掌握搭建大数据集群的方法是学习大数据技术的人需要具备的基础技能,因此我会通过接下来的系列文章介绍大数据平台的搭建方法。在本文中我将向小伙伴们介绍一下搭建大数据集群需要哪些知识以及我们接下来搭建的大数据集群平台架构,让大家对平台有个总体的认识并普及一些概念。
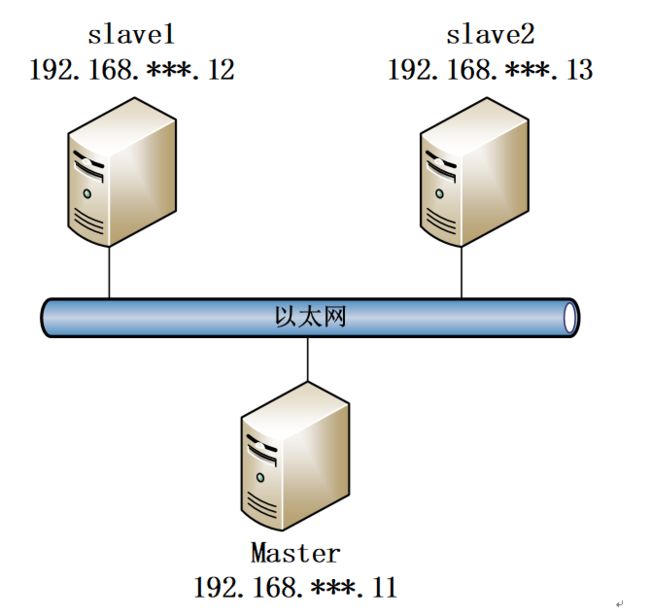
集群搭建完成后我们总共会有四个虚拟机,其中伪分布集群有一台虚拟机,虚拟机名称为single_node。分布式集群有三个虚拟机 名称分别为master、slave1、slave2。各个虚拟机的IP配置及安装软件(含软件运行的模块)如下表所示。
| hostname | single_node | master | slave1 | slave2 |
|---|---|---|---|---|
| IP | 192.168.***.10 | 192.168.***.11 | 192.168.***.12 | 192.168.***.13 |
| Hadoop | NN DN NM RM SNN | NN SNN RM | DN NM | DN NM |
| Spark | Master Worker | Master | Worker | Worker |
| Hive | Hive | Hive | / | / |
| Zookeeper | QuorumPeerMain | QuorumPeerMain | QuorumPeerMain | QuorumPeerMain |
| Hbase | HMaster | HMaster | HRegionServer | HRegionServer |
| Sqoop | sqoop | sqoop | / | / |
注:hostname:每个节点的主机名称
IP:每个节点的IP地址
NN:NameNode
DN:DataNode
NM:NodeManager
RM:ResourceManager
SNN:SecondaryNameNode
/ :表示不安装
分布式集群的架构如下图所示
1、硬件
节点:我们后面会经常提到节点,分布式环境中一个服务器就是一个节点,在我们搭建的集群中服务器指的是通过VMware软件虚拟出来的虚拟机。
操作系统:服务器上运行的操作系统基本上都是Linux操作系统,当然虚拟机中安装的也是Linux系统。
网络:集群中的多个节点之间协同工作需要不断交换数据及状态、命令等信息,因此需要互通的网络环境。我们的集群是通过虚拟机软件虚拟出来的,网络也是由虚拟机软件虚拟出的虚拟网卡来实现数据交换的。
2、软件
集群中的软件主要有 hadoop、spark、hive、hbase、zookeeper这几个。
Hadoop
虽然大数据集群平台根据具体业务需求不同配置组成不同,但大部分集群都会以hadoop集群为基础。例如大数据仓库Hive及分布式数据库Hbase的存储都会用到hadoop集群的分布式文件系统HDFS,计算部分默认使用Hadoop原生的MapReduce计算框架。分布式计算框架spark可以使用hadoop内置的通用资源管理模块yarn来提供统一的资源管理和调度。
hadoop大数据集群一般说来可以有单机模式、伪分布模式、分布式模式这三种模式。
分布式模式:是实际应用的一种模式,分布式集群由多个节点组成理论上集群中的节点越多,集群的性能也就越好。
单机模式:单机模式只在一个节点上运行,是一种默认的配置方式,无需进行其他配置即可运行,以单Java进程运行,方便进行调试,此时HDFS是不可用的。
伪分布式:此模式同样也是在单节点上运行的,与单机模式不同的是程序是以不同的Java进程来运行的,节点即作为NameNode也作为DataNode,此时可以使用HDFS,是常用的开发测试模式。
Spark
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎,是目前比较流行的分布式计算框架。
Spark 主要有三个特点 :
首先,高级 API 剥离了对集群本身的关注,Spark 应用开发者可以专注于应用所要做的计算本身。
其次由于是基于内存的计算框架等原因,Spark 很快,支持交互式计算和复杂算法。
最后,Spark 是一个通用引擎,可用它来完成各种各样的运算,包括 SQL 查询、文本处理、机器学习等,而在 Spark 出现之前,我们一般需要学习各种各样的引擎来分别处理这些需求。
Hive
hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
Zookeeper
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
Hbase
HBase是一个分布式的、面向列的开源数据库,HBase在Hadoop之上提供了类似于Bigtable的能力。HBase是Apache的Hadoop项目的子项目。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。
Sqoop
是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql、postgresql...)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。