【网盘项目日志】20210601:Seafile 离线下载系统开发(2)
诶嘿,儿童节快乐~
文章目录
-
- 书接上回
- 研究 seafevents 的 event 机制
- 编写 handler
- 配置文件系统
- 数据库部分
- 定义定时任务
-
- 实现 Worker
- 注册 Worker 和启动类
- 写 Seahub 的路由和 View
- 前端
-
- 更正前一天的内容
- 做一个简单的界面
- Seafile_API 问题
- 定时刷新列表数据
- 上传完成后刷新文件列表
书接上回
咱们不是要开发离线下载系统嘛,按照当时的想法,咱们要把新的系统加到 seafevents 里面去。大概的逻辑是这样的:
- 用户向 django 端发送添加链接的请求;
- django 收到链接,将链接通过 event 方式转交给 seafevents 进程;
- seafevents 收到 event,将 Task 加入数据库,status 为 waiting;
- 在 seafevents 中有一个周期任务,每隔 5 秒检查一次是否有新的任务;
- 若检查到新的任务,将任务信息取出,并置 status 为 downloading;
- 调用 Aria2 接口,将文件下载到一个临时位置;
- 调用 SeafileAPI,将临时文件添加到 SeafileFS 中;
- 置 status 为 done。
另外考虑了几个特殊情况:
- 如果 Aria2 下载失败:置 status 为失败,并在 comment 字段写明原因。
- 如果下载到一半服务中止:下一次服务开启后会先检查所有 downloading 任务,并调用 Aria2 重新开始下载。
研究 seafevents 的 event 机制
前面的博客里面也说了,seafevents 除了可以执行定时任务,还可以接受来自 seahub 和 seafile 的 event,在审计系统中就有使用:
handlers.add_handler('seahub.stats:user-login', UserLoginEventHandler)
handlers.add_handler('seaf_server.stats:web-file-upload', FileStatsEventHandler)
handlers.add_handler('seaf_server.stats:web-file-download', FileStatsEventHandler)
handlers.add_handler('seaf_server.stats:link-file-upload', FileStatsEventHandler)
handlers.add_handler('seaf_server.stats:link-file-download', FileStatsEventHandler)
handlers.add_handler('seaf_server.stats:sync-file-upload', FileStatsEventHandler)
handlers.add_handler('seaf_server.stats:sync-file-download', FileStatsEventHandler)
可以看到,这里就是将文件的 6 种操作与一个 handler 绑定了。那么,这些 event 是在哪里被发出的呢?
我尝试在 seahub 中寻找 web-file-upload,不过并没有找到有用的信息。显然,6 种文件操作的事件并不是从 seahub 中发出的,而其前缀 seaf_server 也印证了我这个想法。我尝试找 user-login,这次我找到些有用的东西:
try:
seafile_api.publish_event('seahub.stats', 'user-login\t%s\t%s\t%s' % (email, timestamp, org_id))
except Exception as e:
logger.error('Error when sending user-login message: %s' % str(e))
原来是用了 publish_event 方法,而它的参数居然是直接用 \t 来隔开的,不得不说真的非常简单粗暴啊。
不过我们发现,seahub 中向 seafevents 发送事件,居然是调用了 seafileAPI,也就是说本质上这个事件是先从 seahub 发送到 seafile-server,然后再由 seafile-server 发送到 seafevents 的?让我们来验证一下。
打开 seafile-server 代码,搜索 publish_event,找到了这样的语句:
json_t *msg = json_object();
json_object_set_new (msg, "content", json_string(content));
json_object_set_new (msg, "ctime", json_integer(time(NULL)));
g_async_queue_push (async_queue, msg);
原来是用了一个 g_async_queue。然后在 seafevents 里面:
while 1:
try:
msg = seafile_api.pop_event(channel)
except Exception as e:
logger.error('Failed to get event: %s' % e)
time.sleep(3)
continue
if msg:
try:
message_handler.handle_message(session, channel, msg)
except Exception as e:
logger.error(e)
finally:
session.close()
else:
time.sleep(0.5)
每隔 0.5 秒调用一次 seafile_api.pop_event,同样简单粗暴!
