常见JAVA面试题总结<2020 java面试必备>(三)JVM
JVM
JVM内存结构模型
(1)类加载器:负责加载class文件
(2)线程共享内存(堆内存):静态变量、常量、类信息、运行时常量池、实例变量(new出来的对象)
(3)线程私有内存(栈内存):虚拟机栈、本地方法栈,PC程序寄存器
(4)总结:栈管运行、堆管存储
Java栈内存
(1)什么是栈
1.1)栈也叫栈内存,主管Java程序的运行
1.2)是在线程创建时创建,它的生命周期是跟随线程的生命期的,对于栈来说不存在垃圾回收问题
(2)栈存储什么
2.1)本地变量:输入参数和输出参数以及方法内变量
2.2)栈操作:记录出栈、入栈的操作
2.3)栈帧数据:包括类文件、方法等
(3)栈运行原理
3.1)栈中的数据都是以栈帧的格式存在,栈帧是一个内存区块,一个有关方法和运行期数据的数据集
3.2)当一个方法A被调用时就产生一个栈帧F1,并被压入到栈中
3.3)A方法又调用B方法,于是产生栈帧F2,也被压入到栈中
3.4)执行完毕后,先弹出F2,再弹出F1,栈运行是遵循 “先进后出”/ “后进先出”的原则
(4)栈异常
4.1)java.lang.StackOverflowError
4.2)在java中函数栈调用层级过多,导致当前线程的栈满了,就会出现此异常,比如:方法调用如出现死循环这种情况
内存溢出和内存泄漏的区别
内存溢出:指程序在申请内存时,没有足够的内存空间供其使用,出现OOM
内存泄漏:指分配出去的内存不再使用,但是无法回收
JVM垃圾回收的时候如何确定垃圾?是否知道什么是GC Roots?
什么是垃圾
内存中已经不再被使用到的空间就是垃圾
JVM垃圾回收的时候如何确定垃圾
如果程序中无法再引用到该对象,这个状态称为不可达,那么该对象就可以作为回收对象被垃圾回收器回收
所谓不可达就是从根对象(GC roots)开始无法引用到该对象,该对象就是不可达的
Java中可以作为GC Roots的对象
虚拟机栈中引用的对象
方法区静态成员引用的对象
方法区常量引用对象
本地方法栈中Native方法引用的对象
你说你做过JVM调优和参数配置,请问如何查看JVM系统默认值
了解JVM参数的类型
Boolean类型
公式:-XX: +或者-某个属性 (+表示开启 -表示关闭)
例子:开启打印GC收集日志 -XX:+PrintGCDetails
KV设值类型
公式:-XX: 属性key=属性值value
例子:设置MetaspaceSize空间大小 -XX:MetaspaceSize=128m
了解JVM常用的相关命令
jps -l

查看当前正在运行的Java程序
jinfo -flags 进程号
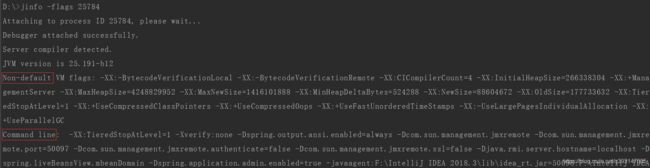
查看某个Java程序当前正在使用的所有JVM参数
Non-default:表示系统根据当前机器性能自动设置的参数
Command line:表示人为添加的一些参数
jinfo -flag MetaspaceSize 进程号
查看某个Java程序,它的某个JVM参数是否开启,具体值是多少
java -XX:+PrintFlagsInitial 和 java -XX:+PrintFlagsFinal -version
![]()
PrintFlagsInitial :查看JVM配置的初始默认值,这个会根据系统的内存大小而变化
PrintFlagsFinal : 查看JVM修改过的配置初始参数,等号前面添加了 : 表示是修改过的值
java -XX:+PrintCommandLineFlags
运行时,将当前Java程序使用的JVM参数打印出来,可查看使用的是什么垃圾
怎么查看服务器Java默认的垃圾收集器是哪个

java -XX:+PrintCommandLineFlags -version
你平时工作用过的JVM常用基本配置参数有哪些?
-Xms
初始堆内存,默认为物理内存的 1/64
等价于 -XX:InitialHeapSize
-Xmx
最大堆内存,默认为物理内存的 1/4
等价于 -XX:MaxHeapSize
-Xss
设置线程栈大小,一般默认为512k ~ 1024k,Oracle官方文档中写到从 64位的Linux系统默认都设置为1024K
等价于 -XX:ThreadStackSize
-XX:MetaspaceSize
设置元空间大小,Java默认只设置了20M,如果需要可自行通过此参数调配
JDK8元空间和JDK7永久代最大区别在于:元空间并不在虚拟机中,而是使用本地内存,因此默认情况下,元空间的大小只受本地内存限制
-XX:+PrintGCDetails
设置打印GC日志
打印的GC日志内容

