3.1 Distributing Data across the Web
RDF,RDFS,OWLdoushi 都是意RDF为基础的语义网的基本表示语言。RDF解决了语义Web中的一个基本问题:管理分布式数据。所有其他的语义网标准都建立在分布式数据基础上。RDF在很大程度上依赖于Web的基础设施,使用它的许多熟悉且经过验证的特性,同时扩展它们,为分布式数据网络提供基础。
我们习惯的Web是由文件相连组成的。一个文档和它所描述的世界上的事物之间的任何联系都只能由阅读文档的人来完成。一个关于莎士比亚的文档和一个关于埃文河畔斯特拉特福的文档之间可能有链接,但没有一个实体是莎士比亚的概念,也没有一个实体和斯特拉特福联系在一起。
在语义网中,我们把涉及到的世界中的事情都看作资源,一个资源可以使某人想讨论的任何事情。 Shakespeare、 Stratford、X的值、得克萨斯州的所有奶牛,都可以作为语义网的资源。不可否认,这是对“资源”一词的一种相当奇怪的用法,但是像实体或事物这样的替代方法,可能更准确,有它们自己的问题。在任何情况下,资源都是语义Web标准中使用的单词。事实上,语义Web (RDF)中的基本技术名称在本质上使用了这个词。RDF代表资源描述框架。
在信息网络中,任何人都可以为我们对资源的知识做出贡献。正是当前网络的这一方面使其以前所未有的速度增长。为了实现语义Web,我们需要一个允许信息在Web上分布的数据模型。
DISTRIBUTING DATA ACROSS THE WEB
数据通常被表示为表格形式,行表示记录,列代表每条记录的属性。
考虑其他一些不同的描述web上分布式数据的策略。在所有这些策略中,数据的某个部分可能在一台电脑上表示,另外的部分在其他计算机上表示。图3.1描述了一个分布式信息在多个电脑的策略。每个联网的机器负责维护表中一个或多个完整行的信息。关于实体的任何查询都可以由存储其对应行的机器响应。一台机器负责“十四行诗78”和爱德华二世的信息,而另一台机器负责你喜欢的信息。
这种分发解决方案提供了相当大的灵活性,因为机器可以共享表示多个个体信息的负载。但由于它是数据的分布式表示,因此需要服务器之间进行一些协调。特别是,每个服务器必须共享关于列的信息。一台服务器上的第二列是否与另一台服务器上的第二列对应相同的信息?这并不是一个不可克服的问题,事实上,它是数据分布的一个基本问题。服务器之间必须有一些一致同意的协调。在本例中,服务器必须能够以全局方式指示每一列对应的属性
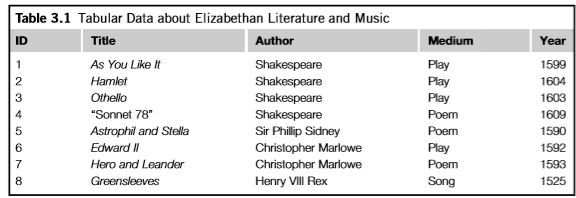
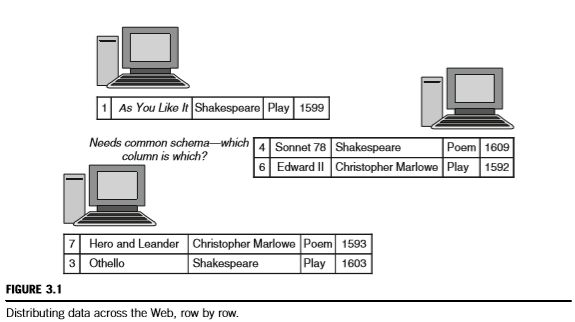
图3.2显示了另一种策略,其中每个服务器负责原始表中的一个或多个完整列。在本例中,一个服务器负责发布日期和媒体,另一个服务器负责标题。此解决方案与图3.1的解决方案具有不同的灵活性。图3.2中的解决方案允许每台机器负责一种信息。如果我们对发布日期不感兴趣,则无需考虑来自该服务器的信息。如果我们想要指定关于实体的一些新内容(例如,原稿有多少页),我们可以添加一个包含这些信息的新服务器,而不会破坏其他服务器。
这个解决方案类似于图3.1中的解决方案,因为它需要在服务器之间进行一些协调。在这种情况下,协调与要描述的实体的身份有关。我如何知道一个服务器上的第3行与另一个服务器上的第3行引用相同的实体?此解决方案需要描述的实体的全局标识符。