那么到这里,我们了解到了一些新知识:
- seafevents 的使用必须依托一个有效的 seafile-server,seafevents 通过 searpc 连接到 seafile-server;
- seahub 中加载的 seafevents 仅仅是读取了数据库信息,然后连接到 seafevents 配置文件中的数据库,这样可以使用 seafevents 中的数据库查询语句,而本身并没有启动 seafevents 的 app(main);
- seahub 发出的 event 经由 seafile-server 发送到 seafevents。
编写 handler
模仿 statistics 模块里面的 handler,我也做了一个 handler:
def OfflineDownloadEventHandler(session, msg):
elements = msg['content'].split('\t')
if len(elements) != 3:
logging.warning("got bad message: %s", elements)
return
repo_id = elements[0]
path = elements[1]
user_name = elements[2]
# add_offline_download_record(appconfig.session_cls(), repo_id, path, user_name)
add_offline_download_record(session, repo_id, path, user_name)
def register_handlers(handlers):
handlers.add_handler('seahub.stats:offline-file-upload', OfflineDownloadEventHandler)
这个事件目前还没有在 seahub 中定义,我们先留着它。
配置文件系统
配置文件我想弄成一个这样的格式,写在 seafevents.conf 里面:
# Enable Aria2 offline download
[OFFLINE DOWNLOAD]
enabled = true
tempdir = /tmp/offline-download
workers = 1
max-size = 800mb
我模仿文件搜索系统,先定义了一个 HAS_OFFLINE_DOWNLOAD 全局变量:
# offline download related
HAS_OFFLINE_DOWNLOAD = False
if EVENTS_CONFIG_FILE:
def check_offline_download_enabled():
enabled = False
if hasattr(seafevents, 'is_offline_download_enabled'):
enabled = seafevents.is_offline_download_enabled(parsed_events_conf)
if enabled:
logging.debug('offline download: enabled')
else:
logging.debug('offline download: not enabled')
return enabled
HAS_FILE_SEARCH = check_offline_download_enabled()
然后在对应地方,我写了检测函数:
def get_offline_download_conf(config):
'''Parse search related options from seafevents.conf'''
if not has_offline_download_tools():
logging.debug('offline downloader is not enabled because Aria2 is not found')
return dict(enabled=False)
section_name = 'OFFLINE DOWNLOAD'
key_enabled = 'enabled'
......
还有一些细节的地方就不放了,反正是把前面学到的东西全用上了。
不得不说,前面从 pro 里面借 (偷) 三个功能的经历真的让我学会不少东西,现在简直轻车熟路(不是
数据库部分
模仿病毒扫描系统,我创建了 OfflineDownloadRecord 的 model,并写了一些增删改查的数据库语句:
class OfflineDownloadRecord(Base):
__tablename__ = 'OfflineDownloadRecord'
odr_id = Column(Integer, primary_key=True, autoincrement=True)
repo_id = Column(String(length=36), nullable=False, index=True)
path = Column(Text, nullable=False)
owner = Column(DateTime(), nullable=False)
timestamp = Column(DateTime(), nullable=False)
size = Column(BigInteger, nullable=False, default=0)
status = Column(SmallInteger, nullable=False, comment='0=Unknown, 1=Waiting, 2=Downloading, 3=OK, 4=Error')
comment = Column(Text, nullable=False)
__table_args__ = {
'extend_existing':True}
增删改查太多了,就不在这里放了。不过在这里说一句,seafevents 里面用的 SQLAlchme 是真的强大,自己在使用的时候真的有被舒服到。
定义定时任务
前面说了,咱们要弄一个每隔 5 秒获取所有新任务的接口。
模仿 Virus Scan,我们也来做一个定时任务。
实现 Worker
要想定时任务。。。首先要任务嘛,对不对。。。
首先模仿 Virus Scanner,我们做一个专门用于 Worker 的数据传输类:
class OfflineDownloadTask(object):
def __init__(self, odr_id, repo_id, path, url, owner):
self.odr_id = odr_id
self.repo_id = repo_id
self.path = path # The path is actually the dir
self.url = url
self.owner = owner
然后定义我们的线程执行类和方法:
class OfflineDownload(object):
def __init__(self, settings):
self.settings = settings
self.db_oper = DBOper(settings)
self.thread_pool = ThreadPool(self.download_file, self.settings.max_workers)
self.thread_pool.start()
def restore(self):