把GC日志打印存储到文件中
-Xloggc:/path/gc.log
GC日志内容解析
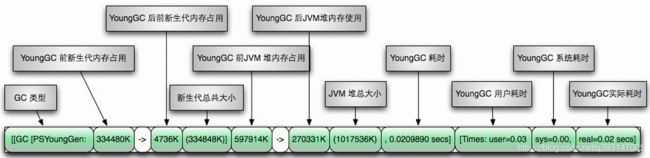
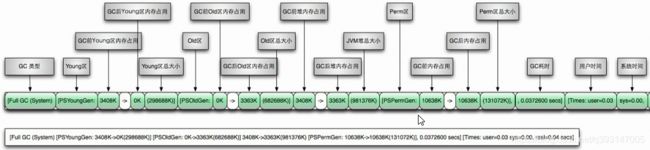
日志规律:[ 名称 ] [ GC前内存占用 ] -> GC后内存占用 [ 该区内存总大小 ]
年轻代GC 日志内容解析
老年代 Full GC 日志内容解析
-XX:SurvivorRatio
设置新生代中的占比,也就是 Eden 和 S0/S1 的比例,S0/S1相同
此值默认是 -XX:SurvivorRation=8,表示 Eden:S0:S1 = 8:1:1
-XX:NewRatio
设置老年代的占比,剩下的1给新生代
此值默认是2, -XX:NewRatio = 2 ,表示 新生代占1,老年代2,新生代占整个堆的 1/3
-XX:MaxTenuringThreshold
设置垃圾最大年龄,如果设置为0的话,则年轻代对象不再经过 Survivor 区,直接进入老年代。对于老年代比较多的应用,可以提高效率。
如果设置为一个较大的值,则年经代对象会在 Survivor 区进行多次复制,这样可以增加对象再年轻代的存活时间,也即增加在年轻代被回收的概率,降低 Full GC 概率。
此值只能设置为 0 到 15 之间,JDK8开始默认设置就是15,即对象在 From区 和 To 区来换复制15次,还是存活的就进入老年代
标准的JVM参数配置模板
-Xms128m
-Xmx4096
-Xss1204k
-XXMetaspaceSize=512m
-XX:+PrintCommandLineFlags
-XX:+PrintGCDetails
-XX:+UseParallelGC
Java垃圾回收工作原理
Java堆的内存结构