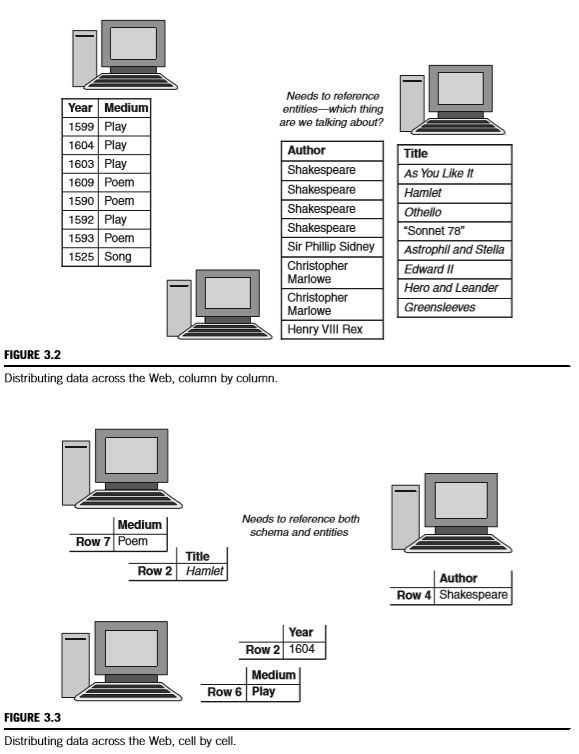
图3.3中概述的策略是前两种策略的组合,其中信息既不是逐行分布的,也不是逐列分布的,而是逐单元分布的。每台机器负责表中的一些单元格。该系统结合了前两种策略的灵活性。两个服务器可以共享单个实体的描述(在图中,Hamlet的年份和标题分别存储),它们还可以共享特定属性的使用(在图3.3中,第6行和第7行的介质在不同的服务器上表示)。
如果我们希望我们的数据分发系统真正支持AAA的口号“任何人都可以谈论任何话题”,那么这种灵活性是必需的。如果我们认真对待AAA口号,任何服务器都需要能够声明任何实体(如图3.2所示),而且任何服务器都需要能够指定实体的任何属性(如图3.1所示)。图3.3中的解决方案具有这两个优点。

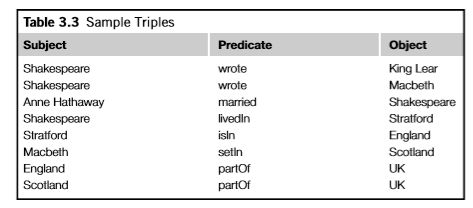
但是这个解决方案也结合了其他两种策略的成本。现在不仅需要列标题的全局引用,还需要行的全局引用。实际上,每个单元格必须用三个值表示:行的全局引用、列的全局引用和单元格本身的值。第三种策略是RDF采用的策略。我们将在本章的后面部分看到RDF如何解决全局引用的问题,但是现在,我们将主要关注表单元格如何在RDF中表示和管理。
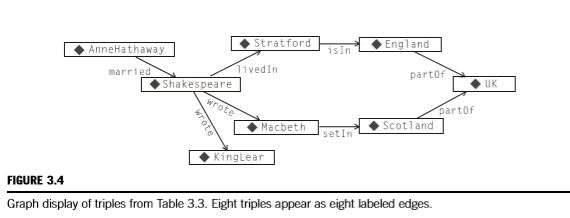
由于单元格由三个值表示,RDF的基本构建块称为三元组。行标识符称为三元组的subject(遵循基本语法中的概念,因为subject是语句的内容)。列的标识符称为三元组的谓词(因为列指定行中实体的属性)。单元格中的值称为三元组的对象。表3.2显示了图3.3中的三元组作为主语、谓语和宾语。
当一个以上的三元组引用同一个实体时,三元组变得更加有趣,如表3.3所示。当不止一个三元组引用同一事物时,有时可以方便地将三元组看作是一个有向图,其中每个三元组是主体到对象之间的一条边,边上的标签是谓词,如图3.4所示。图3.4中的图形可视化表达了与表3.3相同的信息,但是我们所知道的关于莎士比亚的一切(无论是作为主题还是对象)都显示在一个节点上。
3.2 Merging Data from Multiple Sources
我们开始将RDF描述为在多个数据源上分发数据的一种方式。但是,当我们想要使用这些数据时,我们需要再次合并这些源。三元组表示的一个值是实现这种合并的容易程度。由于信息被简单地表示为三元组,因此来自两个图的合并信息就像组成来自每个单独图的所有三元组的图一样简单。让我们看看这是如何在RDF中实现的。
假设我们有与表3.3中的示例相关的另一个信息源,即莎士比亚写的戏剧列表或英国部分地区的列表。如表3.4和表3.5所示,它们将被表示为三元组。它们中的每一个都可以以图形的形式显示,就像在原始表中一样,如图3.5所示。
当我们把这三个来源的信息合并在一起时会发生什么?我们只需要得到图3.4和图3.5中所示的所有三元组的图。合并图3.4和3.5中的图以创建图3.6中所示的组合图是一个简单的过程,但是只有当知道每个源图中的哪个节点匹配时才会这样做。

3.3 Namespaces, URIs, and Identity
重点是回答这个问题:什么时候一个图的节点看做是和另外一个图的节点是同一个?在RDF中,用URIs来解决这个问题。
