
从身份证说起
不知道大家有没关注过,我们的身份证号其实是有一定规律的,里面包含着我们的信息,在我们国家的每个人都拥有这么一个独一无二的识别码。
这一天小郭老师遇到了一个难题,同事不小心把一批货物的编号导入到了存储身份证号码信息的数据库里了。老板把分离的任务交给了小郭老师,可把小郭老师难坏了。这时有人给小郭老师出了个主意,可以用正则表达式鸭!
小郭老师通过搜索引擎,复制了一段别人写好的表达式完美把身份证号码从数据库里分离了出来,让我们来看看这一段表达式究竟是长什么样:
var reg = /(^\d{15}$)|(^\d{18}$)|(^\d{17}(X|x)$)/;
虽然问题解决了,但是小郭老师秉承教书育人的一贯标准,不能知其然不知其所以然,决定向别人请教一定要把这段天书般的文字究竟是怎么发挥作用的梳理清楚。
第一条正则表达式
让我们来看看这段表达式吧,首先我们在编写正则之前需要先确定的是我们最终想要的数据形式是什么或者我们想使用的场景有什么合法的数据形式。
我们国家的身份证号码有15位和18位两种,15位的身份证号全为数字,18位的身份证前17位全为数字,最后一位可以为数字或者标识位X。
正则表达式是用"/""/"包裹的一系列字符串,其存在意义是为了描述匹配应该遵循的规则。首先我们来实现身份证为15位时全为数字的需求。
正则表达式中使用 \d 来匹配一个数字,使用 {n}来确定需要匹配多少次,使用 ^ 匹配一行的开头,使用 $ 匹配一行的末尾。由此我们能写出符合15位数字的正则表达式:
//匹配15位数字
var reg = /^\d{15}$/;
但是当我们像文中一样需要匹配多种条件要怎么办呢?这时候我们要联想到了在 if 判断时可以通过 “ | ” 进行或操作,当然这种语法也沿袭到了正则表达式中,由此便有:
//匹配15位或18位数字
var reg = /(^\d{15}$)|(^\d{18}$)/;
写到这里我们需要的表达式也已有了雏形了,那么最后一个需要匹配最后一位为数字或X的需求要怎么分析呢?我们可以拆成两个问题来看,第一个是前17位都是数字,第二个问题是第18位为数字或X,其中第18位为数字的情况已经包含在前一种情况中了,所以我们只需要写出第18位为字符X的情况即可:
var reg = /(^\d{15}$)|(^\d{18}$)|(^\d{17}(X|x))/;
这里我们就得到了验证身份证号码的正则表达式啦,下面我们来验证一下我们的正则表达式是否正确,在JS中使用判断正则主要使用 RegExp.test() 来验证:
//以下身份证信息是我乱打的
var reg = /(^\d{15}$)|(^\d{18}$)|(^\d{17}(X|x))/;
var val1 = 110102197810272321;
var val2 = 54012354321651621 + 'X';
var val3 = 123456789123456;
var val4 = 54012341231541297 + 'x';
var val5 = 1110011111111111111 //17位
var val6 = 13154646161561651 + 'a' //末尾不为x
console.log(reg.test(val1)); //true
console.log(reg.test(val2)); //true
console.log(reg.test(val3)); //true
console.log(reg.test(val4)); //true
console.log(reg.test(val5)); //false
console.log(reg.test(val6)); //false
从检验结果来看,我们所写的这一正则表达式是可以完成我们的需求的,小郭老师对此感到十分满意,心情大好,准备喝杯奶茶奖励一下自己。
全面认识正则表达式
小郭老师来到了一圈圈奶茶店,发现店门口此时正人头涌涌,凑近一看,原来是店门口贴出了一个告示,该店现在正在举办正则擂台赛,采用打擂台的方式进行比拼,连续一周占据擂主位置即可获赠一个月份的无限奶茶。刚经过双十一血拼的小郭老师顿时来了精神,盘算着今天先不喝了,回去好好学一下正则表达式,等赢下免费奶茶后一次性喝个够!
