libtorch+yolov5
windows+libtorch+vs2019+yolov5项目部署实践总结
- 前言
-
- 环境配置
- 环境搭建参考:
- 给出我的libtorch配置
- GPU模型 导出 export代码
-
- 效果展示
- 结束
前言
这是本人第一篇博客,只是对近期学习工作的一些总结。主要是利用libtorch对pytorch训练的模型进行部署,之前也是成功使用pyinstaller将整个python项目进行打包成exe,但是不满足对方的需求才使用的libtorch。
环境配置
vs2019+opencv4.5+libtorch1.7.1:
1.vs2019下载:链接: link
2. opencv官网:链接: link
3. Libtorch下载:链接: link推荐下载release版本(版本需要与训练模型pytorch版本符合,cuda版本需要相符)
环境搭建参考:
https://blog.csdn.net/weixin_44936889/article/details/111186818
https://blog.csdn.net/zzz_zzz12138/article/details/109138805
https://blog.csdn.net/wenghd22/article/details/112512231
vs2019和opencv配置过程参考链接;
https://blog.csdn.net/sophies671207/article/details/89854368
给出我的libtorch配置
给出我的libtorch配置过程:新建空项目 新建main.cpp文件
1、新建项目->属性->VC++目录->包含目录
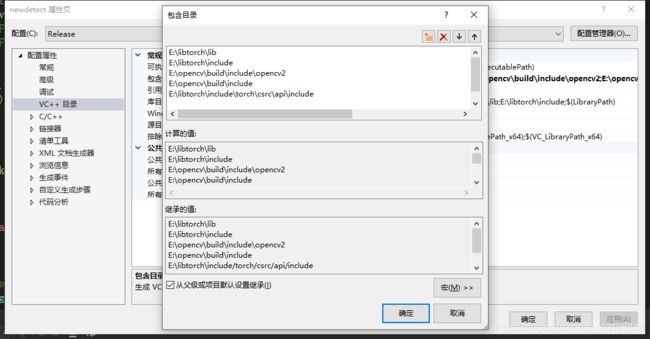
2新建项目->属性->VC++目录->库目录
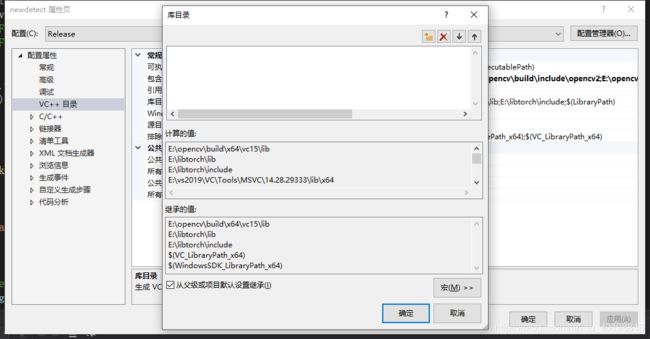
3新建项目->属性->C/C++目录->常规->附加包含目录
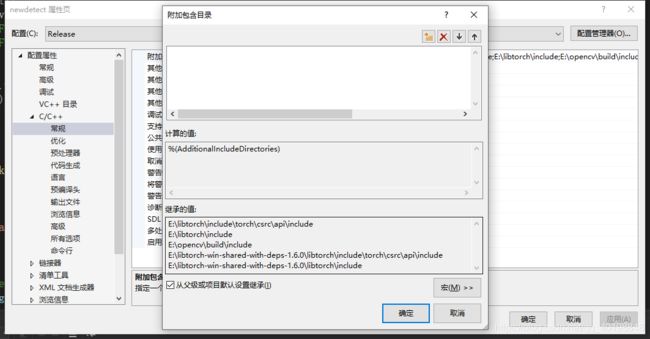
4新建项目->属性->C/C++目录->常规->SDL检查 :否
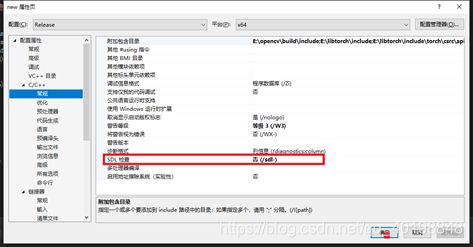
5新建项目->属性->连接器->输入->附加依赖项:写入以下
E:\opencv\build\x64\vc15\lib\opencv_world450.lib
c10.lib
asmjit.lib
c10_cuda.lib
caffe2_detectron_ops_gpu.lib
caffe2_module_test_dynamic.lib
caffe2_nvrtc.lib
clog.lib
cpuinfo.lib
dnnl.lib
fbgemm.lib
libprotobuf.lib
libprotobuf-lite.lib
libprotoc.lib
mkldnn.lib
torch.lib
torch_cuda.lib
torch_cpu.lib
kernel32.lib
user32.lib
gdi32.lib
winspool.lib
comdlg32.lib
advapi32.lib
shell32.lib
ole32.lib
oleaut32.lib
uuid.lib
odbc32.lib
odbccp32.lib
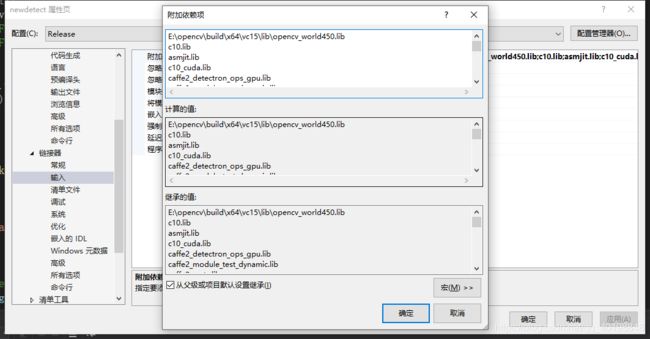
6新建项目->属性->连接器->命令行:输入/INCLUDE:?warp_size@cuda@at@@YAHXZ
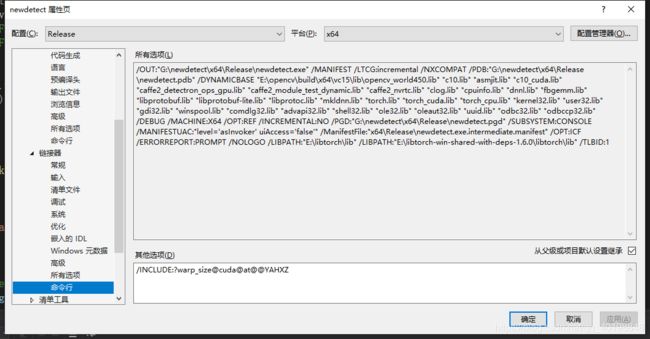
7新建项目->属性->C/C++目录->语言->符合模式 :否
配置好了以上环境,打包好的文件夹如下图:
权重文件:官方权重导出固定尺度模型即可 直接运行main.cpp即可。采用的samples文件夹下的图片进行测试。
main.cpp代码 十六行使用GPU时需注意
#include GPU模型 导出 export代码
注意修改导出模型尺度。