在前面的图中,我们已经用唯一的名字标出了图中的节点和边,像Shakespeare 或者 Wales。在语义网中,这还没有足够的信息来确定两个节点是否确定是同一个。为什么不能确定?世界上不是只有一件事是大家都同意的,那就是莎士比亚吗?当提到网络协议时,永远不要说“每个人”。在某些地方,有人会提到的不是历史上的莎士比亚,而是故事片《莎翁情史》中的同名角色,这与历史人物几乎没有相似之处。“莎士比亚”是网络上出现的比较稳定的概念之一;考虑一下“Washington”或“Bordeaux”这样的名字的参考范围。“要在语义Web环境中合并图表,我们必须更加具体:在什么意义上我们指的是莎士比亚这个词?”
RDF从基本的Web技术中借用了它对这个问题的解决方案-URI。今天Web的普通用户也对URI的语法和格式很熟悉,因为URL,比如 http://www.WorkingOntologist.org/Examples/ Chapter3/Shakespeare#Shakespeare.但是URI作为web资源全局变量的重要性还没有被重视。如果Web上的两个代理想引用相同的资源,Web上的推荐做法是它们使用该资源的公共URI。这并不只是语义网的规定,web通常也这么做。全球命名导致全球网络效应。
URIs看起来和URLs很想,事实上,URL只是URI的一个特殊情况。为什么web会有这样两个做法?简化一些,URI是一个全球范围的标识符。任意两个web应用想使用同一个事物,只需要使用同样的URI。但是URI的语法使得“间接引用”它成为可能,也就是说,使用URI中的所有信息(服务器名字,协议,端口号,文件名称)来定位web上的一个文件。如果所有这些部分都能工作,那么间接引用就成功了;协议定位在指定端口上运行的指定服务器,以此类推。这种情况下,URI不仅仅是URI,也是一个URL。从建模的角度来看,这种区别并不重要。但是从在语义Web上拥有模型的角度来看,URI可以间接引用这一事实允许模型参与到全局Web基础设施中。
RDF应用了URI的概念来解决图合并中的身份识别问题。应用很简单:如果两个图中的两个节点有同样的URI,可以将这两个节点合并。也就是说,这看起来很虚伪,通过依赖另一个标准来“解决”节点标识的问题。换个说话,因为身份识别问题并不只是出现在语义网中,在web中也很常见,所以在两种情况下使用同样的策略是明智的。


3.3.1 Expressing URIs in print
uri非常适合在万维网上表示身份,但在表示模型时,尤其是在打印时,详细地写出uri通常有点麻烦。因此,对于本书中的示例,我们使用一个名为qnames的URI缩写方案的简化版本。在这个缩写中,URI用两部分表示:一个命名空间和一个标识符,用冒号间隔。因此,命名空间geo中的标识符England的qname表示形式就是geo:England。 RDF/XML标准详尽的规则,允许程序员将名称空间映射到其他URI表示( http://)。在本书中的例子,我们将对所有uri使用简单的qname形式。这很重要,但是,注意qnames并不是web上的全局标识符;只有完整的描述URIs才是全的web名字。因此,任何一个qname表示,原则上必须伴随着一个相应的命名空间的声明。
在Web和XML规范中,通常坚持uri不包含嵌入式空间。比如,在web中通常不会出现标识符“part of”。我们遵守interCap公约,将由多个单词组成的名称转换为没有空格的标识符,方法是将每个单词首字母大写。part of变成了partOf,Great Britain变成了GreatBritain,Measure for Measure 变成了MeasureForMeasure。
