前段时间做聊天消息的解析,涉及到要在群消息中查找@的人,需要把@后面的用户昵称解析出来,首先想到的当然就是用正则来实现了,于是一顿操作外加度娘加持。
public static List findRegex(String p,String s){
Pattern pattern = Pattern.compile(p);
Matcher matcher = pattern.matcher(s);
List list=new ArrayList<>();
while (matcher.find()) {
list.add(matcher.group());
}
return list;
}
//引用的地方调用
//@开头,空格结尾
List list=findRegex("(?<=\\@)(\\S+)(?=\\s)",msg);
这里面涉及知识点:
- Java的两个类
Pattern,Matcher
Pattern.compile生成Pattern
find()匹配
group()得到匹配结果
2.正则表达式。
零宽断言用于匹配@来头及空格结尾
具体的用法含义请查看下面详细内容
1.Java中的正则表达式类
java.util.regex 包主要包括以下三个类:
Pattern 类:
pattern 对象是一个正则表达式的编译表示。
构造
Pattern 类没有公共构造方法。要创建一个 Pattern 对象,你必须首先调用其公共静态编译方法,它返回一个 Pattern 对象。该方法接受一个正则表达式作为它的第一个参数。
Pattern p=Pattern.compile("\\S+");
p.pattern();//返回Pattern.complile(String regex)的regex参数 \S+
compile( )方法还有一个版本,它需要一个控制正则表达式的匹配行为的参数:
Pattern Pattern.compile(String regex, int flag)
flag的取值范围如下:
| 编译标志 | 效果 |
|---|---|
| Pattern.CANON_EQ | 当且仅当两个字符的"正规分解(canonical decomposition)"都完全相同的情况下,才认定匹配。比如用了这个标志之后,表达式"a/u030A"会匹配"?"。默认情况下,不考虑"规范相等性(canonical equivalence)"。 |
| Pattern.CASE_INSENSITIVE(?i) | 默认情况下,大小写不敏感的匹配只适用于US-ASCII字符集。这个标志能让表达式忽略大小写进行匹配。要想对Unicode字符进行大小不明感的匹配,只要将UNICODE_CASE与这个标志合起来就行了。 |
| Pattern.COMMENTS(?x) | 在这种模式下,匹配时会忽略(正则表达式里的)空格字符(注:不是指表达式里的"//s",而是指表达式里的空格,tab,回车之类)。注释从#开始,一直到这行结束。可以通过嵌入式的标志来启用Unix行模式。 |
| Pattern.DOTALL(?s) | 在这种模式下,表达式'.'可以匹配任意字符,包括表示一行的结束符。默认情况下,表达式'.'不匹配行的结束符。 |
| Pattern.MULTILINE (?m) | 在这种模式下,'^'和''也匹配字符串的结束。默认情况下,这两个表达式仅仅匹配字符串的开始和结束。 |
| Pattern.UNICODE_CASE (?u) | 在这个模式下,如果你还启用了CASE_INSENSITIVE标志,那么它会对Unicode字符进行大小写不明感的匹配。默认情况下,大小写不明感的匹配只适用于US-ASCII字符集。 |
| Pattern.UNIX_LINES (?d) | 在这个模式下,只有'/n'才被认作一行的中止,并且与'.','^',以及'$'进行匹配。 |
在这些标志里面,Pattern.CASE_INSENSITIVE,Pattern.MULTILINE,以及Pattern.COMMENTS是最有用的(其中Pattern.COMMENTS还能帮我们把思路理清楚,并且/或者做文档)。注意,你可以用在表达式里插记号的方式来启用绝大多数的模式。这些记号就在上面那张表的各个标志的下面。可以用"OR" ('|')运算符把这些标志合使用
方法
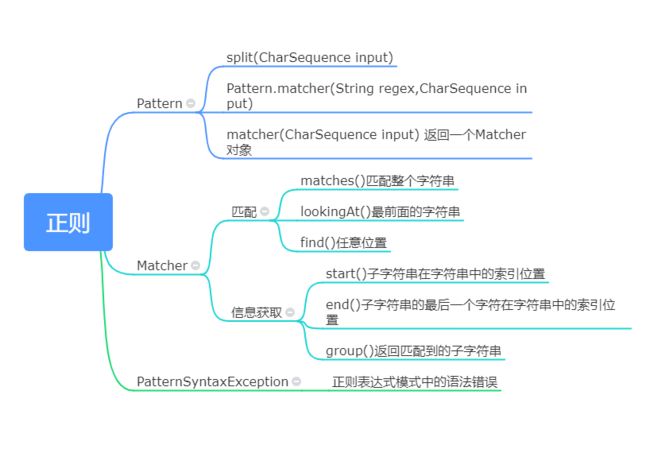
1.Pattern.split(CharSequence input)
Pattern有一个split(CharSequence input)方法,用于分隔字符串,并返回一个String[],我猜String.split(String regex)就是通过Pattern.split(CharSequence input)来实现的.
