一般的组合:
假设有如下数据集,我们需要进行一些多表操作:
df1 = DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']},
index=[0, 1, 2, 3])
df2 = DataFrame({'A': ['A4', 'A5', 'A6', 'A7'],
'B': ['B4', 'B5', 'B6', 'B7'],
'C': ['C4', 'C5', 'C6', 'C7'],
'D': ['D4', 'D5', 'D6', 'D7']},
index=[4, 5, 6, 7])
df3 = DataFrame({'A': ['A8', 'A9', 'A10', 'A11'],
'B': ['B8', 'B9', 'B10', 'B11'],
'C': ['C8', 'C9', 'C10', 'C11'],
'D': ['D8', 'D9', 'D10', 'D11']},
index=[8, 9, 10, 11])

1.png

2.png

3.png
1.concat
concat参数有axis、join、join_axes、keys、levels、names等等

4.png
类似组合还有append
df1.append(df2)
区别是append后面一次只能跟一个

5.png
可以看到因为索引位的关系,会出现missing value的问题,需要注意。
更经常出现需要多表组合的情况:
实际工作中数据量非常庞大,会采取分割的方式储存表。如金融业务中,一张表是个人信息如年龄、性别、婚否、学历等等,另一张是业务信息如银行流水、逾期记录等等。这些表虽然角度不同,但都是以用户ID为核心,因此我们在分析过程中需要以ID为主将两张表组合起来。
假设有以下两表,key1,key2表示以它们为主健:

6.png
1.需要以key1为主键组合两张表
默认参数:merge(left,right,how='inner',on=None,right_on=None,left_on=None,left_index=False,right_index=False,sort=True,suffixes=('_x','_y'),copy=True)
pd.merge(aa,bb,on = "key1")

7.png
2.以key1,key2同时作为主键,以左表为主表
pd.merge(aa,bb,on = ['key1','key2'],how = 'left')

8.png
2.工作中更多情况下两张表的key1,key2其实并不一样
bb1 = bb.rename(columns ={"key1":"key1_new","key2":"key2_new"})
此时如需要以key1,key2为主键组合,则需对应另张表的名字

9.png
3.索引位与列名组合
将aa表中key1,key2作为索引位:

10.png
以aa表中索引位与bb1表中key1_new,key2_new 为主,结合两张表:
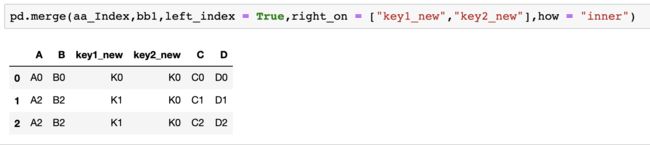
11.png