在一个数据源中使用多个名称空间没有限制,甚至在一个三元组中也没有限制,就数据模型和标准而言,名称空间的选择完全不受限制。然而,在一个名称空间中引用相关标识符是常见的做法。比如:表3.4故意整个不爱3.5中的所有文学或者地理信息都可以列出一个命名空间,建议名字,say,lit或者geo。严格来说,这些名字应该和全程URIs相一致。比如,lit代表 http://www .WorkingOntologist.com/Examples/Chapter3/Shakespeare#,geo代表 http://www .WorkingOntologist.com/Examples/Chapter3/geography#。
处于解释语义网的模型的目的,详细的URIs并不重要,最重要的是,从现在开始,我们将省略这些绑定。在很多例子中,我们将进一步讨论缩写的概念;在我们在整个示例中使用单个名称空间的情况下,我们假设有一个默认的命名空间声明,允许我们可以简单地使用符号名称,前面加一个:,来引用uri,比如:Shakespeare, :JamesDean, :Researcher.

使用qnames,三元组集合如3.6,3.7所示。对比3.6和3.4,3.7和3.5,看起来并没有变得简单。像3.8一样,一些三元组必须使用具有不同名称空间的标识符。

在表3.8中,我们介绍了一个新的命名空间bio:,没有解释它对应哪个实际的URI。要使此模型参与Web,必须填写此信息。但是从建模的角度来看,这个细节并不重要。对于本书的其余部分,我们将假设所有qname的前缀都已定义,即使在打印中没有显式指定该定义。
3.3.2 Standard namespaces
使用URI作为全局标识符的标准允许对任何符号进行全局引用。这意味着我们可以知道世界上任何地方的任何两个人何时在谈论同一件事。URI的这个属性为标准组织(如W3C)提供了一种简单的方法来指定标准中某些术语的含义。W3C提供了专门术语的定义,比如type,subClassOf,Class,inverseOf等等。但是,这些标准旨在通过语义Web在全球范围内应用,所以这些标准引用这些保留字的方式与它们引用语义Web上的任何其他资源的方式相同。
W3C定义了一些标准的命名空间用来使用web技术,包括xsd:,用来定义 XML模式 ;xmlsn:用于XML的命名空间等等。语义网也完全一样,对语义网的主要层也定义了命名空间。遵循W3c的标准,我们qnames来引用这些术语,标准的命名空间定义如下:
rdf:表示RDF中的标识符。这个在标准中定义的标识符集非常小,用于在RDF中定义类型和属性。全局URI是 http:// www.w3.org/1999/02/22-rdf-syntax-ns#
rdfs: 表示在RDFS语言中使用的标识符。全局URI是 http://www.w3.org/2000/01/rdf-schema#。
owl:表示在web本体语言中使用的标识符。这个命名空间的全局URI是 http://www.w3.org/2002/07/owl#