Pattern p=Pattern.compile(",");
String[] str=p.split("abc,444,666,ddd,rr");
if(str!=null){
for(int i=0;i输出为
第0个值为abc
第1个值为444
第2个值为666
第3个值为ddd
第4个值为rr
2.Pattern.matcher(String regex,CharSequence input)是一个静态方法,用于快速匹配字符串,该方法适合用于只匹配一次,且匹配全部字符串.
Java代码示例:
Pattern.matches("\\d+","9527");//返回true
Pattern.matches("\\d+","9527aa");//返回false,需要匹配到所有字符串才能返回true,这里aa不能匹配到
Pattern.matches("\\d+","22bb23");//返回false,需要匹配到所有字符串才能返回true,这里bb不能匹配到
3.Pattern.matcher(CharSequence input)
说了这么多,终于轮到Matcher类登场了,Pattern.matcher(CharSequence input)返回一个Matcher对象.
Matcher类的构造方法也是私有的,不能随意创建,只能通过Pattern.matcher(CharSequence input)方法得到该类的实例.
Pattern类只能做一些简单的匹配操作,要想得到更强更便捷的正则匹配操作,那就需要将Pattern与Matcher一起合作.Matcher类提供了对正则表达式的分组支持,以及对正则表达式的多次匹配支持.
Pattern p=Pattern.compile("\\d+");
Matcher m=p.matcher("22ssd23");
m.pattern();//返回p 也就是返回该Matcher对象是由哪个Pattern对象的创建的
Matcher 类:
Matcher对象是对输入字符串进行解释和匹配操作的引擎。与Pattern 类一样,Matcher 也没有公共构造方法。你需要调用 Pattern 对象的 matcher 方法来获得一个 Matcher 对象。
匹配操作
Matcher类提供三个匹配操作方法,三个方法均返回boolean类型,当匹配到时返回true,没匹配到则返回false
-
matches()对整个字符串进行匹配,只有整个字符串都匹配了才返回true
Pattern p=Pattern.compile("\\d+");
Matcher m=p.matcher("22bb23");
m.matches();//返回false,因为bb不能被\d+匹配,导致整个字符串匹配未成功.
Matcher m2=p.matcher("9527");
m2.matches();//返回true,因为\d+匹配到了整个字符串
我们现在回头看一下Pattern.matcher(String regex,CharSequence input),它与下面这段代码等价
Pattern.compile(regex).matcher(input).matches()
-
lookingAt()对前面的字符串进行匹配,只有匹配到的字符串在最前面才返回true
Pattern p=Pattern.compile("\\d+");
Matcher m=p.matcher("22bb23");
m.lookingAt();//返回true,因为\d+匹配到了前面的22
Matcher m2=p.matcher("aa9527");
m2.lookingAt();//返回false,因为\d+不能匹配前面的aa
-
find()对字符串进行匹配,匹配到的字符串可以在任何位置.
