ZAB协议详解
ZooKeeper使用了一种称为ZooKeeper Atomic Broadcast(ZAB,ZooKeeper原子消息广播协议)的协议作为其数据一致性的核心算法,ZAB协议是为分布式协调服务ZooKeeper专门设计的一种能保证操作顺序性的、基于主备模式的原子广播协议
1、ZAB中的三个角色
ZAB支持3种成员身份(领导者、跟随者、观察者)
- 领导者(Leader):作为主节点,在同一时间集群只会有一个领导者。所有的写请求都必须在领导者节点上执行
- 跟随者(Follower):作为备份节点,集群可以有多个跟随者,它们会响应领导者的心跳,并参与领导者选举和提案提交的投票。跟随者可以直接处理并响应来自客户端的读请求,但对于写请求,跟随者需要将它转发给领导者处理
- 观察者(Observer):作为备份节点,类似跟随者,但是观察者不参与领导者选举和提案提交的投票
ZAB中定义了4种成员状态
- LOOKING:选举状态,该状态下的节点认为当前集群中没有领导者,会发起领导者选举
- FOLLOWING:跟随者状态,意味着当前节点是跟随者
- LEADING:领导者状态,意味着当前节点是领导者
- OBSERVING:观察者状态,意味着当前节点
为什么多了一种成员状态?是因为ZAB支持领导者选举,在选举过程中,涉及了一个过渡状态,也就是选举状态
2、ZAB如何实现操作的顺序性的
假设节点A为主节点,节点B、C为备份节点;有两个指令X、Y,指令X在指令Y之前执行
在ZAB中,写操作必须在主节点A上执行。如果客户端访问的节点时备份节点B,它会将写请求转发给主节点

当主节点接收到写请求后,它会基于写请求中的指令X、Y,来创建一个提案(Proposal),并使用一个唯一的ID来标识这个提案。这个唯一的ID是指事务标识符(Transaction ID,也就是zxid)

上图中,X、Y对应的事务标识符分别为<1,1>和<1,2>,这两个标识符是什么含义呢?
事务标识符是64位的long型变量,有任期编号epoch和计数器counter两部分组成,格式为
- 任期编号:创建提案时领导者的任期编号,当新领导者当选时,任期编号递增,计数器被设置为零。前领导者的任期编号为1,那么新领导者对应的任期编号为2
- 计数器:具体标识提案的整数,每次领导者创建新的提案时,计数器将递增。比如,前一个提案对应的计数器值为1,那么新的提案对应的计数器值将为2
事务标识符必须按照顺序、唯一标识一个提案,也就是说,事务标识符必须是唯一的、递增的
在创建完提案之后,主节点会基于TCP协议(TCP协议本身支持按序确认),并按照顺序将提案广播到其他节点。这样就能保证先发送的消息,会先被收到,保证了消息接收的顺序性(X一定在Y之前到达节点B、C)

然后,当主节点收到指定提案的大多数的确认响应后,该提案处于提交状态(Committed),主节点会通知备份节点提交该提案

主节点提交提案也是有顺序的,会根据事务标识符大小,按照顺序提交提案,如果前一个提案未提交,此时主节点是不会提交后一个提案的。也就是说,指令X一定会在指令Y之前提交
最后,主节点返回执行成功的响应给节点B,节点B在转发给客户端
为了提升读并发能力,Zookeeper提供的是最终一致性,也就是读操作可以在任何节点上执行,客户端会读到旧数据:

如果客户端必须要读到最新数据,可以在执行读操作前,先执行sync命令,这样客户端就能读到最新数据了
小结:

- Leader从客户端收到一个事务请求(如果是集群中其他机器接收到客户端的事务请求,会直接转发给Leader服务器)
- Leader服务器生成一个对应的事务Proposal,并为这个事务生成一个全局递增的唯一的ZXID(通过其ZXID来进行排序保证顺序性)
- Leader将这个事务发送给所有的Follower节点
- Follower节点将收到的事务请求加入到历史队列(Leader会为每个Follower分配一个单独的队列先进先出,顺序保证消息的因果关系)中,并发送ack给Leader
- 当Leader收到超过半数Follower的ack消息,Leader会广播一个commit消息
- 当Follower收到commit请求时,会判断该事务的ZXID是不是比历史队列中的任何事务的ZXID都小,如果是则提交,如果不是则等待比它更小的事务的commit
3、如何选举主节点
假设投票信息的格式是
- proposedLeader:节点提议的领导者的集群ID,也就是集群配置(比如myid配置文件)时指定的ID
- proposedEpoch:节点提议的领导者的任期编号
- proposedLastZxid:节点提议的领导者的事务标识符最大值(也就是最新提案的事务标识符)
- node:投票的节点,比如节点B
假设一个ZooKeeper集群,由节点A、B、C组成,其中节点A是领导者,节点B、C是跟随者。假设B和C的epoch分别是1和1、lastZxid分别是101和102、集群ID分别是2和3。如果节点A宕机了,会如何选举?
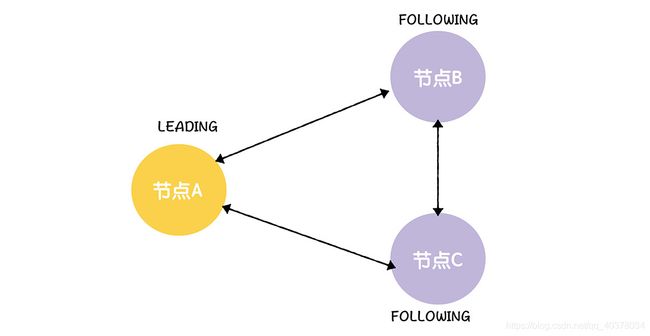
首先,当跟随者检测到连接领导者节点的读操作等待超时了,跟随者会变更节点状态,将自己的节点状态变更成LOOKING,然后发起领导者选举

接着,每个节点会创建一张选票,这张选票是投给自己的,也就是说,节点B、C都推荐自己为领导者,并创建选票<2,1,101,B>和<3,1,102,C>,然后各自将选票发送给集群中所有节点,也就是说,B发送给B、C,C也发送给B、C
一般而言,节点会先接收到自己发送给自己的选票,也就是说B会先收到来自B的选票,C会先收到来自C的选票

集群的各节点收到选票后,为了选举出数据最完整的节点,对于每一张接收到选票,节点都需要进行领导者PK,也就将选票提议的领导者和自己提议的领导者进行比较,找出更适合作为领导者的节点,约定的规则如下:
- 优先检查任期编号(Epoch),任期编号大的节点作为领导者
- 如果任期编号相同,比较事务标识符的最大值,值大的节点作为领导者
- 如果事务标识符的最大值相同,比较集群ID,集群ID大的节点作为领导者
如果选票提议的领导者,比自己提议的领导者,更适合作为领导者,那么节点将调整选票内容,推荐选票提议的领导者作为领导者
当节点B、C接收到选票后,因为选票提议的领导者与自己提议的领导者相同,所以,领导者PK的结果,是不需要调整选票的信息,那么节点B、C,正常接收和保存选票就可以了

接着节点B、C分别接收到来自对方的选票,比如B接收到来自C的选票,C接收到来自B的选票:

对C而言,它提议的领导者是C,而选票<2,1,101,B>提议的领导者是B,因为节点C的任期编号与节点B相同,但节点C的事务标识符的最大值比节点B的大,那么,按照约定的原则,相比节点B,节点C更适合作为领导者,也就是说,节点C不需要调整选票信息,正常接收和保存选票就可以了
但对于节点B而言,它提议的领导者是B,选票<3,1,102,C>提议的领导者是C,因为节点C的任期编号与节点B相同,但节点C的事务标识符的最大值比节点B的大,那么,按照约定的规则,相比节点B,节点C应该作为领导者,所以,节点B除了接收和保存选票信息,还会更新自己的选票为<3,1,102,B>,也就是推荐C作为领导者,并将选票重新发送给节点B、C

接着,当节点B、C接收到来自节点B,新的选票时,因为这张选票<3,1,102,B>提议的领导者,与他们提议的领导者是一样的,都是节点C,所以,他们正常接收和存储这张选票,就可以

最后,因为此时节点B、C提议的领导者节点C赢得了大多数选票(2张选票),那么,节点B、C将根据选票结果,变更节点状态,并退出选举。比如,因为当选的领导者是节点C,那么节点B将变更状态为FOLLOWING,并退出选举,而节点C将变更状态为LEADING,并退出选举

参考:
「分布式一致性协议」从 2PC、3PC、Paxos 到 ZAB
15 | ZAB协议:如何实现操作的顺序性?
加餐 | ZAB协议(一):主节点崩溃了,怎么办?