Java堆从GC的角度可以细分为:新生代(Eden区、From Survivor区 和 To Survivor区)和老年代
MinorGC的过程(复制 -> 清空 -> 互换)
新创建的对象首先会分配在 Eden 区,当Eden区满的时候会触发第一次GC,把存活的对象复制到 From 区,当 Eden 区再次触发GC的时候,会扫描 Eden区 和 From 区,把存活的对象复制到 To 区,如果有对象的年龄已经达到标准,则直接进入老年代,否则把这些对象的年龄 + 1
然后,会清空 Eden区 和 From 区中的对象,让 To 区和 From 区进行互换,原 To区成为下一次GC时的 From区,对象在 From和 To 区交换15次(MaxTenuringThreshold参数决定,CMS默认为6次,其它垃圾收集器为15次),最终如果还是存活,就进入老入代
如果分配的新对象比较大,Eden区放不下,Old区可以放下,对象会直接被分配到Old区
JVM为什么有1个Eden区和2个Survivor区
因为如果没有Survivor区那每触发一次Minor GC,就会把Eden区的对象复制到老年代,这样当老年代满了之后会触发Major Gc,比较耗时
如果只有1个Survivor区,那当Eden区满了之后,就会复制对象到Survivor区,容易产生内存碎片化。严重影响性能。所以使用2个Survivor区,让它们可以来回的交换,始终保持有一个空的Survivor区,可以避免内存碎片化。
什么是双亲委派模型
了解JVM类加载器
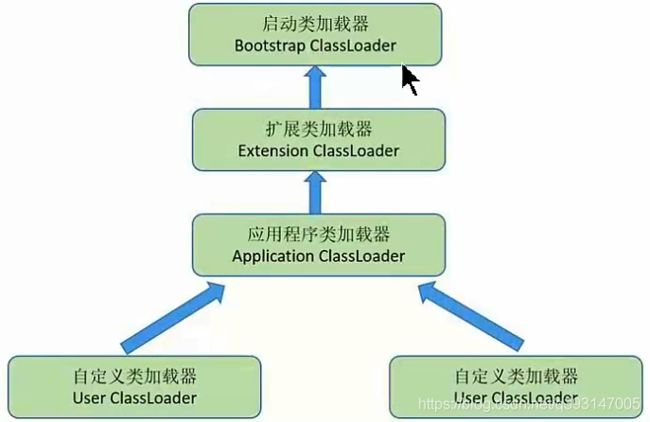
简单说 类加载器就是根据全限定名称将class文件加载到JVM内存,转为Class对象
双亲委派模型工作原理
2.1)如果一个类加载器收到类加载的请求,它首先不会自己去尝试加载这个类
2.2)而是把这个请求委派给父类加载器完成。每个类加载器都是如此
2.3)只有当父加载器在自己的搜索范围内找不到指定的类时(即ClassNotFoundException)
2.4)子加载器才会尝试自己去加载。
为什么需要双亲委派模型
如果黑客自定义一个跟java中原生的String一摸一样的类,该String类具有系统的String类一样的功能,只是在某个函数稍作修改。
比如equals函数,这个函数经常使用,如果在这这个函数中,黑客加入一些“病毒代码”。并且通过自定义类加载器加入到JVM中。
此时,如果没有双亲委派模型,那么JVM就可能误以为黑客自定义的String类是系统的String类,导致“病毒代码”被执行。
双亲委派模型如何解决此问题
(1)双亲委派模型,保证黑客自定义的String类永远都不会被加载进内存
(2)因为首先是最顶端的类加载器加载系统的String类,最终自定义的类加载器无法加载String类
Java对象的强引用,软引用,弱引用和虚引用
强引用
所谓强引用就是指,只要还有一个引用指向该对象,那就算发生了OOM,JVM也不会对该对象进行回收。
工作中平时使用的大部份对象都是属于强引用,因此强引用是造成Java内存泄露的主要原因之一
软引用 SoftReference
软引用是一种相对强化了一些的引用,需要用 `java.lang.ref.SoftReference` 类来实现,可以让对象豁免一些垃圾收集
如果内存空间足够大,垃圾回收期就不会回收它,如果内存空间不够了,就会回收这些对象。软引用通常用在对内存敏感的程序中,比如高速缓存就有用到软引用,内存够用的时候就保留,不够用就回收,Mybatis框架内部缓存功能就大部分使用了软引用
软引用应用场景
假如有一个应用需要读取大量的本地图片:
如果每次读取图片都从硬盘读取则会严重影响性能。
如果一次性全部加载到内存中有可能造成内存泄露。
此时使用软引用可以解决这个问题
设计思路:用一个HashMap来保存图片和相应图片路径关联的映射关系,在内存不足时,JVM会自动回收这些缓存图片对象所占用的空间,从而有效地避免OOM的问题
WeakHashMap<Integer, String> map = new WeakHashMap<>();
弱引用 WeakReference
弱引用需要用 `java.lang.ref.WeakReference` 类来实现,它比软引用的生存期更短,无论内存是否充足,只要当JVM进行垃圾回收时,都会被回收的对象就是弱引用的对象
虚引用 PhantomReference
虚引用与其他几种引用都不同,虚引用并不会决定对象的生命周期,如果一个对象仅持有虚引用,那么它就和没有任何引用一样,在任何时候都可能被垃圾回收器回收