"""Exports a YOLOv5 *.pt model to ONNX and TorchScript formats
Usage:
$ export PYTHONPATH="$PWD" && python models/export.py --weights ./weights/yolov5s.pt --img 640 --batch 1
"""
import argparse
import sys
import time
sys.path.append('./') # to run '$ python *.py' files in subdirectories
import torch
import torch.nn as nn
import models
from models.experimental import attempt_load
from utils.activations import Hardswish, SiLU
from utils.general import set_logging, check_img_size
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='E:\\yolov5-master\\runs\\train\\exp\weights\\best.pt', help='weights path') # from yolov5/models/
parser.add_argument('--img-size', nargs='+', type=int, default=[352, 640], help='image size') # height, width
parser.add_argument('--batch-size', type=int, default=1, help='batch size')
opt = parser.parse_args()
opt.img_size *= 2 if len(opt.img_size) == 1 else 1 # expand
print(opt)
set_logging()
t = time.time()
# Load PyTorch model
model = attempt_load(opt.weights, map_location=torch.device('cuda')) # load FP32 model
labels = model.names
# Checks
gs = int(max(model.stride)) # grid size (max stride)
opt.img_size = [check_img_size(x, gs) for x in opt.img_size] # verify img_size are gs-multiples
# Input
img = torch.zeros(opt.batch_size, 3, *opt.img_size).to(device='cuda')
# image size(1,3,320,192) iDetection
# Update model
for k, m in model.named_modules():
m._non_persistent_buffers_set = set() # pytorch 1.6.0 compatibility
if isinstance(m, models.common.Conv): # assign export-friendly activations
if isinstance(m.act, nn.Hardswish):
m.act = Hardswish()
elif isinstance(m.act, nn.SiLU):
m.act = SiLU()
# elif isinstance(m, models.yolo.Detect):
# m.forward = m.forward_export # assign forward (optional)
#model.model[-1].export = True # set Detect() layer export=True
model.model[-1].export = False
