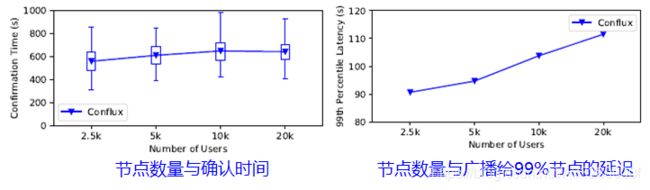
通过改变全节点的数量和改变带宽来进行仿真实验,可以得出节点数量与确认时间,与广播给99%的节点的延迟时间关系图。
- 从图中可以看出,节点数量的增加其确认时间差不多,则表示Conflux的扩展性好。
- 带宽增加至40Mbps时,吞吐量为5.76GB/h,相较于比特币的交易来衡量,Conflux每秒处理的交易为6400比交易!!!
五、总结与思考
5.1 全文总结
回顾下全文,可将论文划分为三个重点。
(1)重点1:对NC共识进行了改进,提出了一个不丢弃分叉块的基于DAG结构的NC共识协议。

- 传统NC共识只保留最长链,分叉链直接丢弃,使得有些节点提交的交易容易浪费掉,可能导致那些节点不开心。
- 而Conflux保护每个区块的交易,利用率非常高,每个节点都开心。
(2)重点2:对交易的排序规则进行优化,先对区块进行排序,解决冲突或双花交易后,再对区块内的交易进行排序。

(3)重点3:在保证与传统NC共识同等级的安全性条件下,将交易吞吐量提升至最高。
5.2 疑问和思考
- 疑问1:既然不丢弃任何一个分叉块,那岂不是很多” 垃圾块“ 也保存下来了,会有影响吗?
- 疑问2:Conflux比传统NC记录的区块更多,那“凭什么要帮你记这么多账” ,还会有奖励吗?
- 疑问3:如果“最长链”和“最重链”包含的区块一样多,那该怎么选主链?
- 疑问4:草草收尾,一句“ 与GHOST具有相同的安全性”就完了,是否真的具有一样的安全性,并未论证?
- 疑问5:这里的DAG结构,作者是假设每个区块含有4笔交易,那可以选5笔、6笔或n笔交易吗?选多少笔交易存储在一个区块中会比较合适,有什么衡量标准吗?
欢迎大家看完后,有兴趣的朋友可以在评论区一起讨论,一起交流,一起学习。