云原生事件驱动弹性转码方案解析
背景
在容器技术普及之前,事件驱动在数据库领域中被广泛使用。这个概念模型很简单:每当添加、更改或删除数据时,会触发一个事件来执行各种操作。事件驱动的方式可以在非常短的时间内,完成后续动作的执行。事件驱动架构的核心是对系统上的各种事件做出反应并执行相应的动作。弹性伸缩已成为几乎所有云平台中不可或缺的组成部分。Kubernetes中,容器水平伸缩器HPA(Horizontal Pod Autoscaler)是最常用的应用弹性方案。容器水平伸缩的核心是基于资源利用率与预设的阈值水位之间的关系,来确认伸缩的计划。容器水平伸缩的方式具有使用简单、资源指标丰富等特点,但是它对于需要即时弹性的场景,尤其是对基于事件源进行离线作业支撑不足。ACK提供了ack-keda来提供事件驱动弹性能力,事件驱动弹性适用于音视频离线转码、事件驱动作业、流式数据处理等场景。
事件驱动弹性原理
ACK通过增强版本的ack-keda来提供事件驱动弹性能力,下图是ack-keda的基本原理。
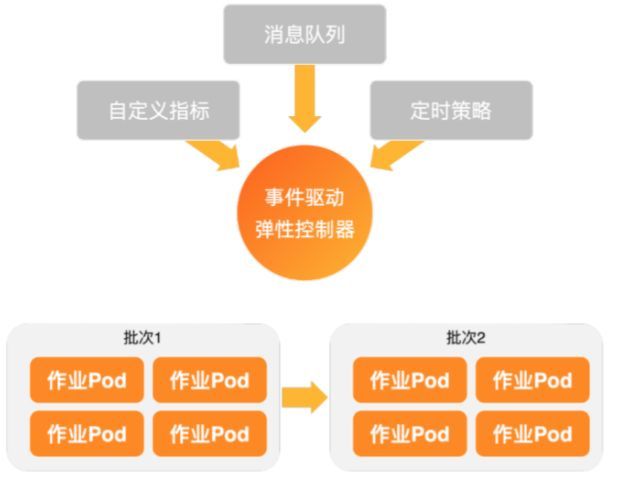
ack-keda会从事件源中进行数据的周期性消费。当消息出现堆积,即可秒级触发一个批次的离线任务伸缩。下一个周期到来时,会异步进行下一个批次的作业伸缩。ack-keda具有以下特性:
- 丰富的事件源
ack-keda内置支持Kafka、MySQL、PostgreSQL、Rabbitmq、Redis等多种内置数据源。同时支持从客户自定义的事件源获取事件并进行Job或者pod维度的弹性缩放。 - 离线任务的并发控制
对于大规模的离线作业而言,底层管控的稳定性会面临比较大的挑战,需要提供资源、额度、API请求的整体控制。ack-keda提供了单批次、总批次的任务并发控 制,保障系统的稳定性。 - 结束任务后自动清理元数据&&支持任务回溯
大规模离线作业执行完毕后,会留存大量的元数据信息。元数据信息的堆积会造成APIServer的稳定性下降,造成集群的性能下降、稳定性不足,甚至可能影响其 他的业务。ack-keda会在任务执行结束后自动清理元数据,降低元数据的量级。同时,ack-keda也支持保留一些执行失败的Job,便于回溯,定位原因。
事件驱动弹性转码案例
在本案例中,我们准备一个简单的转码作业,当有一个新任务到来的时候会向mongoDB插入一条类似下面的数据{"type":"mp4","state":"waiting","createTimeStamp":"1610332940","fileName":"World and peace","endTimeStamp":"","uuid":"1fae72ff-3239-42f5-af97-04711d8007e8"},此时,容器服务的事件驱动控制器会从数据库中查询到状态为"state":"waiting"的作业,弹出与任务数目匹配的Job Pod来承载转码作业,完成转码业务并将数据中的state字段从之前的waiting修改成finished。同时Job完成后,自动清理,降低元数据对APIServer带来的压力,极大的减轻开发者的负担。
1.安装事件驱动弹性控制器 - ack-keda
- 登录阿里云容器服务kubernetes控制台,点击左侧边栏的应用市场,搜索ack-keda
- 选择对应集群,点击部署,部署到该集群
- 选择左侧边栏的工作负载,选择无状态服务,选择kube-system 命名空间,确认ack-keda部署成功
2.部署基于mongoDB事件源驱动弹性示例
1.部署mongoDB
- 创建mongoDB.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: mongodb
spec:
replicas: 1
selector:
matchLabels:
name: mongodb
template:
metadata:
labels:
name: mongodb
spec:
containers:
- name: mongodb
image: mongo:4.2.1
imagePullPolicy: IfNotPresent
ports:
- containerPort: 27017
name: mongodb
protocol: TCP
---
kind: Service
apiVersion: v1
metadata:
name: mongodb-svc
spec:
type: ClusterIP
ports:
- name: mongodb
port: 27017
targetPort: 27017
protocol: TCP
selector:
name: mongodb- 执行kubectl apply -f mongoDB.yaml -n mongodb部署到集群。
2.mongoDB新建User
// 新建用户
kubectl exec -n mongodb mongodb-xxxxx -- mongo --eval 'db.createUser({ user:"test_user",pwd:"test_password",roles:[{ role:"readWrite", db: "test"}]})'
// 登陆认证
kubectl exec -n mongodb mongodb-xxxxx -- mongo --eval 'db.auth("test_user","test_password")'
// 新建collection
kubectl exec -n mongodb mongodb-xxxxx -- mongo --eval 'db.createCollection("test_collection")'3.部署TriggerAuthentication和ScaledJob
- 创建TriggerAuthentication
TriggerAuthentication是用来登录mongoDB查询数据时认证使用,TriggerAuthentication中的secretTargetRef字段会将指定Secret中的数据读取到ack-keda中,完成对Mongo的登录认证。