这些URIs提供了一个很好的URI之间的交互例子。为了建模,任意一个这些命名空间中的URI都参考了W3C中的专业术语,这些属于由W3C用来生命RDF标准。但是这些属于也可以被间接引用,如果我们看这个服务器, www.w3.org,有一个页面在 2000/01/rdf-schema这个目录下,有一个入口 subClassOf,可以提供一些这个资源的补充信息。从建模的角度来看,没有必要间接引用这个URI,但是从Web集成的角度来看,简介引用URI是至关重要的。
3.4 Identifiers in the RDF Namespace
RDF数据模型详细说明了三元组概念和合并三元组集合的思想。随着名称空间的引入,RDF使用Web的基础结构来表示关于如何引用特定实体的协议。RDF标准本身利用名称空间基础设施的有事,来定义一个小数量的标准标识符名称空间中定义的标准,称为fdf。
rdf:type 是RDF中一个基本分类系统的属性。比如,我们可以使用类别信息表达几个剧作家之间的关系,如表3.9. 这些三元组中的rdf:type主题可以使任何的标识符,主题将会被认为是类别。使用rdf:type作为类别没有 任何限制,类型可以有无穷多个类型,如表3.10所示。


当我们大声读三元组的时候,按照主语/谓语/宾语的顺序来阅读(无论如何,在英语中)是很容易理解的,,这样的话表3.9中的第一个三元组应该这样读Shakespeare type Playwright.不管怎样变化,这是一个错误的语法。“Shakespeare has type Playwright或者“The type of Shakespeare is Playwright会更好一些。但是,由于我们从来没有控制过其他实体(在本例中是W3C)如何选择它们的名称,所以我们没有权利更改这些名称。
对于选择rdf:type作为名字的资源,如果改叫 rdf:isInstanceOf ,读起来会比较符合英文。我们读的时候只能在里面加连词,对于这个三元组,我们可以增加has,Shakespeare [has] type Playwright,或者有时候is。
rdf:Property是RDF中用作类型的标识符,用来指示当另一个标识符用作谓词而不是主语或宾语时。我们可以声明到目前为止在本章中用作谓词的所有标识符,如表3.11所示

CHALLENGE: RDF AND TABULAR DATA
CHALLENGE 1
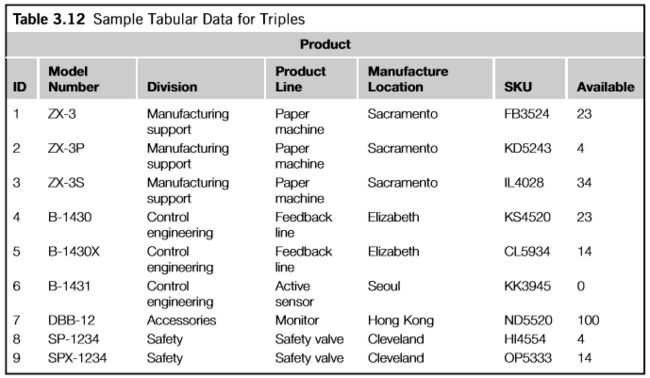
给定一个关系数据库的表格,描述产品、供应商和产品的库存信息,生成一个RDF图来反映表格的内容,以这样的方式:保留了信息意图,但是数据现在可以进行RDF操作,比如合并和RDF查询。
Solution
表哥的每一行都标识语一个类型相同的单独的实体。类型由表格的名字给定,Product,表格的每一列可以提供一些信息,比如model number。我们想在RDF中表示这些数据。
由于每一行表示了不同的实体,所以每一行应该有一个独特的URI。幸运的是,对惟一标识符的需求在数据库中与在语义Web中一样,所以有一个(本地的)惟一标识符可用——即主表键,在本例中是名为ID的列。对于语义Web,我们需要一个全局惟一标识符。形成这种标识符的最简单方法是为数据库本身使用一个URI(如果数据库在Web上,甚至可以使用URL)。使用URI作为数据库中所有标识符的命名空间。一个机械制造公司的数据库,我们可以给命名空间其名为:mfg:。