它不能单独使用,也不能通过它访问对象,虚引用必须和引用队列(ReferenceQueue)联合使用,虚引用的主要作用是跟踪对象被垃圾回收的状态。仅仅是提供了一种确保对象被finalize以后,做某些事情的机制
引用队列 ReferenceQueue
对于 软引用、弱引用、虚引用三类对象,在被GC回收之前,它们都会被放到引用队列中保存下,当关联的引用队列中有数据的时候,意味着引用指向的堆内存中的对象被回收,JVM允许我们在对象被销毁后,做一些我们自己想做的事情,相当于一种通知机制,与 SpringAOP的前置通知类似。
谈谈常见的OOM异常有哪些
java.lang.StackOverFlowError
在java中函数栈调用层级过多,导致当前线程的栈满了,就会出现此异常,比如:方法调用如出现死循环这种情况
java.lang.OutOfMemoryError:
Java heap space
堆内存溢出异常
GC overhead limit exceeded
GC回收时间过长,超过98%的时间用来做GC但只回收了不到2%的堆内存,连续多次GC都只回收了不到2%的极端情况下才会抛出。
假设不抛出 GC overhead limit 错误会发生什么情况呢?
那就是GC清理的这么点内存很快会再次填满,迫使GC再次执行,这样就形成恶性循环,CPU使用率一直是100%,而GC却没有任何成果。
Direct buffer memory
参考下方的 --> 能说说你对堆外内存的理解吗?堆外内存的优势在哪里?
unable to create new native thread
导致原因
应用创建了太多线程,一个应用进程创建多个线程,超过系统承载极限。
服务器并不允许应用程序创建那么多线程,Linux系统默认允许单个进程可以创建的线程数是1024个,如果应用创建超过这个数量,就会报 java.lang.OutOfMemoryError:unable to create new native thread
解决办法:
想办法降低应用程序创建线程的数量,分析应用是否真的需要创建那么多线程,如果不是,改代码将线程数降到最低。
对于有的应用,确实需要创建多个线程,远超过linux系统默认的1024个线程的限制,可以通过修改linux 服务器配置,扩大linux默认限制。
Metaspace
Java8以后metaspace并不在虚拟机中,而是使用本地内存,因此默认情况下,metaspace的大小只受本地内存限制,metaspace存储以下信息
虚拟机加载的类信息
常量池
静态变量
编译后的代码
如果程序中加载了大量的以上内容,导致元空间被占满,就会出现此错误
能说说你对堆外内存的理解吗?堆外内存的优势在哪里?
什么是堆外内存
堆外内存指的就是JVM堆内存以外的内存,也就是OS本地内存
在写NIO Socket网络发送数据的程序经常使用ByteBuffer来读取或者写入数据,这是一种基于通道Channel与Buffer的I/O方式,可以通过 `ByteBuffer.allocateDirect(capability)` 方式来申请堆外内存,然后Java堆内有一个 DirectByteBuffer 对象会作为这块堆外内存的引用进行操作
堆外内存的优势在哪里
堆内的数据,要网络IO写出去,要先拷贝到堆外内存,再写入到socket里发送出去;如果直接数据分配在堆外内存,就不需要进行一次额外的拷贝,性能是比较高的
但如果不断分配堆外内存,堆内存很少使用,那么JVM就不需要执行GC,DirectByteBuffer对象们就不会被回收,这时候堆内存充足,但堆外内存可能已经使用光了,再次尝试分配堆外内存就会出现 OutOfMemoryError:Direct buffer memory 异常,那程序就直接崩溃了
GC垃圾回收算法、垃圾收集器你的了解吗
垃圾回收算法
复制算法(Copying)
Minor GC(年轻代 GC)主要就是复制算法(Copying),复制算法基本思想就是将内存分为两块,每次只用其中一块,当这一块内存用完,就将还存活的对象复制到另外一块上面去,复制算法不会产生内存碎片
缺点
耗内存、如果对象存活率高,则复制这一项工作所花费的时间就会成问题
标记清除算法(Mark-Sweep)
标记:从根集合开始扫描,对存活的对象进行标记
清除:扫描整个内存空间,将未标记的对象进行回收,使用free-list记录
缺点
效率较低,因为会进行两次扫描,会产生出内存碎片
这种方式清理出来的空间内存是不连续的,内存的布局会乱七八糟,JVM就会使用上面的free-list来维持内存的空闲列表,这又会是一种开销
标记压缩算法(Mark-Compact)