y = model(img) # dry run
# TorchScript export
try:
print('\nStarting TorchScript export with torch %s...' % torch.__version__)
f = opt.weights.replace('.pt', '.torchscript.pt') # filename
ts = torch.jit.trace(model, img)
ts.save(f)
print('TorchScript export success, saved as %s' % f)
except Exception as e:
print('TorchScript export failure: %s' % e)
# ONNX export
try:
import onnx
print('\nStarting ONNX export with onnx %s...' % onnx.__version__)
f = opt.weights.replace('.pt', '.onnx') # filename
torch.onnx.export(model, img, f, verbose=False, opset_version=12, input_names=['images'],
output_names=['classes', 'boxes'] if y is None else ['output'])
# Checks
onnx_model = onnx.load(f) # load onnx model
onnx.checker.check_model(onnx_model) # check onnx model
# print(onnx.helper.printable_graph(onnx_model.graph)) # print a human readable model
print('ONNX export success, saved as %s' % f)
except Exception as e:
print('ONNX export failure: %s' % e)
# CoreML export
try:
import coremltools as ct
print('\nStarting CoreML export with coremltools %s...' % ct.__version__)
# convert model from torchscript and apply pixel scaling as per detect.py
model = ct.convert(ts, inputs=[ct.ImageType(name='image', shape=img.shape, scale=1 / 255.0, bias=[0, 0, 0])])
f = opt.weights.replace('.pt', '.mlmodel') # filename
model.save(f)
print('CoreML export success, saved as %s' % f)
except Exception as e:
print('CoreML export failure: %s' % e)
# Finish
print('\nExport complete (%.2fs). Visualize with https://github.com/lutzroeder/netron.' % (time.time() - t))
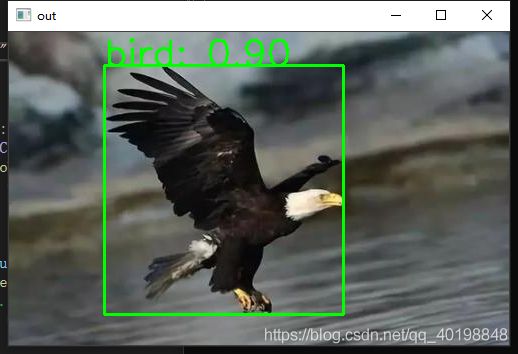
效果展示
测试结果:

视频测试:
2021-01-20 14-31-49
libtorch+yolov5
另一个视频链接: link
结束
自己训练的模型效果就不展示了,感谢大家观看,请多多关注,共同学习进步!
###问题 关于forward耗时很长的问题 其实早在我批处理多张图片的时候发现了 如下图:前两张很慢 后面正常。自己查过也在GitHub咨询过 原因可能是libtorch1.7.1版本存在warm up的问题。