俗话说得好,说出来永远都比做好要容易,小郭老师在学习的过程中发现了一个整理得超详细的表格:
传送门:https://www.jb51.net/tools/regexsc.htm
别看上面这张表格那么吓人,下面归类之后你会觉得正则在你心中突然变得无比清晰,就像使用九九乘法表一样张口即来。
元字符
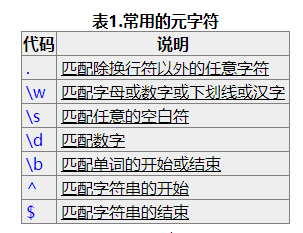
什么叫元字符呢?我们在上面的例子里已经用过几个了,其实就是表示匹配特定类型的代号,这些代号想要熟悉别无他法,只能通过不断的背诵和练习。
限定字符

限定符的作用其实就是字面意思,限定我们的匹配次数。
反义字符
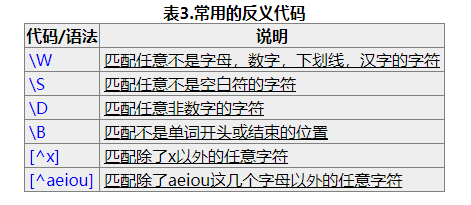
很多时候我们从正面无法很好的描述问题,这个时候可以考虑一下从反面进行描述的方法。
分组语法
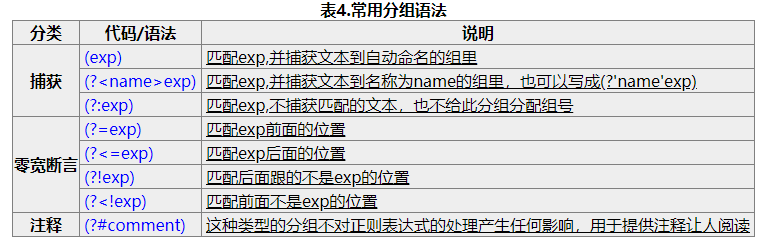
分组语法常用于需要获取有着重复匹配的结果项的情况。
贪婪与懒惰
在正则的表达中有贪婪匹配和懒惰匹配的区分,其实贪婪指的是会尽可能多的匹配,懒惰则指只会进行制定次数或者尽可能少的匹配,正如字面意思所表达的那样。

懒惰限定符在很多我们想要获取特定字符段的场景中需要用到。
修饰符
常用的修饰符主要有三个,修饰符与上面提到的用法不同之处在于修饰符用于加在字面量的后面,若使用构造函数构造的方法应于第二个参数位置传入。下面我们来看看主要是哪几个修饰符:
- g(global) 用于执行一个全局匹配
- i (ingore case) 用于执行不区分大小写的匹配
- m (multiple lines)执行多行匹配
修饰符用法例子: /^[0-9]+/g
用于在全局从头开始匹配数字
其他语法
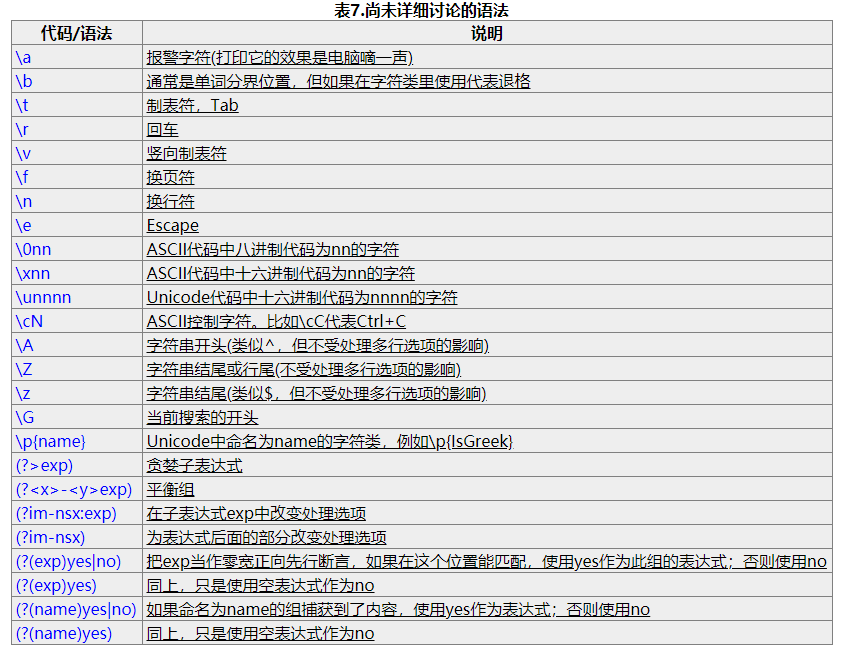
这些语法其实我也没怎么用过....
