Python 遍历文件夹,文件内容,批处理文件
一.引言
经常需要遍历文件夹和文件,并且检查文件中是否包含某个字段,特此整理相关方法。
下面示例均以RootDir为根目录,其文件结构如下:

其中 dirA 中包含 .sh 与 .py,dirB 包含 .txt,dirC包含 .java
二.遍历文件夹
1.遍历当前地址并判断文件类型
def getCurrentFile(rootDir, allFiles=[]):
list = os.listdir(rootDir) # 列出文件夹下所有的目录与文件
for i in range(0, len(list)):
path = os.path.join(rootDir, list[i])
if os.path.isfile(path):
print("File:", path)
else:
print("Dir:", path)
allFiles.append(path)
return allFiles
print("获取当前目录信息:")
currentFileList = getCurrentFile(rootDir)通过 isfile 方法判断是否是文件,获取目录下文件的信息。

2.递归遍历文件夹下全部文件
def getFile(rootDir, allFiles=[], isShow = True):
files = os.listdir(rootDir)
for file in files:
path = rootDir + seprator + file
if not os.path.isdir(path):
allFiles.append(path)
else:
getFile(path, allFiles, False)
if isShow:
print('\n'.join(allFiles))
return allFiles
print("获取当前目录下全部文件信息:")
fileList = getFile(rootDir)通过递归调用以及 isdir 方法,将文件路径放入数组中并展示,注意 isShow 参数只在最外一层调用开启即可。最终结果为dirA,dirB,dirC下的文件以及 rootDir 下的两个文件。

三.遍历文件内容
1.常规遍历文件内容
除了遍历文件夹下全部文件外,有时候还需要遍历每个文件的内容。fileList 代表文件列表,可以配合上一步得到的 rootDir 下的文件使用。这里逻辑判断全部文件内是否包含 hello 字段,如果存在则打印 文件路径,对应字段内容 以及 字段对应的行数。
def handleText(fileList, allFiles=[], is_show = True):
for path in fileList:
lineIndex = 1
with open(path, 'r') as f:
line = f.readline()
while line:
if line.find("hello") >= 0:
allFiles.append("line " + str(lineIndex) + ": " + path + " text:" + line.strip())
line = f.readline()
lineIndex += 1
if is_show:
print('\n'.join(allFiles))
return allFiles
print("获取目标字段对应文件与行数:")
fileList = getFile(rootDir)
lineWithText = handleText(fileList)
这里看下 fileA 的文件内容,行号,对应内容以及文件路径都准确给出。

2.遍历指定类型文件
如果只需要遍历相关的文件夹只需要在遍历 fileList 时对 path 进行限制,例如只遍历 shell,python,java文件可以这样设置:
path.endswith('.sh') or path.endswith('.py') or path.endswith('.java') 也可以指定文件夹包含某个字符,可以使用 find 方法或者 __contains__ 方法:
# 包含 返回 True/False
path.__contains__("xxx")
# 查找 如果包含子字符串返回开始的索引值,否则返回-1
path.find("xxx") >= 0
三.自定义
现在可以遍历文件夹下的文件,也可以遍历文件内容,接下来就可以自定义批处理文件或者文件内容了。
1.批处理文件
最常见的是查看文件大小,通过 map-lambda 的方法实现类 switch-case 的方法,对指定文件给定 unit 标准即可获取文件大小。
import math
roundNum = 5
sizeChange = {
'Bit': lambda size: round(float(size) / math.pow(1024, -1), roundNum),
'Byte': lambda size: round(float(size) / math.pow(1024, 0), roundNum),
'KB': lambda size: round(float(size) / math.pow(1024, 1), roundNum),
'MB': lambda size: round(float(size) / math.pow(1024, 2), roundNum),
'GB': lambda size: round(float(size) / math.pow(1024, 3), roundNum),
'TB': lambda size: round(float(size) / math.pow(1024, 4), roundNum)
}
def getFileSize(path, unit='Byte'):
fSize = os.path.getsize(path)
fSize = sizeChange[unit](fSize)
return "{}: {} {}".format(path, fSize, unit)
fileList = getFile(rootDir)
print("获取RootDir下所有文件大小:")
for i in fileList:
print(getFileSize(i,'Byte'))getFileSIze 时传入不同 unit 即可获取不同单位的文件大小,也可以修改 roundNum 调整保留的小数点位数。


除此之外,也可以批处理文件例如批量改名(os.rename()),批量删除(os.remove())等等,修改对应函数即可。
2.批处理文件内容
批处理最常见的为寻找 target 字符或者替换 target 字符,寻找target字符上面已经给出,下面给出替换文件内容的Demo,其他操作可以在此基础上修改。
def replaceFileByTarget(path, target, new):
with open(path, 'r') as f:
text = f.read().replace(target, new)
open(path, 'w').write(text)
print("修改成功: {}".format(path))
fileList = getFile(rootDir)
for i in fileList:
replaceFileByTarget(i, "hello", "HELLO")
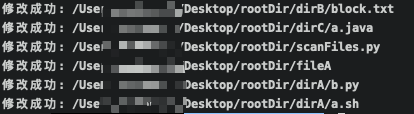
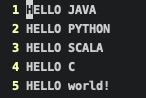
这里还是看下 fileA 的内容,可以看到内部的 hello xxx,都变成了 HELLO xxx。
四.总结
python 遍历文件主要是通过 os 实现,如果需要对 HDFS 文件操作,可以通过 org.apache.hadoop.fs.FileSystem 类操作,寻找,遍历文件的逻辑大致相同。