Python爬虫和数据可视化
一、字符串
1、字符串里的转义符
转义字符 |
描述 |
|---|---|
| (在行尾时) | 续行符 |
| \\ | 反斜杠符号 |
| \’ | 单引号 |
| \" | 双引号 |
| \a | 响铃 |
| \b | 退格(Backspace) |
| \000 | 空 |
| \n | 换行 |
| \t | 横向制表符 |
| \r | 回车 |
| \v | 纵向制表符 |
| \f | 换页 |
2、字符串的输出
str_1 = "chengdudexiaojiuguan"
print(str_1[:5]) # 显示从开头到第四个
print(str_1 + "是我的") # 字符串拼接
print(str_1 * 3) # 字符串成倍显示
print("Hello\nxiaomeng") # 中间有 \n ,换行
print(r"Hello\nxiaomeng") # 当开头有一个 r , 后面的转义符都不生效,显示原始字符串
--->
cheng
chengdudexiaojiuguan是我的
chengdudexiaojiuguanchengdudexiaojiuguanchengdudexiaojiuguan
Hello
xiaomeng
Hello\nxiaomeng
3、字符串常见操作
str_3 = "12345abcde"
print(str_3.isalnum()) # 字符串中至少一个字符且所有字符包含字母或数字
print(str_3.isalpha()) # 字符全是字母
print(str_3.isdigit()) # 字符全是数字
print(len(str_3)) # 字符串长度
print(','.join(str_3)) # 将 , 加入到str_3字符串中, 即用 , 分割str_3
-->
True
False
False
10
1,2,3,4,5,a,b,c,d,e
| 函数 | 作用 |
|---|---|
| lstrip() | 删除字符串左边的空格或指定字符 |
| rstrip() | 删除字符串末尾的空格 |
| rsplit() | 删除两边的空格,并返回一个列表 |
| split() | 拆分成n个字符串 |
二、列表
1、常用操作
| 操作名称 | 操作方法 | 举例 |
|---|---|---|
| 访问列表中的元素 | 通过下标 | print(list[0]) |
| 列表切片 | 使用[: :] | list[2:5:2] |
| 遍历列表 | 通过for循环 | for i in liist: print(i) |
| 【增】新增数据到列表末尾 | 使用append方法 | list.append(5) |
| 【增】列表的追加 | 使用entend方法 | list.extend(list_2) |
| 【增】列表数据插入 | 使用insert方法 | list.insert(1,3) |
| 【删】列表的删除 | del:通过索引删除指定位置的元素 remove:移除列表中指定值的第一个匹配值, 没找到会抛异常 |
del list[1] list.remove(1) 注意两种方法的区别 |
| 删除列表尾部的元素 | 使用pop | list.pop() |
| 【改】更新列表中的数据 | 通过下标原地修改 | list[0] |
| 【查】列表成员的关系 | in、not in | 2 in list |
| 列表的加法操作 | + | list3 = list1 + list2 |
| 【排】列表的排序 | sort方法 | list.sort() |
| 【排】列表的反转 | reverse | list.reverse() |
增
a = [1, 2]
b = [3, 4]
a.append(b) # 将b列表作为一个元素加入a列表
print(a)
a.extend(b) # 将整个列表插入另一个列表
print(a)
c = [0, 1, 2]
c.insert(1, 5) # 指定下标位置插入元素
print(c)
--->
[1, 2, [3, 4]]
[1, 2, [3, 4], 3, 4]
[0, 5, 1, 2]
删
movelists = ['加勒比海盗', '肖申克的救赎', '教父', '阿甘正传', '战狼2', '复仇者联盟4']
del movelists[2] # 指定位置删除元素
print(movelists)
movelists.pop() # 删除末尾的元素
print(movelists)
movelists.remove('战狼2') # 直接删除指定内容
print(movelists)
--->
['加勒比海盗', '肖申克的救赎', '阿甘正传', '战狼2', '复仇者联盟4']
['加勒比海盗', '肖申克的救赎', '阿甘正传', '战狼2']
['加勒比海盗', '肖申克的救赎', '阿甘正传']
改
girl_lists = ['XiangMei', 'ZhaoXiaomeng', 'SunKaixin', 'LiuJiawen', 'HouRuijuan']
print(girl_lists)
girl_lists[1] = "PingEr" # 修改指定下标的元素
print(girl_lists)
--->
['XiangMei', 'ZhaoXiaomeng', 'SunKaixin', 'LiuJiawen', 'HouRuijuan']
['XiangMei', 'PingEr', 'SunKaixin', 'LiuJiawen', 'HouRuijuan']
查
# 【in, not in】
girl_lists = ['XiangMei', 'ZhaoXiaomeng', 'SunKaixin', 'LiuJiawen', 'HouRuijuan']
name = input("请输入你女朋友的名字:")
if name not in girl_lists:
print("还需努力呀")
else:
print("干的好")
print(girl_lists.index('SunKaixin', 1, 4)) # 在下标1~4范围内查找'SunKaixin',返回下标
三、文件操作
1、文件的打开
使用open函数,可以打开一个一存在的文件,或者创建一个新文件
f = open('text.txt', 'w')
f.close() # 关闭文件
说明:
| 访问模式 | 说明 |
|---|---|
| r | 以只读方式打开文件。文件指针会放在文件的开头。这也是默认模式 |
| w | 打开一个文件只用于写入。若文件存在则将其覆盖,若不存在则创建新文件 |
| a | 打开一个文件用于追加。若文件已存在,文件指针将放在文件末尾。新的内容将放在现存内容之后 若不存在,则创建新文件写入 |
