
前文回顾
建议前面文章没看过的同学先看下前面的文章:
「老司机带你玩转面试(1):缓存中间件 Redis 基础知识以及数据持久化」
「老司机带你玩转面试(2):Redis 过期策略以及缓存雪崩、击穿、穿透」
「老司机带你玩转面试(3):Redis 高可用之主从模式」
「老司机带你玩转面试(4):Redis 高可用之哨兵模式」
「老司机带你玩转面试(5):Redis 集群模式 Redis Cluster」
并发竞争
这个问题产生的根源是并发写,本身 Redis 是不会产生并发问题的,看过前面文章的同学应该知道, Redis 的线程模型是单线程的,所有的操作指令都在文件事件处理器的队列中,这个绝对是按照先进先出的原则进行操作的,那么并发竞争的问题是如何产生的?
例如我们现在有三个客户端 A , B , C ,需要按序像 Redis 中写入或者更新数据 A -> B -> C ,就像下面这样:
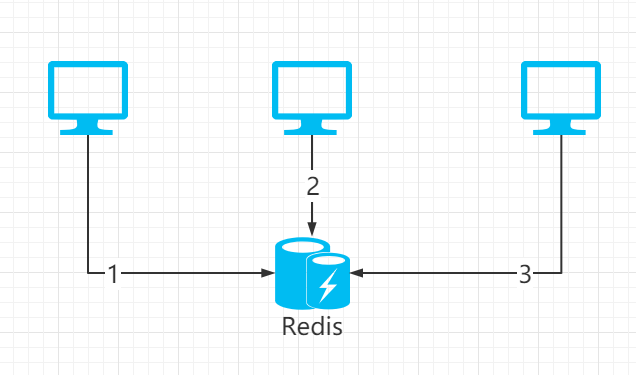
但是现在突然 A 的网络抖动了一下,导致 A 并不是第一个去 Redis 中写数据的,整个流程的操作顺序变成了 B -> C -> A ,这样数据不就错了么。
这就好比你在网上买东西,加购物车,下订单,支付订单的顺序变掉了,你先下单,再支付,再加购物车,这个流程根本走不下去的好吧。这种事情发生在线上的系统上的时候,是非常恐怖的。
这种情况解决起来其实也很简单,加一个分布式锁就可以了,比如这样:

我们可以基于 Zookeeper 实现一个全局分布式锁,确保同一时间,只能有一个系统实例在操作某个 key ,别人都不允许读和写。
你要写入缓存的数据,都是从 DB 里查出来的,都得写入 DB 中,写入 DB 中的时候必须保存一个时间戳,从 DB 查出来的时候,时间戳也查出来。
每次要写之前,先判断一下当前这个 Value 的时间戳是否比缓存里的 Value 的时间戳要新。如果是的话,那么可以写,否则,就不能用旧的数据覆盖新的数据。
双写一致性
只要使用缓存,就可能会涉及到缓存与数据库的双写,只要是双写,就一定会有数据一致性的问题。
首先先介绍下经典的 Redis + BD 的读写模式:
- 读的时候,先读缓存,缓存没有的话,就读数据库,然后取出数据后放入缓存,同时返回响应。
- 更新的时候,先更新数据库,然后再删除缓存。
为什么是删除缓存,而不是更新缓存?
这里还会有另外一个问题:为什么是删除缓存,而不是更新缓存?
原因很简单,很多时候,在复杂点的缓存场景,缓存不单单是数据库中直接取出来的值。
比如可能更新了某个表的一个字段,然后其对应的缓存,是需要查询另外两个表的数据并进行运算,才能计算出缓存最新的值的。
另外更新缓存的代价有时候是很高的。是不是说,每次修改数据库的时候,都一定要将其对应的缓存更新一份?也许有的场景是这样,但是对于比较复杂的缓存数据计算的场景,就不是这样了。如果你频繁修改一个缓存涉及的多个表,缓存也频繁更新。但是问题在于,这个缓存到底会不会被频繁访问到?
举个栗子,一个缓存涉及的表的字段,在 1 分钟内就修改了 20 次,或者是 100 次,那么缓存更新 20 次、100 次;但是这个缓存在 1 分钟内只被读取了 1 次,有大量的冷数据。实际上,如果你只是删除缓存的话,那么在 1 分钟内,这个缓存不过就重新计算一次而已,开销大幅度降低。用到缓存才去算缓存。
其实删除缓存,而不是更新缓存,就是一个 lazy 计算的思想,不要每次都重新做复杂的计算,不管它会不会用到,而是让它到需要被使用的时候再重新计算。像 mybatis,hibernate,都有懒加载思想。查询一个部门,部门带了一个员工的 list,没有必要说每次查询部门,都把里面的 1000 个员工的数据也同时查出来啊。80% 的情况,查这个部门,就只是要访问这个部门的信息就可以了。先查部门,同时要访问里面的员工,那么这个时候只有在你要访问里面的员工的时候,才会去数据库里面查询 1000 个员工。
严格要求 「缓存 + 数据库」 必须保持一致
这种模式应该就是我们大多数人现在使用的模式,在不是严格要求 「缓存 + 数据库」 必须保持一致的时候,这样做是可以的。
那为什么说上面这种方案在严格要求 「缓存 + 数据库」 的场景下不行呢?
因为这个问题只有在对一个数据在并发的进行读写的时候,才可能会出现这种问题。
就是如果说并发量没那么高的话,比如 1s 才一个对缓存的读写请求,那么大概率是不会出现缓存 「缓存 + 数据库」 不一致的情况。
但是问题是,如果每天的是上亿的流量,每秒并发读是几万,每秒只要有数据更新的请求,就可能会出现上述的 「缓存 + 数据库」 不一致的情况。
那么这种问题是不是就没有解决方案,当然有,但是如果不是严格要求 「缓存 + 数据库」 必须保持一致性的场景,最好不要使用这个方案。
我们可以让读请求和写请求串行化,把所有的读写请求都串行到一个队列里面去。
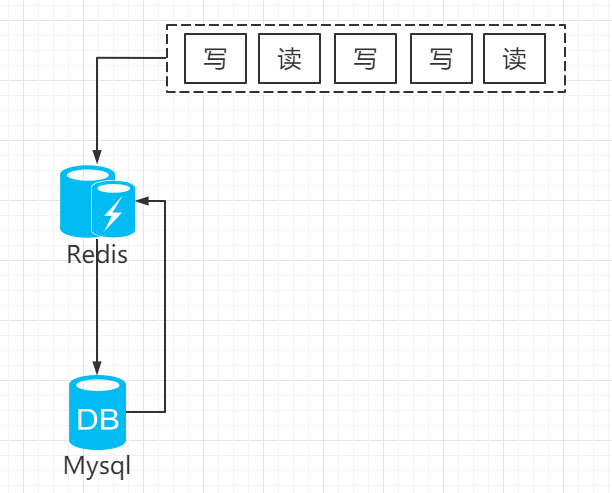
串行化可以保证一定不会出现不一致的情况,但是它也会导致系统的吞吐量大幅度降低,用比正常情况下多几倍的机器去支撑线上的一个请求。
把所有的操作都放到队列里面,顺序肯定不会乱,但是并发高了,这队列很容易阻塞,反而会成为整个系统的瓶颈。
参考
https://github.com/doocs/advanced-java/blob/master/docs/high-concurrency/redis-consistence.md