然后我们可以为每一行建立一个标识符,把表格的名字product和表格主键连接在一起,表示成 mfg: namespace,就会得到一下标识符: mfg:Product1, mfg:Product2等。
表格的每一行都描述了这条记录的一些事情,也就是model number等。为了在RDF中表达这些,每一个都可以作为描述Products的一个属性。但是,就像对行使用惟一标识符一样,我们需要对这些属性使用全局惟一标识符。我们可以使用和个体一样的命名空间,但是因为两张表可以有相同的列名,可以将表格名字和列名连接起来。这就导致属性写法: mfg:Product_ModelNo, mfg:Product_Division。

这样就可以用三元组的形式来描述表格。表格中的每一项都对应一个三元组,这就是说,一个n行c列的表格,将会出现n*c个三元组。表3.12有7行9列,表3.13如下。
表格中的三元组和我们之前看到的有区别,尽管这些三元组中的主语和谓语都是RDF资源,宾语不是RDF资源而是文字数据,也就是说,字符串证书等等。RDF是一个数据描述系统。RDF三元组中的宾语使用XML的所有数据类型作为可能的值。
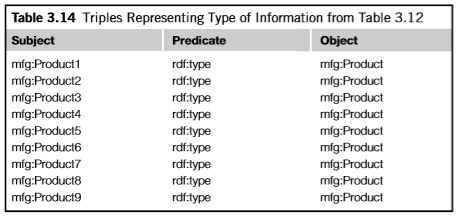
表3.12的每一行对应一个产品,我们可以给每行增加一个三元组,详细说明表格描述的个体的类型,如表3.14.
表3.7表达的信息完整的三元组描述是3.12.类型在图中显示为连接。
3.5 Higher-order Relationships
人们通常会觉得只用主谓宾这样的三语组形式,非常有限。用一种陈述来表达另外一种陈述。这个过程叫做reification。这不是语义网建模的专有问题,同样出现在其他数据建模中,比如关系数据库和对象系统。事实上,与语义网中物化过程仅仅是借用了关系数据库模式的解决方法,使用映射从关系数据表到RDF,在关系数据表中,可以简单地创建一个包含更多列的表来添加关于三元组的附加信息,所以表3.1中,简单的陈述Shakespeare wrote Hamlet,用表格中的一行,一列是作者,一列是work,一列是标题。为了得到这个事件的更多信息,再加列即可。在RDF的挑战中我们看到,一行被多个三元组表示,一列对应一个三元组。这些三元组的主语都是一样的:一个资源也就是表格中的一行。
从表3.13可以看出,几个三元组有同样的主语,并且表中每一列各有一个三元组。这种具体化方法在关系建模中有很强的历史渊源,并且在广泛的建模应用程序中运行良好。即使数据没有从表格形式导入,它也可以应用于RDF中。 Shakespeare wrote Hamlet in 1601可以通过以下三元组表示:
bio:n1 bio:author lit:Shakespeare.
bio:n1 bio:title “Hamlet”.
bio:n1 bio:publicationDate 1601

explicit reification: rdf:subject, rdf:predicate, andrdf:object(W3C RDF 标准)
例子:Wikipedia says Shakespeare wrote Hamlet
q:n1 rdf:subject lit:Shakespeare;
rdf:predicate lit:wrote;
rdf:object lit:Hamlet.
web:Wikipedia m:says q:n1.