| rb | 以二进制格式打开一个文件用于只读。文件指针会放在文件开头。这是默认模式 |
| wb | 以二进制格式打开一个文件只用于写入。若文件存在将其覆盖,若不存在则创建新文件 |
| ab | 以二进制格式打开打开一个文件用于追加。若文件存在,文件指针放在文件末尾,即新内容会写入到现存内容之后 若文件不存在,创建新文件进行写入 |
| r+ | 打开一个文件用于读写。文件指针会放在文件开头 |
| w+ | 打开一个文件用于读写。若文件存在将其覆盖,若不存在,创建新文件 |
| a+ | 打开一个文件用于读写。若文件存在,文件指针会放在文件末尾。文件打开时会是追加模式。若文件不存在,创建文件用于读写 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件开头 |
| wb+ | 以二进制格式打开一个文件用于读写。文件已存在则将其覆盖。文件不存在则创建新文件 |
| ab+ | 一二进制格式打开一个文件用于追加。若文件存在,文件指针会放在文件的结尾。若文件不存在,则创建新文件用于读写 |
2、文件写入
# 文件写入
f = open('text.txt', 'w')
text = '''
I heard, that your settled down.
听说 你心有所属
That you, found a girl and your married now.
你遇到了她,即将步入婚姻殿堂
I heard that your dreams came true.
听说你美梦成真
Guess she gave you things, I didn't give to you.
看起来与我相比,她才是最好的
'''
f.write(text) # 将内容写入文件
f.close() # 关闭文件
3、文件读取
# 文件读取 按字符
f = open('text.txt', 'r')
content = f.read(5)
print(content)
content = f.read(10)
print(content)
f.close()
# 文件读取 按行
f = open('text.txt' ,'r')
content = f.readlines() # 一次性读取全部文件为列表,每行一个字符串元素
i = 1
for temp in content:
print("%d:%s" %(i,temp), end="")
i += 1
f.close()
4、文件的其他不太常用的操作
4.1、文件的重命名
os模块中的rename()可以完成对文件的重命名操作
import os
os.rename("text.txt","some_like_you")
4.2、文件删除
os模块中的remove()模块可以对文件完成删除操作
import os
os.remove("text.txt")
四、错误与异常
1、出现异常
open('123.txt', 'r')
--->
Traceback (most recent call last):
File "D:\python3.9\项目1\day20_shixun\demo2\异常处理.py", line 7, in <module>
open('123.txt', 'r')
FileNotFoundError: [Errno 2] No such file or directory: '123.txt'
2、分类捕获异常
try:
print(num)
f = open('123.txt', 'r')
except IOError as e:
print('没找到文件', e)
except NameError as e:
print('输出的东东没有定义', e)
--->
输出的东东没有定义 name 'num' is not defined
3、捕获全部异常
try:
print(num)
f = open('123.txt', 'r')
except Exception as e: # 将所有的错误类型承接到Exception
print('出现错误了', e)
--->
出现错误了 name 'num' is not defined
4、finally输出
name = ['lishang','zhaoxiaomeng']
try:
name[3]
except KeyError as e:
print("没有这个key:",e)
except IndexError as e:
print("超出列表范围:",e)
except Exception as e:
print("出错了,位置错误:",e)
else:
print("一切正常")
finally:
print("不管有没有错误都执行")
五、Python爬虫
1、任务介绍
爬取豆瓣电影Top10的基本信息,包括电影的名称、豆瓣评分、评价数、电影概况、电影链接等。
2、基本流程
准备工作:
通过浏览器查看分析目标网页,学习编程基础规范
获取数据:
通过HTTP库向目标站点发起请求,请求可以包含额外的header等信息,如果服务器能正常响应,会得到一个Response,便是所要获取的页面内容。
解析内容:
得到的内容可能是HTML,Json等格式,可以用页面解析库、正则表达式等进行解析。
保存数据:
保存形式多样,可以存为文本,也可以保存到数据库,或者保存特定格式的文件。
网址链接:https://movie.douban.com/top250
3、引入模块
3.1、补充urllib
对返回的网页源码进行utf-8的解码
import urllib.request
import urllib.parse
import urllib.error
# 获取一个get请求
response1 = urllib.request.urlopen("http://www.baidu.com")
print(response1.read().decode('utf-8'))
# 获取一个 post 请求
data = bytes(urllib.parse.urlencode({
"hello":"world"}), encoding="utf-8")
response2 = urllib.request.urlopen("http://httpbin.org/post", data=data)
print(response2.read().decode('utf-8'))
# 获取一个 get 请求
try:
# 超时处理
response3 = urllib.request.urlopen("http://httpbin.org/get", timeout=0.1)
print(response3.read().decode('utf-8'))
except urllib.error.URLError as e:
print("time out", e)