再来一个小栗子
小郭老师学到这,仿佛身体已经被掏空了,各种雨里雾里的都是字符。终于把文档给过了一遍小郭老师急切的想要拿个小问题来练练手,这个时候想起来可以利用正则的特性来作为自己整理文件的工具。
那就写一个小正则,匹配出所有后缀名是 “.jpg” 的文件吧!
var reg = /.+(.jpg)$/g;
var val = "hello.jpg";
console.log(reg.test(val)); //true
自从就大功告成啦!
结语
说实话正则表达式不是一个好理解的知识点,主要是因为完成一个问题的方法是多种多样的。太过简洁的符号反而让熟悉程度不够的读者会产生阅读障碍,在查找资料的过程中,我发现了一个整理得很好的思维导图,这里转载过来也算是留下多一份记录吧:
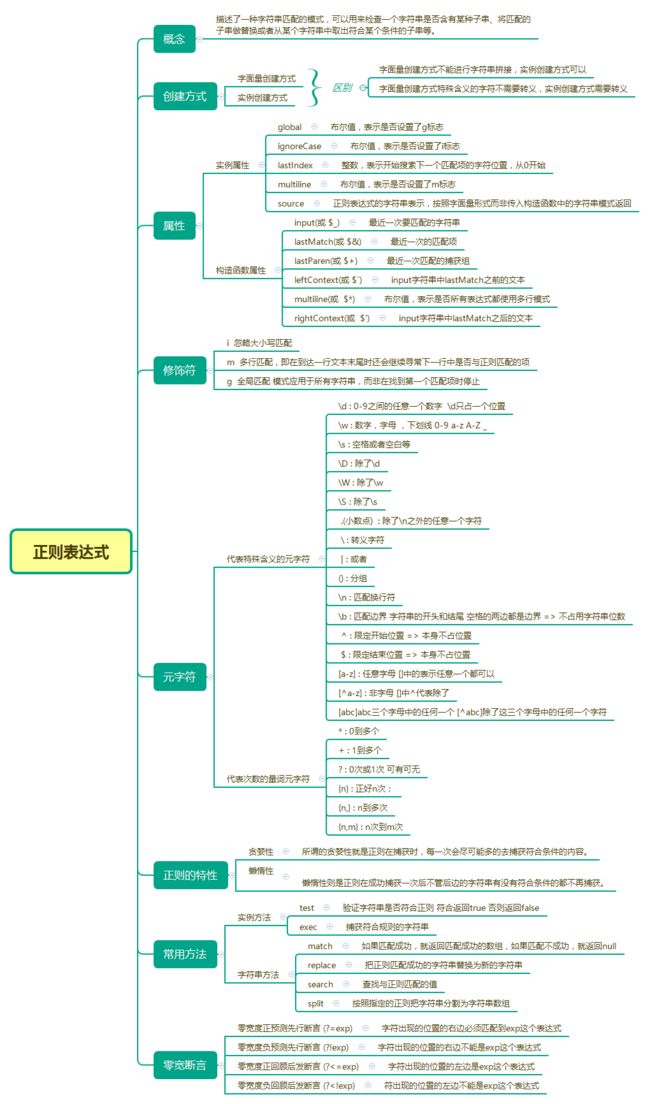
学习的过程中从来就没有容易二字,温故而知新是乃王道。细细算来,这已经是我第五次学习正则表达式了,但因为眼界问题始终是没有解决过比较难的正则问题。希望在不断学习过程中能不断补足自己的短板。
参考资料:
- https://www.jb51.net/tools/zhengze.html
- https://www.cnblogs.com/chenmeng0818/p/6370819.html
Clancy Lin
2019.1.10
I can be whatever I want to be