不直接对可回收对象进行清理,而是让所有可用的对象都向一端移动,然后直接清理掉边界以外的内存,这种算法解决了产生内存碎片的问题
但缺点是效率低,因为要标记所有存活对象,还要整理所有存活对象的引用地址
垃圾收集器
经典的7种垃圾收集器
串行收集器:Serial、Serial old
并行收集器:ParNew、Parallel、Parallel Old
并发收集器:CMS、G1
串行收集器
一个单线程的收集器,在进行垃圾收集时候,必须暂停其他所有的工作线程知道它收集结束。适合嵌入式程序
并行收集器
多线程的方式进行垃圾回收,在垃圾收集时,也会暂停其他所有的工作线程直到它收集结束
并行收集器其实就是串行收集器在新生代的多线程版本,最主是配合老年代的CMS GC工作,它是Java虚拟机运行在Server模式下新生代的默认垃圾收集器
并发收集器
用户线程和垃圾收集线程同时执行(不一定是并行,可能交替执行),不需要停顿用户线程,是一种响应时间优先的的垃圾收集器
适合应用在互联网站或者B/S系统的服务器上,这类应用尤其重视服务器的响应速度,希望系统停顿时间最短
垃圾收集器的组合
串行收集器组合:Serial(新生代) + Serial old(老年代)
并行收集器组合:Parallel(新生代) + Parallel Old(老年代)
并发收集器组合:ParNew(新生代) + CMS(老年代) + Serial Old(老年代)
整堆收集器:G1
ParNew 并行收集器
开启参数:-XX:+UseParNewGC
开启该参数后,使用组合为 ParNew(新生代)+ Serial old(老年代),在JDK1.8官方已经废弃
Parallel 并行收集器
开启参数:-XX:+UseParallelGC 或 -XX:+UseParallelOldGC(可互相激活)
开启该参数后,使用组合为 Parallel(新生代) + Parallel Old(老年代)
在JDK1.8默认就是该组合收集器
CMS 并发收集器
开启参数:-XX:+UseConcMarkSweepGC 开启该参数后会自动将 -XX:+UseParNewGC打开
开启该参数后,使用的组合为 ParNew(新生代) + CMS(老年代) + Serial Old(老年代)
Serial Old 将作为CMS出错的后备收集器
G1并发收集器
开启参数:-XX:+UseG1GC
JDK1.9开始无须设置,默认就是G1
实际工作中应该如何选择垃圾收集器
单CPU或小内存,单机程序
Serial(新生代) + Serial old(老年代)
多CPU,需要最大吞吐量,如后台计算型应用
Parallel(新生代) + Parallel Old(老年代)
多CPU,追求低停顿时间,需要快速响应如互联网应用
ParNew(新生代) + CMS(老年代) + Serial Old(老年代)
G1
CMS并发收集器(ConcMarkSweep)
什么是CMS并发收集器
CMS是从JDK1.5以后开始推出的一款垃圾收集器,它关注的点是尽可能的缩短用户线程的停顿时间,停顿时间越短,就越适合与用户交互的程序,良好的响应速度提升用户的体验
为什么 Serial Old 将作为 CMS 出错的后备收集器
因为CMS是一款并发收集器,它在回收时用户线程是没有中断的,所以在CMS回收时还需要确保用户线程有足够的内存可用,并不能在空间满的时间才回收,所以当内存使用率达某一阀值时,CMS需要提前开始回收,以确保CMS回收时仍然有足够的内存供用户线程运行
因为CMS回收时用户线程是没有中断的,会继续制造垃圾,所以当CMS回收时预留的内存无法满足用户线程的需要,会出现一次 "Concurrent Mode Failure",回收失败,这时虚拟机将启动后备的方案,也就是Serial Old垃圾收集器,但是这样停顿的时间就很长了
CMS 并发收集步骤
初始标记(initial mark):相当于给所有 GC Roots 能直接关联的对象说一声,大家停一下,我要开始进行垃圾收集了 速度很快,但此步需要暂停工作线程。
并发标记(concurrent mark):开始和用户线程一起进行 GC Roots 跟踪,给每一个需要回收的对象打标记 ,此步不需要暂停工作线程。
重新标记(remark):因为第二步不会暂停程序,所以为了防止在打标记的过程中,有些对象状态发生了改变,所以需要重新确认一下,这是清理的前一步工作,很重要,所以为了清理的准确性,在确认时,需要暂停工作线程
并发清除(concurrent sweep):清除 GC Roots 不可达对象,和用户线程一起工作,不需要暂停工作线程。
CMS弊端
- 会产生内存碎片,导致并发清除后,用户线程可用的空间不足。