# 爬虫www.douban.com被发现了,返回418
response4 = urllib.request.urlopen("https://www.douban.com", timeout=1)
print(response4.status)
3.2、伪装一下再爬取 httpbin.org
# 伪装一下再爬
urll = "http://httpbin.org/post"
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36"
}
data = bytes(urllib.parse.urlencode({
"hello":"world"}), encoding="utf-8")
req = urllib.request.Request(url=urll, data=data, headers=headers, method="POST")
response = urllib.request.urlopen(req)
print(response.read().decode('utf-8'))
3.3、伪装一下再爬取 www.douban.com,这次好了
url = "https://www.douban.com"
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36"
}
req = urllib.request.Request(url=url,headers=headers)
response = urllib.request.urlopen(req)
print(response.read().decode('utf-8'))
3.4、补充BeautifulSoup(网页解析)
网页示例
DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta content="text/html" http-equiv="content-type" />
<meta content="IE-Edge" http-equiv="X-UA-Compatible" />
<meta content="always" name="referrer" />
<link href="https://ss1.bdstatic.com/5eN1bjq8AAUYm2zgoY3K/r/www/cache/bdorz/baidu.min.css" rel="stylesheet" type="text/css">
<title>百度一下,你可能也不知道title>
head>
<body link="#e9967a">
<div id="wrapper">
<div id="head">
<div id="u1">
<a class="mnav" href="http://news.baidu.com" name="tj_trnews">a>
<a class="mnav" href="http://news.baidu.com" name="tj_trnews">新闻a>
<a class="mnav" href="https://www.hao123.com" name="tj_trhao123">hao123a>
<a class="mnav" href="http://map.baidu.com" name="tj_trmap">地图a>
<a class="mnav" href="http://v.baidu.com" name="tj_trvideo">视频a>
<a class="mnav" href="http://tieba.baidu.com" name="tj_trtieba">贴吧a>
<a class="mnav" href="http://www.baidu.com/more/" name="tj_briicon" style="...">更多产品a>
div>
div>
div>
body>
html>
bs4代码示例
from bs4 import BeautifulSoup
file = open("./baidu.html", "rb")
html = file.read()
bs = BeautifulSoup(html, "html.parser")
# 1.Tag 标签及其内容,默认拿到他拿到的第一个内容
# print(bs.title)
# print(bs.a)
# print(bs.head)
# 2.String 所搜索的标签的内容
# print(bs.title.string)
# print(bs.a.string)
# 3.attrs 所搜索标签的属性
# print(bs.a.attrs)
# 4.BeautifulSoup 文件本身
# print(bs)
# 5.Comment 是一个特殊的NavigableString 输出的内容不包含注释符号
# print(bs.a.string)
3.5、BeautifulSoup–遍历文档树
帮助文档: http://www.jsphp.net/python/show-24-214-1.html
5.1、.contents:获取Tag的所有子节点,返回一个list
# tag的.content 属性可以将tag的子节点以列表的方式输出
print(bs.head.contents)
# 用列表索引来获取它的某一个元素
print(bs.head.contents[1])
5.2、.children:获取Tag的所有子节点,返回一个生成器
for child in bs.body.children:
print(child)
5.3、.descendants:获取Tag的所有子孙节点
5.4、.strings:如果Tag包含多个字符串,即在子孙节点中有内容,可以用此获取,而后进行遍历
5.5、.stripped_strings:与strings用法一致,只不过可以去除掉那些多余的空白内容
5.6、.parent:获取Tag的父节点
5.7、.parents:递归得到父辈元素的所有节点,返回一个生成器
5.8、.previous_sibling:获取当前Tag的上一个节点,属性通常是字符串或空白,真实结果是当前标签与上一个标签之间的顿号和换行符
5.9、.next_sibling:获取当前Tag的下一个节点,属性通常是字符串或空白,真是结果是当前标签与下一个标签之间的顿号与换行符
5.10、.previous_siblings:获取当前Tag的上面所有的兄弟节点,返回一个生成器
5.11、.next_siblings:获取当前Tag的下面所有的兄弟节点,返回一个生成器
5.12、.previous_element:获取解析过程中上一个被解析的对象(字符串或tag),可能与previous_sibling相同,但通常是不一样的