# Check and restore all the interrupted tasks.
task_list = self.db_oper.get_offline_download_tasks_by_status(OfflineDownloadStatus.DOWNLOADING)
for row in task_list:
self.thread_pool.put_task(OfflineDownloadTask(row.odr_id, row.repo_id, row.path, row.url, row.owner))
def start(self):
# Check and restore all the interrupted tasks.
task_list = self.db_oper.get_offline_download_tasks_by_status(OfflineDownloadStatus.WAITING)
for row in task_list:
self.db_oper.set_record_status(row.odr_id, OfflineDownloadStatus.DOWNLOADING)
self.thread_pool.put_task(OfflineDownloadTask(row.odr_id, row.repo_id, row.path, row.url, row.owner))
......
先定义了两个函数,一个 restore 用于解决前面说到的,seafevents 意外退出的情况。另外一个就是正式的扫描任务,我们计划每 5 秒执行一次 start() 函数。
构造函数里面有个比较有意思的设计,跟 Virus Scan 不太相同。这里我直接使用了 Virus Scan 系统中提供的 ThreadPool 类,但是与 Virus Scan 不同的是,我是直接在 Worker 的构造函数中就把线程池创建出来,然后在 start 的时候直接往线程池里添加新任务。而 Virus Scan 则是每次执行都创建一次新的线程池,因为 Virus Scan 本身设置的扫描时间是 1 小时,所以这点开销不算什么,一直开着线程池反而浪费资源。但是我这个 task 运行频率很高,因此线程池一直开着收益更高。
主执行函数在这就不放出来了,具体的步骤:
- 从队列中获取任务信息;
- 创建临时文件夹;
- 调用 Aria2 接口,将文件下载到临时文件夹中;
- 调用 seafile_API,将临时文件夹中的文件存储到 seafileFS 中;
- 删除临时文件和临时文件夹。
这里为什么不是直接创建临时文件?因为我是调用外部工具进行的下载,所以无法用比较方便的方法获得下载好后的文件名。那么,通过临时文件夹,我们在下载时保留它原本的文件名,下载完成后通过 os.listdir 函数获取下载到的文件名称。
这里在编写的时候出现过一个小问题,直接 remove 文件夹、unlink 文件夹都不行。那么只能先删除里面的所有内容,然后再删除文件夹本身:
if tdir is not None and len(tdir) > 0:
file_list = os.listdir(tdir)
for item in file_list:
os.unlink(os.path.join(tdir, item))
os.rmdir(tdir)
注册 Worker 和启动类
我们在 seafevents 的 tasks 文件夹中创建名为 offline_downloader.py 的文件,并模仿 Virus Scan 功能,在里面建立一个 Worker 启动类和一个计时类。
class OfflineDownloader(object):
def __init__(self, config_file):
self.settings = Settings(config_file)
self.downloader = OfflineDownload(self.settings)
def is_enabled(self):
return self.settings.is_enabled()
def start(self):
logging.info("Start offline downloader, refresh interval = 5 sec")
logging.info("Restoring interrupted download tasks...")