注意,仅仅因为我们断言了关于q:n1的具体化三元组,并不一定我们也断言了三元组本身:lit:Shakespeare lit:wrote lit:Hamlet.
3.6 Alternatives for Serialization
目前,我们表达式一个RDF三元组使用主谓宾的列表形式或者有向图。尽管这些形式表达三元组简单并且清楚,但这并不是最紧凑的形式,或者不是对人类友好,能够看清实体之间联系的形式。
3.6.1 N-Triples
最简单的形式叫做N元组,这种形式的资源使用最原始的URIs,每一个URI写在一对尖角括号里,这种形式资源用主谓宾的顺序表示,后面加.。比如,如果命名空间mfg对应的地址是 http://www.WorkingOntologist.org/Examples/Chapter3 Manufacture#,表3.14的第一个三元组可以被表示为:
http://www.WorkingOntologist.org/Examples/Chapter3/Manufacture#Product1 http://www.WorkingOntologist.org/Examples/Chapter3/Manufacture#Product 在一本书的页面上打印N-Triples是很困难的——序列化不允许在三元组中添加新行(正如我们在这里所做的,以便将其放入页面中)。 本书中我们使用另外一种比较紧凑的RDF序列方式叫做Turtle。一个实际的ntriple文件在一行中包含整个三元组。Turtle结合了来自N-Triples的三元组的清晰显示和qname的简洁。 由于Turtle使用qnames,所以必须有本地qnames和全局URIs的绑定,Turtle一开始就需要对这些绑定进行定义。比如,我们可以定义挑战例子中需要的qnames如下: 本地的qnames声明后,Turtle就可以提供一个非常简单的方法来描述三元组列出来的三个资源,使用qname缩写,以主谓宾的顺序,后面加一个句号。 mfg:Product1 rdf:type mfg:Product . 最后的句号可以直接跟在宾语后面,但是通常我们会在前面加一个空格,来突出它。空格是可选的。 几个三元组共用同一个主语是很常见的。Turtle对这种数据提供了一种更加紧凑的写法。第一个三元组像之前一样,用主谓宾的顺序,但是结尾不加句号,而是使用分号表示后面还有一个三元组公用这个主语。对于这个三元组,只需要指定谓词和对象。表3.13和3.14中关于Product1和Product2用Turtle书写如下 如果出现好几个主语共用同样的谓语和宾语时,Turtle提供了一种紧凑方式,使用逗号把主语间隔开。比如莎士比亚有三个孩子,名字分别是。。。。如下 Turtle也提供了一些缩写来提高简洁性。在这本书中,我们只用到了一些。其中使用最广泛的一个缩写是rdf:type缩写味a。因为我们通常会说“Product1 is a Product。 虽然Turtle方便人类使用,而且打印页面更紧凑,但是许多Web基础设施习惯于用HTML或更一般的XML表示信息。这章主要用RDF/XML。刚才显示的关于Product1和Product2的信息如下RDF/XML所示。本节中,主语都被XML的属性rdf:about来引用。RDF/XML的具体细节这里不讨论。http://www.w3.org/TR/rdf-syntax-grammar/. RDF还允许完全没有任何Web标识的资源,但是,我们为什么要表示Web上没有标识的资源呢? 有时我们知道存在着某种东西,甚至知道一些关于它的事情,但我们不知道它的身份。例如,假设我们想要表达这样一个事实,莎士比亚有一个情妇,她的身份仍然未知。但我们知道一些关于她的事情;她是个女人,住在英国,她是《十四行诗78首》的灵感来源。用RDF表示这些语句非常简单,但是我们需要一个情妇的标识符。在Turtle中,我们可以这样表达: lit:Mistress1 rdf:type bio:Woman; bio:LivedIn geo:England. lit:Sonnet78 lit:hasInspiration lit:Mistress1. 但是如果我们不想要情妇的标识符,我们该如何进行呢?RDF允许在这种情况下使用“空白节点”或简称bnode。如果我们要用一个?来表示一个bnode,那么三元组将如下所示: 这种写法是RDF合法的,但是也存在一个问题,如果有多个空白节点,我们怎么区分,问号到底引用的是哪一个?由于这个原因,Turtle包含了一个紧凑且明确的符号来描述空白节点。空白节点是通过将它作为主语的所有三元组放在方括号([and])之间来表示的,因此: 习惯上(虽然不是必需的)在左括号后面留下空白,以表明我们的行为就好像这些三元组有一个subject,尽管没有指定任何subject。我们可以在其他三元组中引用这个空白节点,方法是将整个括起来的序列包含在空白节点中。