5.13、.next_element:获取解析过程中下一个被解析的对象(字符串或tag),可能与next_sibling相同,但通常是不一样的
5.14、.previous_elements:返回一个生成器,可以向前访问文档的解析内容
5.15、.next_elements:返回一个生成器,可以向后访问文档的解析内容
5.16、.has_attr:判断Tag是否包含属性
3.6、BeautifulSoup–搜索文档树
6.1、find_all(name, attrs, recursive, text, **kwargs)
在上面的栗子中我们简单介绍了find_all的使用,接下来介绍一下find_all的更多用法-过滤器。这些过滤器贯穿整个搜索API,过滤器可以被用在tag的name中,节点的属性等。
(1)name参数:
字符串过滤:会查找与字符串完全匹配的内容
a_list = bs.find_all("a")
print(a_list)
正则表达式过滤:如果传入的是正则表达式,那么BeautifulSoup4会通过search()来匹配内容
from bs4 import BeautifulSoup
import re
file = open('./aa.html', 'rb')
html = file.read()
bs = BeautifulSoup(html,"html.parser")
t_list = bs.find_all(re.compile("a"))
for item in t_list:
print(item)
列表:如果传入一个列表,BeautifulSoup4将会与列表中的任一元素匹配到的节点返回
t_list = bs.find_all(["meta","link"])
for item in t_list:
print(item)
方法:传入一个方法,根据方法来匹配
from bs4 import BeautifulSoup
file = open('./aa.html', 'rb')
html = file.read()
bs = BeautifulSoup(html,"html.parser")
def name_is_exists(tag):
return tag.has_attr("name")
t_list = bs.find_all(name_is_exists)
for item in t_list:
print(item)
(2)kwargs参数:
from bs4 import BeautifulSoup
import re
file = open('./aa.html', 'rb')
html = file.read()
bs = BeautifulSoup(html,"html.parser")
# 查询id=head的Tag
t_list = bs.find_all(id="head") print(t_list)
# 查询href属性包含ss1.bdstatic.com的Tag
t_list = bs.find_all(href=re.compile("http://news.baidu.com"))
print(t_list)
# 查询所有包含class的Tag(注意:class在Python中属于关键字,所以加_以示区别)
t_list = bs.find_all(class_=True)
for item in t_list:
print(item)
(3)attrs参数:
并不是所有的属性都可以使用上面这种方式进行搜索,比如HTML的data-*属性:
t_list = bs.find_all(data-foo="value")
如果执行这段代码,将会报错。我们可以使用attrs参数,定义一个字典来搜索包含特殊属性的tag:
t_list = bs.find_all(attrs={
"data-foo":"value"})
for item in t_list:
print(item)
(4)text参数:
通过text参数可以搜索文档中的字符串内容,与name参数的可选值一样,text参数接受 字符串,正则表达式,列表
from bs4 import BeautifulSoup
import re
file = open('./aa.html', 'rb')
html = file.read()
bs = BeautifulSoup(html, "html.parser")
t_list = bs.find_all(attrs={
"data-foo": "value"})
for item in t_list:
print(item)
t_list = bs.find_all(text="hao123")
for item in t_list:
print(item)
t_list = bs.find_all(text=["hao123", "地图", "贴吧"])
for item in t_list:
print(item)
t_list = bs.find_all(text=re.compile("\d"))
for item in t_list:
print(item)
当我们搜索text中的一些特殊属性时,同样也可以传入一个方法来达到我们的目的:
def length_is_two(text):
return text and len(text) == 2
t_list = bs.find_all(text=length_is_two)
for item in t_list:
print(item)
(5)limit参数:
可以传入一个limit参数来限制返回的数量,当搜索出的数据量为5,而设置了limit=2时,此时只会返回前2个数据
from bs4 import BeautifulSoup
import re
file = open('./aa.html', 'rb')
html = file.read()
bs = BeautifulSoup(html, "html.parser")
t_list = bs.find_all("a",limit=2)
for item in t_list:
print(item)
find_all除了上面一些常规的写法,还可以对其进行一些简写:
# 两者是相等的
# t_list = bs.find_all("a") => t_list = bs("a")
t_list = bs("a") # 两者是相等的
# t_list = bs.a.find_all(text="新闻") => t_list = bs.a(text="新闻")
t_list = bs.a(text="新闻")
6.2、find()
find()将返回符合条件的第一个Tag,有时我们只需要或一个Tag时,我们就可以用到find()方法了。当然了,也可以使用find_all()方法,传入一个limit=1,然后再取出第一个值也是可以的,不过未免繁琐。