self.downloader.restore()
OfflineDownloadTimer(self.downloader, self.settings).start()
class OfflineDownloadTimer(Thread):
def __init__(self, downloader, settings):
Thread.__init__(self)
self.settings = settings
self.finished = Event()
self.downloader = downloader
def run(self):
while not self.finished.is_set():
self.finished.wait(5)
if not self.finished.is_set():
self.downloader.start()
def cancel(self):
self.finished.set()
这里也是与 Virus Scan 不同,我在启动线程的 start 方法中先调用一次 restore() 方法,将上一次未完成的任务放入队列中,然后再启动 Timer。Timer 周期性运行 Worker 的 start 方法,周期性扫描数据库中新增的任务。
然后在 app.py 中,模仿其他的任务把启动器注册一下。
其实还有不少细节的地方啊,其实这一部分是我已经完成了一个初版以后才来写的总结性文本,所以缺失了很多细节,只写了我认为比较关键的部分。
写 Seahub 的路由和 View
这里我在 seahub/api2/endpoints/offline_download.py 里面写了一个 View Class,分别用 get 和 put 两种方法把请求 Task 列表和新增任务的接口分开。在 urls.py 里面定义如下:
## offline download
url(r'^api/v2.2/offline-download/tasks$', OfflineDownloadTasks.as_view(), name='api-v2.2-offline-download-tasks'),
url(r'^api/v2.2/offline-download/add$', OfflineDownloadTasks.as_view(), name='api-v2.2-offline-download-add'),
v2.2 版本 API(诶嘿
这里我更改了原先的想法,在 addTask 里面我直接使用了数据库更新的命令。原来我想的是,从 seahub 发送一条 event 到后端,然后完全由 seafevents 来处理数据库。但是我做好 prototype 以后发现,首先就是 5 秒的扫描周期,用户点击了添加按钮以后,数据库很长一段时间(好几秒内)没有任何数据更新,这样用户界面上也没办法显示东西。另外如果 seafevents 服务没有启动的话,用户的离线下载任务甚至无法被推送上去,用户体验非常差。
而且当时设计的时候,其实是 seafevents 收到了 event 信号以后,立即在数据库创建一条新纪录,显然这是脱了裤子放屁。因此,我最终还是选择把 event 信号给去掉了。
前端
啊,前端,真的搞得我有些迷茫。
更正前一天的内容
还记得上一期咱们搞了好多层那个,onOfflineDownload 函数?没错,我今天终于把它去掉了。笑死,也就白忙活一晚上。完全是被旁边的文件上传按钮给忽悠瘸了,人家文件上传是按下按钮以后就要传数据了,所以需要层级高一些,而我这个离线下载不过就是打开个对话框,根本没必要把一个简简单单的对话框控制函数传到那么多层以外。
所以后来直接变成了这样:
class DirOperationToolbar extends React.Component {
constructor(props) {
super(props);
this.state = {
fileType: '.md',
isCreateFileDialogShow: false,
isCreateFolderDialogShow: false,
isOfflineDownloadDialogShow: false,
isUploadMenuShow: false,
isCreateMenuShow: false,
isShareDialogShow: false,
operationMenuStyle: '',
isMobileOpMenuOpen: false
};
}
然后直接做了一个新的 OfflineDownloadDialog 扔在了 DirOperationToolbar 的 render() 方法里。。。让 DirOperationToolbar 直接去处理对话框的打开和关闭问题。
思路的话,还是再说一下吧,在 state 里面存储一个 isOfflineDownloadDialogShow 变量,然后在 render 函数里面判断这个变量是否为 true,如果是 true,就把 Dialog 这个 Component 放在一个 Modal 中,一起 render 出来。然后给 Dialog 的关闭按钮添加一个响应事件,点击后 isOfflineDownloadDialogShow 变为 false,它就能开关自如啦。
做一个简单的界面
总之现在就做了一个非常非常简单的界面,没有本地化,只显示原始 URL 和任务的状态:
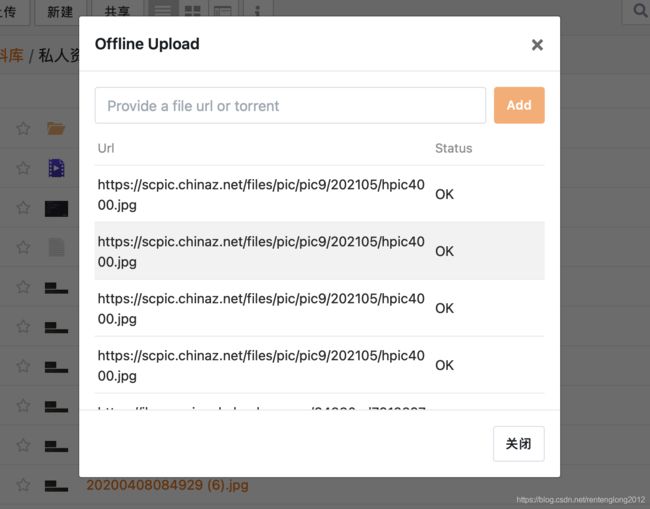
Seafile_API 问题
前面说过,因为 seafile_API 被做成了一个 lib 发布到了 npm 的网络中,因此我们不方便直接对 seafile_API 的 JS 代码进行修改。不过,我们可以直接模仿 seafile_API 里面的实现:
// We cannot modify the seafile-API lib, but we can add a raw method.