Pattern p=Pattern.compile("\\d+");
Matcher m=p.matcher("22bb23");
m.find();//返回true
Matcher m2=p.matcher("aa9527");
m2.find();//返回true
Matcher m3=p.matcher("aa9527bb");
m3.find();//返回true
Matcher m4=p.matcher("aabb");
m4.find();//返回false
索引位置
当使用matches(),lookingAt(),find()执行匹配操作后,利用以上三个方法得到更详细的信息。
-
start()返回匹配到的子字符串在字符串中的索引位置 -
end()返回匹配到的子字符串的最后一个字符在字符串中的索引位置 -
group()返回匹配到的子字符串
Pattern p=Pattern.compile("\\d+");
Matcher m=p.matcher("aaa9527bb");
m.find();//匹配9527
m.start();//返回3
m.end();//返回7,返回的是9527后的索引号
m.group();//返回9527
Mathcer m2=m.matcher("9527bb");
m.lookingAt(); //匹配9527
m.start(); //返回0,由于lookingAt()只能匹配前面的字符串,所以当使用lookingAt()匹配时,start()方法总是返回0
m.end(); //返回4
m.group(); //返回匹配到的结果,即9527
Matcher m3=m.matcher("9527bb");
m.matches(); //匹配整个字符串
m.start(); //返回0,原因相信大家也清楚了
m.end(); //返回6,原因相信大家也清楚了,因为matches()需要匹配所有字符串
m.group(); //返回9527bb
start(),end(),group()均有一个重载方法它们是start(int i),end(int i),group(int i)专用于分组操作,与参数为0时返回的结果相同,Mathcer类还有一个groupCount()用于返回有多少组.
Pattern p=Pattern.compile("([a-z]+)(\\d+)");
Matcher m=p.matcher("aaa9527bb");
m.find(); //匹配aaa9527
m.groupCount(); //返回2,因为有2组
m.start(0);//与m.start()相同,返回0
m.end(0);//与m.end()相同,返回7
m.start(1); //返回0 返回第一组匹配到的子字符串在字符串中的索引号
m.start(2); //返回3
m.end(1); //返回3 返回第一组匹配到的子字符串的最后一个字符在字符串中的索引位置.
m.end(2); //返回7
m.group(1); //返回aaa,返回第一组匹配到的子字符串
m.group(2); //返回9527,返回第二组匹配到的子字符串
PatternSyntaxException
PatternSyntaxException 是一个非强制异常类,它表示一个正则表达式模式中的语法错误。
总结正则:
2、正则表达式语法
元字符
| 代码 | 说明 |
|---|---|
| . | 匹配除换行符以外的任意字符 |
| \w | 匹配字母或数字或下划线或汉字 |
| \s | 匹配任意的空白符 |
| \d | 匹配数字 |
| ^ | 匹配字符串的开始 |
| $ | 匹配字符串的结束 |
| \b | 匹配字符串的结束 |
重复
| 代码/语法 | 说明 |
|---|---|
| * | 重复零次或更多次 |
| + | 重复一次或更多次 |
| ? | 重复零次或一次 |
| {n} | 重复n次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复n到m次 |
字符类
想查找数字,字母或数字,空白是很简单的,因为已经有了对应这些字符集合的元字符,但是如果你想匹配没有预定义元字符的字符集合(比如元音字母a,e,i,o,u),应该怎么办?