from bs4 import BeautifulSoup
import re
file = open('./aa.html', 'rb')
html = file.read()
bs = BeautifulSoup(html, "html.parser")
# 返回只有一个结果的列表
t_list = bs.find_all("title",limit=1)
print(t_list)
# 返回唯一值
t = bs.find("title")
print(t)
# 如果没有找到,则返回None
t = bs.find("abc") print(t)
从结果可以看出find_all,尽管传入了limit=1,但是返回值仍然为一个列表,当我们只需要取一个值时,远不如find方法方便。但
是如果未搜索到值时,将返回一个None
在上面介绍BeautifulSoup4的时候,我们知道可以通过bs.div来获取第一个div标签,如果我们需要获取第一个div下的第一个div,
我们可以这样:
t = bs.div.div
# 等价于
t = bs.find("div").find("div")
3.7、BeautifulSoup–CSS选择器
BeautifulSoup支持发部分的CSS选择器,在Tag获取BeautifulSoup对象的.select()方法中传入字符串参数,即可使用CSS选择器的语法找到Tag:
7.1、通过标签名查找
print(bs.select('title'))
print(bs.select('a'))
7.2、通过类名查找
print(bs.select('.mnav'))
7.3、通过id查找
print(bs.select('#u1'))
7.4、组合查找
print(bs.select('div .bri'))
7.5、属性查找
print(bs.select('a[class="bri"]'))
print(bs.select('a[href="http://tieba.baidu.com"]'))
7.6、直接子标签查找
t_list = bs.select("head > title")
print(t_list)
7.7、兄弟节点标签查找
t_list = bs.select(".mnav ~ .bri")
print(t_list)
7.8、获取内容
t_list = bs.select("title")
print(bs.select('title')[0].get_text())
六、正则表达式(re模块)
参考链接:https://www.cnblogs.com/dreamingbaobei/p/9717234.html
正则表达式的常用符号(一)
| 操作符 | 说明 | 实例 |
|---|---|---|
| . | 表示任何单个字符 | |
| [ ] | 字符集,对单个字符给出取值范围 | [abc] 表示 a、b、c,[a-z] 表示 z-a 单个字母 |
| [^ ] | 非字符集,对单个字符给出排除范围 | [^abc] 表示 非a或b或c的单个字母 |
| * | 前一个字符0次或无限次扩展 | abc* 表示 ab、abc、abcc、abccc等 |
| + | 前一个字符1次或无限次扩展 | abc+ 表示 abc、abcc、abccc等 |
| ? | 前一个字符0次或1次扩展 | abc? 表示 ab、abc |
| | | 左右表达式任意一个 | abc|def 表示 abc或def |
正则表达式的常用符号(二)
| 操作符 | 说明 | 实例 |
|---|---|---|
| {m} | 扩展前一个字符m次 | ab{2}c 表示 abbc |
| {m, n} | 扩展掐一个字符m次至n次,包含n次 | ab{1,2}c 表示 abc、abbc |
| ^ | 匹配字符串开头 | ^abc 表示 abc且在一个字符串的开头 |
| $ | 匹配字符串结尾 | abc$ 表示 abc且在一个字符串的结尾 |
| ( ) | 分组标记,内部职能使用 | 操作符 | (abc) 表示abc,(abc|def) 表示 abc、def |
| \d | 数字,等价于[0-9] | |
| \w | 单词字符,等价于[A-Za-z0-9_] |
Re库主要功能函数
| 函数 | 说明 |
|---|---|
| re.search() | 在一个字符串中搜索匹配正则表达式的第一个位置,返回match对象 |
| re.match() | 从一个字符串的开始位置起匹配正则表达式,返回match对象 |
| re.findall() | 搜索字符串,以列表类型返回全部能匹配的字符串 |
| re.split() | 将一个字符串按照正则表达式匹配结果进行分割,返回列表类型 |
| re.finditer() | 搜索字符串,返回一个匹配结果的迭代类型,每个迭代元素是match对象 |
| re.sub() | 在一个字符串中替换所有匹配正则表达式的字符串,返回替换后的字符串 |
正则表达式可以包含一些可选标志修饰符来匹配的模式。修饰符备指定为一个可选的标志。多个标志可以通过按位 OR(|) 它们来指定。如 re.I | re.M 被设置成 I 和 M 标志:
| 修饰符 | 描述 |
|---|---|
| re.I | 使匹配对大小不敏感 |
| re.L | 做本地化识别(locale-aware) |
| re.M | 多行匹配,影响 ^ 和 $ |
| re.S | 使 . 匹配包括换行在内的所有字符 |
| re.U | 根据Unicode字符集解析字符。这个标志影响\w,\W,\b,\B. |
| re.X | 该标志通过给予你更灵活的格式一遍你讲正则表达式写的更易于理解。 |
实例:
import re
# 创建模式对象
pat = re.compile("AA") # 此处的AA,是正则表达式,用来去验证其他的字符串
m = pat.search("DBA") # search字符串是被校验的内容
print(m)
n = pat.search("DBAAWQEFSFSAA")
print(n)
# 没有模式对象
q = re.search("asd", "Aasd") # 前面是规则(模板),后面是被校验的对象
print(q)
print(re.findall("a", "qwOEqaeLMNafRg")) # 前面是规则(正则表达式), 后面的字符串是被校验的字符串
print(re.findall("[A-Z]+", "qwOEqaeLMNafRg"))
# sub
print(re.sub("a", "A", "AwOEqaeLMNafRg")) # 找到a,用A来替换,在第三个字符串中查找
七、正式爬取豆瓣Top250片子,解析内容
#-*- coding:utf-8 -*-
#@Author: li Shang