function getOfflineDownloadTask() {
let url = seafileAPI.server + '/api/v2.2/offline-download/tasks';
return seafileAPI.req.get(url, {
});
}
function addOfflineDownloadTask(repoId, path, targetUrl) {
let url = seafileAPI.server + '/api/v2.2/offline-download/add';
return seafileAPI.req.put(url, {
repo_id: repoId, path: path, url: targetUrl });
}
嘿嘿,这样也是比较方便的,就是后面如果加的多了就不好管理了。
定时刷新列表数据
然后就遇到一个问题,任务的状态变化是非常快的,总不能让用户在一个 React App 里面刷新页面来看下载任务是否完成吧?
因此,我设计了一个定时触发器,每隔 3 秒自动重新获取一次 task 列表,并重新加载到用户界面上。
为了保证性能,防止多余的请求(毕竟如果每个人都一直保持 3 秒获取一次的话服务器会吃不消的),我做了一个小优化:在 componentDidMount 的时候启动计时器,并在 componentWillUnmount 的时候中止计时器。
componentDidMount() {
this.refreshList();
this.setState({
refreshTimer: setInterval(this.refreshList.bind(this), 3000) });
}
componentWillUnmount() {
clearInterval(this.state.refreshTimer);
this.setState({
refreshTimer: null });
}
啊,这里还有一个当时出现的问题。就是 setInterval 在默认状态下,callback 函数中的 this 指针指代的对象不再是 OfflineDownloadDialog 类了,而是其他东西,总之那样的话就没办法调用 setState 方法了。通过添加 .bind(this),可以确保 callback 函数中 this 就是 OfflineDownloadDialog 类的对象。
上传完成后刷新文件列表
还有一个比较细节的问题,就是完成了离线下载之后,用户没办法立即在文件列表中看到那个文件,这样用户又要刷新页面,体验很差。
经过逐级向上查找,我发现在 frontend/src/pages/lib-content-view/lib-content-view.js 所定义的 Component 中,又一个 loadDirentList 函数很不起眼,但是它就是用来加载文件夹内容的。(诶嘿,主要还是前面做项目的经验告诉我 dirent 就是文件夹里的东西)
那么,我们可以这样,把 loadDirentList 作为一个 prop 逐级传到我们的 OfflineDownloadDialog 上,这样当我们的上传完成后,直接调用这个 loadDirentList,刷新一次文件夹内容,就好了。
逐级传递的写法就不再赘述了,前面我可是写够了。
不过这里又有一个奇妙的问题,如何才能判断上传完成呢?我们只保留了一个获取 taskList 的接口,并且在代码实现中也没有做到跟踪某一个或某几个任务,似乎很难判断时机。
我想到的解决方案是:在 state 中存储一个任务状态为 OK 的个数,然后每次获取到新列表的时候,都重新数一下新获得的列表中有多少个任务状态为 OK 的。如果发现与上次记录的不同,那就更新一次列表。这样,就可以把更新开销降低很多。
getOfflineDownloadTask().then((res) => {
this.setState({
taskList: res.data.data,
errMessage: ''
});
let ok_cnt = 0;
for (let i = 0; i < this.state.taskList.length; i++) {
let is_ok = this.state.taskList[i].status === 3;
if (is_ok) ok_cnt++;
}
if (ok_cnt !== this.state.ent_ok_num) this.props.refreshDirent();
this.setState({
ent_ok_num: ok_cnt });
})
好了,现在基本上功能已经很棒了,赶紧把代码保存一下,后面进行界面的美观和本地化工作。