此外,rdf:type的“a”缩写在此上下文中特别有用。因此,我们关于激发《十四行诗78首》灵感的情妇的整个陈述在Turtle中是这样的: RDF中的这种表达式可以用英语直接表达为:“Sonnet78 has [as] inspiration a Woman[who] livedin England.”这个女人的身份是未知的。当我们开始描述OWL (Web本体语言)时,对空白节点使用括号符号将变得特别重要,因为它非常特别地使用bnode。 莎士比亚孩子在书中打印时应该按照一定次序,可是从RDF的角度来看,他们没有次序,他们都是三元组,莎士比亚和三个孩子之间都存在一个关系。我们怎么来说明这个次序呢,在RDF中应该怎么处理? RDF提供了一种以列表格式对元素排序的工具。一个有序列表可以很容易地用Turtle表达如下: RDF是首选的数据建模系统,放弃了简洁性,获取了灵活性。任意两个数据元素之间的联系可以被明确表示,允许以非常简单的模型来合并数据。不需要对表的列进行排列,使它们“匹配”或担心某个特定列中的数据“丢失”。关系(以熟悉的主语/谓语/宾语形式表示)要么存在,要么不存在。因此,合并数据简化为一个简单的问题,即考虑来自所有源的所有这些语句,并将它们放在一个地方。 在这样一个体系中,唯一的挑战是身份的挑战。我们如何为任何实体的标识提供一个全局符号?幸运的是,这个问题并不是RDF数据模型所特有的。Web本身的基础设施也有同样的问题,并且有一个标准的解决方案:URI。RDF借用了这个解决方案。由于RDF是一种Web语言,一个基本的考虑是跨Web分布来自多个源的信息。在网络上,AAA的口号是:任何人都可以谈论任何话题。RDF支持这个口号,它允许任何数据源引用任何名称空间中的资源。甚至一个三元组也可以引用多个名称空间中的资源。作为一个数据模型,RDF提供了一个清晰的规范,说明了从多个源合并信息时必须发生什么。它不提供实现这些过程的算法或技术。这些技术是下一章的主题。 RDF (Resource Description Framework)—This distributes data on the Web. Triple—The fundamental data structure of RDF. A triple is made up of a subject, predicate, and object. Graph—A nodes-and-links structural view of RDF data. Merging—The process of treating two graphs as if they were one. URI (Uniform Resource Indicator)—A generalization of the URL (Uniform Resource Locator), which is the global name on the Web. namespace—A set of names that belongs to a single authority. Namespaces allow different agents to use the same word in different ways. qname—An abbreviated version of a URI, it is made up of a namespace identifier and a name, separated by a colon. rdf:type—The relationship between an instance and its type. rdf:Property—The type of any property in RDF. Reification—The practice of making a statement about another statement. It is done in RDF using rdf:subject, rdf:predicate, and rdf:object. N-Triples, Turtle, RDF/XML—The serialization syntaxes for RDF. Blank nodes—RDF nodes that have no URI and thus cannot be referenced globally. They are used to stand in for anonymous entities.3.6.2 Turtle


![]()

3.7 RDF/XML

3.8 Blank Nodes

![]()
![]()
3.8.1 Ordered information in RDF
![]()

Summary
Fundamental concepts