apiVersion: keda.sh/v1alpha1
kind: TriggerAuthentication
metadata:
name: mongodb-trigger
spec:
secretTargetRef:
- parameter: connectionString
name: mongodb-secret
key: connect
---
apiVersion: v1
kind: Secret
metadata:
name: mongodb-secret
type: Opaque
data:
connect: bW9uZ29kYjovL3Rlc3RfdXNlcjp0ZXN0X3Bhc3N3b3JkQG1vbmdvZGItc3ZjLm1vbmdvZGIuc3ZjLmNsdXN0ZXIubG9jYWw6MjcwMTcvdGVzdA==- 执行kubectl apply -f auth.yaml -n mongodb-test到集群。
- 创建ScaledJob
ScaledJob主要用来配置Job模板以及指定查询的数据库及查询表达式等,这里我们配置的是从test数据库中的test_collection中,查询满足{"type":"mp4","state":"waiting"}的待转码数据。
apiVersion: keda.sh/v1alpha1
kind: ScaledJob
metadata:
name: mongodb-job
spec:
jobTargetRef:
// Job模板配置
template:
spec:
containers:
- name: mongo-update
image: registry.cn-hangzhou.aliyuncs.com/carsnow/mongo-update:v6
args:
- --connectStr=mongodb://test_user:[email protected]:27017/test
- --dataBase=test
- --collection=test_collection
imagePullPolicy: IfNotPresent
restartPolicy: Never
backoffLimit: 1
pollingInterval: 15
maxReplicaCount: 5
successfulJobsHistoryLimit: 0
failedJobsHistoryLimit: 10
triggers:
- type: mongodb
metadata:
dbName: test //要查询的数据库
collection: test_collection //要查询的collection
query: '{"type":"mp4","state":"waiting"}' //会对查询转码类型为mp4且状态是waiting的数据拉起job进行处理
queryValue: "1"
authenticationRef:
name: mongodb-trigger- 执行kubectl apply -f scaledJob.yaml -n mongodb-test到集群。
4.插入待转码业务数据
// 插入5条待转码数据
kubectl exec -n mongodb mongodb-xxxxx -- mongo --eval 'db.test_collection.insert([
{"type":"mp4","state":"waiting","createTimeStamp":"1610352740","fileName":"My Love","endTimeStamp":"","uuid":"1gae72ff-3239-42f5-af97-04711d8007e8"},
{"type":"mp4","state":"waiting","createTimeStamp":"1610350740","fileName":"Harker","endTimeStamp":"","uuid":"1gae72ff-3239-42f5-af97-04711d8007e8"},
{"type":"mp4","state":"waiting","createTimeStamp":"1610152940","fileName":"The World","endTimeStamp":"","uuid":"1gae72ff-3239-42f5-af97-04711d87767e8"},
{"type":"mp4","state":"waiting","createTimeStamp":"1610390740","fileName":"Mother","endTimeStamp":"","uuid":"1gae72ff-3239-42f5-af97-04799d8007e8"},
{"type":"mp4","state":"waiting","createTimeStamp":"1610344740","fileName":"Jagger","endTimeStamp":"","uuid":"1gae72ff-3239-42f5-af97-04711d80099e8"},
])'5.查看Job动态
// watch job
watch -n 1 kubectl get job -n mongodb-test
可以看到成功扩展出5个Job。此时再登录数据库,观察转码业务状态,可以看到数据状态已经从waiting变成了finished。
写在最后
本文介绍的转码业务实际也是我们在日常场景经常会遇到的一个需求,看得出来ack-keda的使用,相对来说还是比较容易的,而且实际效果也能满足我们日常的需求。我们最近在keda社区的基础上,新增了对于mongoDB事件源的支持,并已PR到社区,至此,内置的事件源已经能够满足我们绝大部分事件驱动场景。
原文链接
本文为阿里云原创内容,未经允许不得转载。