很简单,你只需要在方括号里列出它们就行了,像[aeiou]就匹配任何一个英文元音字母,[.?!]匹配标点符号(.或?或!)。
我们也可以轻松地指定一个字符范围,像[0-9]代表的含意与\d就是完全一致的:一位数字;同理[a-z0-9A-Z_]也完全等同于\w(如果只考虑英文的话)。
分枝条件
用|把不同的规则分别表达。
如:0\d{2}-\d{8}|0\d{3}-\d{7}这个表达式能匹配两种以连字号分隔的电话号码:一种是三位区号,8位本地号(如010-12345678),一种是4位区号,7位本地号(0376-2233445)。
反义
| 代码/语法 | 说明 |
|---|---|
| \W | 匹配任意不是字母,数字,下划线,汉字的字符 |
| \S | 匹配任意不是空白符的字符 |
| \D | 匹配任意非数字的字符 |
| \B | 匹配不是单词开头或结束的位置 |
| [^x] | 匹配除了x以外的任意字符 |
| [^aeiou] | 匹配除了aeiou这几个字母以外的任意字符 |
分组
重复单个字符直接在字符后面加上限定符就行了,但如果想要重复多个字符又该怎么办?你可以用小括号来指定子表达式(也叫做分组),然后你就可以指定这个子表达式的重复次数了,你也可以对子表达式进行其它一些操作。
使用小括号指定一个子表达式后,匹配这个子表达式的文本(也就是此分组捕获的内容)可以在表达式或其它程序中作进一步的处理。捕获组可以通过从左到右计算其开括号来编号。例如,在表达式 ((A)(B(C))) 中,存在四个这样的组:
- ((A)(B(C)))
- (A)
- (B(C))
- (C)
组零始终代表整个表达式。
之所以这样命名捕获组是因为在匹配中,保存了与这些组匹配的输入序列的每个子序列。捕获的子序列稍后可以通过 Back 引用在表达式中使用,也可以在匹配操作完成后从匹配器获取。
与组关联的捕获输入始终是与组最近匹配的子序列。如果由于量化的缘故再次计算了组,则在第二次计算失败时将保留其以前捕获的值(如果有的话)例如,将字符串 "aba" 与表达式 (a(b)?)+ 相匹配,会将第二组设置为 "b"。在每个匹配的开头,所有捕获的输入都会被丢弃。
以 (?) 开头的组是纯的非捕获 组,它不捕获文本,也不针对组合计进行计数。
后向引用用于重复搜索前面某个分组匹配的文本。例如:
\b(\w+)\b\s+\1\b可以用来匹配重复的单词,像go go, 或者kitty kitty。
也可以自己指定子表达式的组名。要指定一个子表达式的组名,请使用这样的语法:(?(或者把尖括号换成'也行:(?'Word'\w+)),这样就把\w+的组名指定为Word了。要反向引用这个分组捕获的内容,你可以使用\k,所以上一个例子也可以写成这样:\b(?。
零宽断言
(?=exp)也叫零宽度正预测先行断言,它断言被匹配的字符串以表达式exp结尾但除了结尾以外的部分。比如\b\w+(?=ing\b),匹配以ing结尾的单词的前面部分(除了ing以外的部分),如查找I'm singing while you're dancing.时,它会匹配sing和danc。
(?<=exp)也叫零宽度正回顾后发断言,它断言自身出现的位置的前面能匹配表达式exp。比如(?<=\bre)\w+\b会匹配以re开头的单词的后半部分(除了re以外的部分),例如在查找reading a book时,它匹配ading。
| 代码/语法 | 说明 |
|---|---|
| (?=exp) | 匹配exp前面的位置 |
| (?<=exp) | 匹配exp后面的位置 |
| (?!exp) | 匹配后面跟的不是exp的位置 |
| (? | 匹配前面不是exp的位置 |
注释
小括号的另一种用途是通过语法(?#comment)来包含注释。例如:2[0-4]\d(?#200-249)|25[0-5](?#250-255)|[01]?\d \d?(?#0-199)。
贪婪与懒惰
| 语法 | 说明 |
|---|---|
| *? | 重复任意次,但尽可能少重复 |
| +? | 重复1次或更多次,但尽可能少重复 |
| ?? | 重复0次或1次,但尽可能少重复 |
| {n,m}? | 重复n到m次,但尽可能少重复 |
| {n,}? | 重复n次以上,但尽可能少重复 |
当正则表达式中包含能接受重复的限定符时,通常的行为是(在使整个表达式能得到匹配的前提下)匹配尽可能多的字符。考虑这个表达式:a.b,它将会匹配最长的以a开始,以b结束的字符串。如果用它来搜索aabab的话,它会匹配整个字符串aabab。这被称为贪婪匹配。