2. 既然强调了并发(Concurrent),CMS收集器对CPU资源非常敏感
3. CMS 收集器无法处理浮动垃圾
上述的这些问题,尤其是碎片化问题,给你的JVM实例就像埋了一颗炸弹。说不定哪次就在你的业务高峰期来一次FGC。
当CMS停止工作时,会把Serial Old GC 作为备选方案,而Serial Old GC 是JVM中性能最差的垃圾回收方式,停顿个几秒钟,上十秒都有可能。
既然标记清除会导致大量碎片,为什么CMS不使用标记压缩呢
因为CMS是并发垃圾收集器,当工作时用户线程也在执行,如果用标记压缩,相当把对象的引用都改变了,那用户线程原来使用的内存还怎么用呢,所以要保证用户线程不受影响,前提是它运行的资源不受影响
GI 并发收集器(Garbage-First)
什么是G1并发收集器
G1是一款面向服务端应用的收集器,主要针对多CPU和大容量内存机器,在实现高吞吐量的同时,尽可能的满足垃圾收集暂停时间的要求
G1默认将整个堆划分为2048个大小相同的独立Region块,使用不同的Region来表示Eden、S0、S1、以及老年代等。虽然还保留了新生代和老年代的概念,但新生代和老年代不再是物理隔离的了,在G1中他们都是一部分的Region(不需要连续),通过Region动态分配方式实现逻辑上的连续
JDK1.9默认就是该收集器
G1 收集器针对大对象的处理特性
在G1中,有一种特殊的区域,叫 Humongous(巨大的)区域。如果一个对象占用的空间超过了1.5个Region,G1收集器就认为这是一个大对象, 这些大对象默认直接会被分配在老年代(大对象不适合在Young区),但是如果它是一个短期存在的大对象,就会对垃圾收集器造成负面影响。
为了解决这个问题,G1划分了一个Humongous区,它用来专门存放大对象。如果一个 Humongous 区装不下这个大对象,那么G1会寻找连续的 Humongous 分区来存储。为了能找到连续的 Humongous 区,有时候不得不启动Full GC
G1相比于CMS的优势
G1不会产生内存碎片
相比于CMS的标记清理算法,G1是将内存划分为一个个的Region,内存回收是以Region作为基本单位的,Region之间采用的是复制算法,在整理上又采用的标记压缩算法,所以能有效避免内存碎片。有利于程序长时间的运行
能更好的控制停顿时间
由于G1是将内存划分为一个个的Region,所以可以只选取部分区域进行回收,这样就缩小了回收的范围,不像原来整个Young区进行回收,或者整个Old区进行回收,对于这种全局停顿的情况发生也得到了较好的控制
G1在回收时会跟踪各个Region里面的垃圾堆积价值大小,在后台维护一个优先列表,每次根据允许的收集时间,优先回收价值最大的Region,从而保证G1收集器在有限的时间内可以获取尽可能高的收集效率
G1相比于CMS的劣势
G1为了垃圾收集而产生的内存占用,还有程序进行时的额外执行负载都要比CMS高
G1不适合用于小内存的应用上,内存过小不利于Region的分配,导致在遇到大对象时很难找到连接的存储空间,建议是8g以上应用适合G1
G1 并发收集步骤(与CMS类似)
初始标记:只标记GC Roots能直接关联到的对象
并发标记:进行GC Roots Tracing的过程
最终标记:修正并发标记期间,因程序运行导致标记发生变化的那一部分对象
筛选回收:根据时间来进行价值最大化的回收
G1 常用配置参数
-XX:+UseG1GC
开启G1收集器
-XX:G1HeapRegionSize
设置每个Region大小,值是2的幂数,大小是1到32M之间,目标是根据最小的Java堆大小划分出2048个Region,默认是堆内存的 1/2000
也就是说 -Xmx 分配为4g,则每块Region区域大小大约就是 4 * 1024 = 4096 / 2000 = 2M 左右
-XX:MaxGCPauseMillis
设置期望达到的最大GC停顿时间指标,这是一个软性指标,JVM会尽力实现,但不保证达到,默认值是200ms
由于G1在回收时,是在后台维护一个优先列表,每次根据允许的收集时间,优先回收价值最大的Region,如果这个时间设置过小,比如20ms,那么原来根据优先列表能回收5、10个Region的,现在只能先放弃列表前面较大的Region,只回收2个Region,来尽可能满足停顿时间指标
这种情况下用户线程在前面使用Region率又比较高,但是G1回收Region率又比较小,内存使用率就会越来越高,最终导致占满,占满以后那就触发 Full GC
所以这种看似设置停顿时间低,会说延迟效果会好,其实反而性能是下降了的
怎么查看服务器默认的垃圾收集器是哪个
查看服务器Java默认的垃圾收集器