#@Time: 2021/5/7 9:33
#@File: spider.py
#@Software: PyCharm
import urllib.request
import urllib.error
from bs4 import BeautifulSoup
import re
def main():
# global baseurl
baseurl = "https://movie.douban.com/top250?start="
datalist = getData(baseurl)
# print(datalist)
savepath = ".\\豆瓣电影Top250.xls"
# 匹配影片详情链接的规则
findLink = re.compile(r'') # 创建正则表达式对象,表示规则或者字符串的模式
# 匹配影片图片的链接
findImSrc= re.compile(r', re.S) # re.S 让换行符包含在字符中
# 匹配影片的片名
findtitle = re.compile(r'(.*?)')
# 匹配影片的评分
findRating = re.compile(r'')
# 评价人数
findJudge = re.compile(r'(\d*)人评价')
# 影片的概况
findInq = re.compile(r'(.*?)')
# 影片的相关内容
findBd = re.compile(r'(.*?)
', re.S)
# 爬取网页
def getData(baseurl):
datalist = []
for i in range(0,10):
url = baseurl + str(i*25)
html = askURL(url)
# 逐一进行解析
soup = BeautifulSoup(html, "html.parser")
for item in soup.find_all("div",class_="item"):
# print(item)
data = []
item = str(item)
link = re.findall(findLink, item)[0] # 获取影片详情链接
data.append(link)
imgSrc = re.findall(findImSrc, item)[0] # 获取图片
data.append(imgSrc)
titles = re.findall(findtitle, item) # 获取片名,片名可能只有中文的,没有英文的
if(len(titles) == 2):
ctitle = titles[0] #添加中文名
data.append(ctitle)
ftitle = titles[1].replace("/", "") #去掉斜杠,添加外国名
data.append(ftitle)
else:
data.append(titles[0])
data.append(' ') #只有一个中文名字的,给外国名设为空
rating = re.findall(findRating, item)[0] # 获取影片评价
data.append(rating)
JudgeNum = re.findall(findJudge, item)[0] # 获取评价人数
data.append(JudgeNum)
Inq = re.findall(findInq, item) # 获取影片概况
if len(Inq) != 0:
Inq = Inq[0].replace("。", "") #去掉句号
data.append(Inq)
else:
data.append(" ") #没有影片概述的,留空
Body = re.findall(findBd, item)[0] # 获取影片相关内容
Body = re.sub(r'
Body = re.sub(r'/', '', Body) # 去掉/
data.append(Body.strip()) # 去掉前后的空格
datalist.append(data) # 将一部影片的信息加入总列表
return datalist
# 得到指定一个url的网页内容
def askURL(url):
'''用户代理,表示告诉豆瓣,我们是什么类型的机器'''
head = {
"user-agent":"Mozilla/5.0 (Windows NT 10.0;Win64;x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36",
}
request = urllib.request.Request(url, headers=head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode('utf-8')
# print(html)
except urllib.error.URLError as e:
print("出错了", e)
return html
if __name__ == "__main__":
main()
八、爬取结果,保存数据
1、Excel表的实例
import xlwt
workbook = xlwt.Workbook(encoding='utf-8') # 创建workbook对象
worksheet = workbook.add_sheet('sheet1') # 创建工作表表单
worksheet.write(0, 0, 'hello world') # 写入数据,第一个参数'行',第二个参数'列',第三个参数是内容
workbook.save('kaixin.xls') # 保存数据
2、爬取豆瓣电影Top250信息保存到表格中
#-*- coding:utf-8 -*-
#@Author: li Shang
#@Time: 2021/5/7 9:33
#@File: spider.py
#@Software: PyCharm
import urllib.request
import urllib.error
from bs4 import BeautifulSoup
import re
import xlwt
def main():
# global baseurl
baseurl = "https://movie.douban.com/top250?start="
datalist = getData(baseurl)
# for item in datalist:
# print(item)
savepath = "豆瓣电影Top250.xls"
saveData(datalist, savepath)
# 匹配影片详情链接的规则
findLink = re.compile(r'') # 创建正则表达式对象,表示规则或者字符串的模式
# 匹配影片图片的链接
findImSrc= re.compile(r'(.*?)')