有时,我们更需要懒惰匹配,也就是匹配尽可能少的字符。前面给出的限定符都可以被转化为懒惰匹配模式,只要在它后面加上一个问号?。这样.?就意味着匹配任意数量的重复,但是在能使整个匹配成功的前提下使用最少的重复。现在看看懒惰版的例子吧:
a.*?b匹配最短的,以a开始,以b结束的字符串。如果把它应用于aabab的话,它会匹配aab(第一到第三个字符)和ab(第四到第五个字符)。
POSIX 字符类(仅 US-ASCII)
| 语法 | 说明 | |
|---|---|---|
| \p{Lower} | 小写字母字符:[a-z] | |
| \p{Upper} | 大写字母字符:[A-Z] | |
| \p{ASCII} | 所有 ASCII:[\x00-\x7F] | |
| \p{Alpha} | 字母字符:[\p{Lower}\p{Upper}] | |
| \p{Digit} | 十进制数字:[0-9] | |
| \p{Alnum} | 字母数字字符:[\p{Alpha}\p{Digit}] | |
| \p{Punct} | 标点符号:!"#$%&'()*+,-./:;<=>?@[]^_{ | }~ |
| \p{Graph} | 可见字符:[\p{Alnum}\p{Punct}] | |
| \p{Print} | 可打印字符:[\p{Graph}\x20] | |
| \p{Blank} | 空格或制表符:[ \t] | |
| \p{Cntrl} | 控制字符:[\x00-\x1F\x7F] | |
| \p{XDigit} | 十六进制数字:[0-9a-fA-F] | |
| \p{Space} | 空白字符:[ \t\n\x0B\f\r] |
引用
| 语法 | 说明 |
|---|---|
| \ | Nothing,但是引用以下字符 |
| \Q | Nothing,但是引用所有字符,直到 \E |
| \E | Nothing,但是结束从 \Q 开始的引用 |
如:\Q\w+\E表示字符串\w+而不是正则中的单词字符:[a-zA-Z_0-9]。
其他
| 语法 | 说明 |
|---|---|
| \xhh | 十六进制值为0xhh的字符 |
| \uhhhh | 十六进制表示为0xhhhh的Unicode字符 |
| \t | 制表符Tab |
| \n | 换行符 |
| \r | 回车 |
| \f | 换页 |
| \e | 转义(Escape) |
处理选项
上面介绍了几个选项如忽略大小写,处理多行等,这些选项能用来改变处理正则表达式的方式。下面是Java中常用的正则表达式选项:
| 名称 | 说明 |
|---|---|
| CASE_INSENSITIVE | 匹配时区分大小写 |
| MULTILINE | 更改^和 |
| DOTALL | 在 dotall 模式中,表达式 . 可以匹配任何字符,包括行结束符。默认情况下,此表达式不匹配行结束符。 |
| UNICODE_CASE | 指定此标志后,由 CASE_INSENSITIVE 标志启用时,不区分大小写的匹配将以符合 Unicode Standard 的方式完成。默认情况下,不区分大小写的匹配假定仅匹配 US-ASCII 字符集中的字符。通过嵌入式标志表达式 (?u) 也可以启用 Unicode 感知的大小写折叠。指定此标志可能对性能产生影响。 |
| CANON_EQ | 启用规范等价。指定此标志后,当且仅当其完整规范分解匹配时,两个字符才可视为匹配。例如,当指定此标志时,表达式 "a\u030A" 将与字符串 "\u00E5" 匹配。默认情况下,匹配不考虑采用规范等价。不存在可以启用规范等价的嵌入式标志字符。指定此标志可能对性能产生影响。 |
| UNIX_LINES | 启用 Unix 行模式。在此模式中,.、^ 和 $ 的行为中仅识别 '\n' 行结束符。通过嵌入式标志表达式 (?d) 也可以启用 Unix 行模式。 |
| LITERAL | 指定此标志后,指定模式的输入字符串就会作为字面值字符序列来对待。输入序列中的元字符或转义序列不具有任何特殊意义。标志 CASE_INSENSITIVE 和 UNICODE_CASE 在与此标志一起使用时将对匹配产生影响。其他标志都变得多余了。不存在可以启用字面值解析的嵌入式标志字符。 |
| UNICODE_CHARACTER_CLASS | |
| COMMENTS | 模式中允许空白和注释。此模式将忽略空白和在结束行之前以 # 开头的嵌入式注释。通过嵌入式标志表达式 (?x) 也可以启用注释模式。 |
参照YunSoul 舒山