java -XX:+PrintCommandLineFlags -version
查看某个Java程序具体使用的垃圾收集器
jps 显示出当前java进程号
jinfo -flag 进程号 查看该进程号java程序当前正在使用的所有JVM参数,就会有垃圾收集器
线上服务器CPU负载过高(飙升100%了),该怎么排查、定位和解决
top -c 定位耗费cpu的进程

top -c,就可以显示进程列表,然后输入P,按照cpu使用率排序
top -Hp 43987 定位耗费cpu的线程

top -Hp 43987,就是输入那个进程id就好了,然后输入P,按照cpu使用率排序
定位哪段代码导致的cpu过高
将线程pid转换成16进制
printf "%x\n" 16872,把线程pid转换成16进制,比如0x41e8
使用jstack命令定位代码
jstack 43987 | grep ‘0x41e8’ -C5 --color
这个就是用jstack打印进程的堆栈信息,而且通过grep那个线程的16进制的pid,找到那个线程相关的东西,这个时候就可以在打印出的代码里,看到是哪个类的哪个方法导致的这个cpu 100%的问题
生产环境服务器变慢,诊断思路和性能评估谈谈
top 查看整体情况

top 后 再按 1 可以查看每个 CPU 的情况
load average 表示系统当前平均负载值,从左到右分别是 1 分钟 、 10 分钟、15 分钟 的情况,如果三个值相加除以60再乘100%,结果高于60,表示系统负载压力重
查看CPU使用情况
安装命令工具:yum install -y sysstat
vmstat -n 2 3
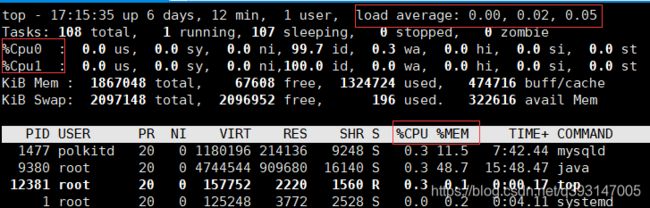
每隔2秒采样一次CPU的情况,共采样3次
r
运行等待CPU时间片的进程数,原则整个系统的运行数不能超过总核数的2倍,否则代表系统压力过大
us、sy
用户进程消耗CPU时间百分比;内核进程消耗的CPU百分比;
如果这两个值过高,表示用户进程消耗CPU时间多,如果长期大于50%,优化程序;
mpstat -P ALL 2

每隔2秒,采样一次所有CPU的情况
%usr :用户使用情况 %sys:系统使用情况
%idle:CPU的空闲率,越高越好,如果低于60%,说明系统压力就大了
pidstat -u 1 -p 9380(进程号)
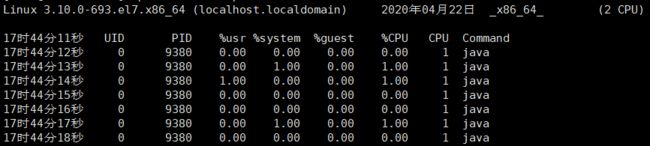
每秒采样1次,这个进程的具体CPU使用情况
查看内存使用情况
free -m

一般 应用程序使用的总内存只要没超过 系统总内存 的 70 % 就没问题,超过了就补内存
pidstat -p 9380(进程号) -r 2

每2秒采样1次,这个进程的具体内存使用情况
查看磁盘使用情况
df -h

查看磁盘总体使用情况
iostat -xdk 2 3

查看磁盘IO性能
rkB/s:每秒读取数据量
wkB/s:每秒写入数据量
%util:每秒有百分之几的时间用于IO操作,接近100时,表示磁盘带宽跑满,需要优化或增加磁盘
查看网络使用情况
本地默认没有,需要下载该工具
wget http://gael.roualland.free.fr/ifstat/ifstat-1.1.tar.gz
tar xvf ifstat-1.1.tar.gz
cd ifstat-1.1/
./configure
make
make install
ifstat 1
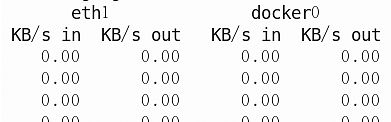
=========================================================
常见JAVA面试题总结<2020 java面试必备>(一)
常见JAVA面试题总结<2020 java面试必备>(二)多线程
常见JAVA面试题总结<2020 java面试必备>(四)设计模式
常见JAVA面试题总结<2020 java面试必备>(五) 网络