# 匹配影片的评分
findRating = re.compile(r'')
# 评价人数
findJudge = re.compile(r'(\d*)人评价')
# 影片的概况
findInq = re.compile(r'(.*?)')
# 影片的相关内容
findBd = re.compile(r'(.*?)
', re.S)
def getData(baseurl):
'''爬取网页'''
datalist = []
j = 1
for i in range(0,10):
url = baseurl + str(i*25)
html = askURL(url)
# 逐一进行解析
soup = BeautifulSoup(html, "html.parser")
for item in soup.find_all("div",class_="item"):
# print(item)
data = []
item = str(item)
data.append(j)
link = re.findall(findLink, item)[0] # 获取影片详情链接
data.append(link)
imgSrc = re.findall(findImSrc, item)[0] # 获取图片
data.append(imgSrc)
titles = re.findall(findtitle, item) # 获取片名,片名可能只有中文的,没有英文的
if(len(titles) == 2):
ctitle = titles[0] #添加中文名
data.append(ctitle)
ftitle = titles[1].replace("/", "") #去掉斜杠,添加外国名
data.append(ftitle)
else:
data.append(titles[0])
data.append(' ') #只有一个中文名字的,给外国名设为空
rating = re.findall(findRating, item)[0] # 获取影片评分
data.append(rating)
JudgeNum = re.findall(findJudge, item)[0] # 获取评价人数
data.append(JudgeNum)
Inq = re.findall(findInq, item) # 获取影片概况
if len(Inq) != 0:
Inq = Inq[0].replace("。", "") #去掉句号
data.append(Inq)
else:
data.append(" ") #没有影片概述的,留空
Body = re.findall(findBd, item)[0] # 获取影片相关内容
Body = re.sub(r'
Body = re.sub(r'/', '', Body) # 去掉/
data.append(Body.strip()) # 去掉前后的空格
j = j+1
datalist.append(data) # 将一部影片的信息加入总列表
return datalist
def askURL(url):
'''得到指定一个url的网页内容'''
'''head 是用户代理,表示告诉豆瓣,我们是什么类型的机器'''
head = {
"user-agent":"Mozilla/5.0 (Windows NT 10.0;Win64;x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36",
}
request = urllib.request.Request(url, headers=head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode('utf-8')
# print(html)
except urllib.error.URLError as e:
print("出错了", e)
return html
def saveData(datalist, savepath):
'''保存数据'''
book = xlwt.Workbook(encoding='utf-8', style_compression=0) # 创建workbook对象
sheet = book.add_sheet('豆瓣电影Top250', cell_overwrite_ok=True) # 创建工作表表单
col = ('序号', '电影详情链接', '图片链接', '影片中文名', '影片外文名', '影片评分', '评价人数', '概况', '相关信息')
for i in range(0, 9):
sheet.write(0, i, col[i]) # 列名
for i in range(0, 250):
print("第%d条" %(i+1))
data = datalist[i]
for j in range(0, 9):
sheet.write(i+1, j, data[j]) # 数据内容
book.save(savepath) # 保存数据
if __name__ == "__main__":
main()
九、Sqlite模块操作
import sqlite3
# 1、连接数据库
# conn = sqlite3.connect("test.sqlite") # 打开或创建数据库文件
# print("打开数据库完毕")
# 2、创建表
# conn = sqlite3.connect("test.sqlite")
# c = conn.cursor() # 获取游标
#
# sql = '''
# create table company
# (id int primary key not null,
# name text not null,
# age int not null,
# address char(50),
# salary real);
# '''
#
# c.execute(sql) # 执行sql语句
# conn.commit() # 提交sql操作
# conn.close() # 关闭连接
# print("创建表完毕")
# 3、插入数据
# conn = sqlite3.connect("test.sqlite")
# c = conn.cursor() # 获取游标
#
# sql = '''
# insert into company (id, name, age, address, salary) VALUES (1, '项梅', 26, '安徽安庆', 10000);
# '''
#
# sql1 = '''
# insert into company (id, name, age, address, salary) VALUES (2, '凯欣', 25, '山东德州', 8000);
# '''
#
# c.execute(sql1) # 执行sql语句
# conn.commit() # 提交sql操作
# conn.close() # 关闭连接
# print("插入数据完毕")
# 4、查询数据
conn = sqlite3.connect("test.sqlite")
c = conn.cursor() # 获取游标
sql = '''
select * from company;
'''
cursor = c.execute(sql)
for i in cursor:
print(i)
conn.close() # 关闭连接
十、数据可视化
1、Flask入门
Flask诞生于2010年,是Armin ronacher(人名)用Python语言基于Werkzeug工具箱编写的轻量级Web开发框架。它主要面向需求简单的小应用。
Flask本身相当于一个内核,其他几乎所有的功能都要用到扩展(邮件扩展Flask-Mail,用户认证Flask-Login) ,都需要用第三方的扩展来实现。比如可以用Flask-extension加入ORM、窗体验证工具,文件上传、身份验证等。Flask没有默认使用的数据库,你可以选择MySQL,也可以用NoSQL。其WSGI工具箱采用Werkzeug(路由模块),模板引擎则使用Jinja2。
可以说Flask框架的核心就是**Werkzeug和Jinja2**。
Python最出名的框架要数Django,此外还有FlasR、Tornado等框架。虽然Flask不是最出名的框架,但是Flask应该算是最灵活的框架之一,这也是Flask受到广大开发者喜爱的原因。
Flask扩展包:
- Flask-SQLalchemy:操作数据库;
- Flask-migrate:管理迁移数据库;
- Flask-Mail:邮件;
- Flask-WTF:表单;
- Flask-script:插入脚本;
- Flask-Login:认证用户状态;
- Flask-RESTful:开发REST API的工具;
- Flask-bootstrap:集成前段Twitter Bootstrap框架;
- Flask-Moment:本地化日期和时间;
1.1、从helloword开始
项目结构:
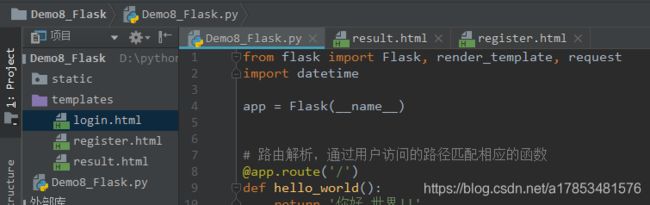
创建flask项目
from flask import Flask, render_template, request
import datetime
app = Flask(__name__)
# 路由解析,通过用户访问的路径匹配相应的函数
@app.route('/')
def hello_world():
return '你好 世界!!'
# 自定义另外的路径
@app.route('/index')
def index():
return 'Hello World!'
# 通过访问路径获取用户输入的字符串参数
@app.route('/user-' )
def user(name):
return '欢迎 %s 莅临指导' %name
# 通过访问路径获取用户输入的整形参数(数字)
@app.route('/user-' )
def user2(id):
return '你看的是 %d' %id
# 向页面传递一个变量
@app.route('/login')
def login():
time = datetime.date.today()
name = ["孙凯欣", "赵晓萌", "刘佳文", "郭晓琳"]
task = {
"任务":"扫地", "时间":"俩小时", "地点":"厕所"}
return render_template("login.html", time=time, name=name, task=task)
# 表单提交
@app.route('/test/register')
def register():
return render_template("register.html")
# 表单接收,接收表单提交的路由,必须指明可接受的类型
@app.route('/result', methods=['POST', 'GET'])
def result():
if request.method == 'POST':
result = request.form
return render_template("result.html", result=result )
if __name__ == '__main__':
app.run(debug=True)
其中要访问的login.html页面如下
DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Tomcat 7title>
<style>
body::before {
background: url(https://images.cnblogs.com/cnblogs_com/blogs/653554/galleries/1961436/o_2104140852061646268-20190709145111387-899901278.jpg) center/cover no-repeat;
}
body:before {
content: '';
background-repeat: no-repeat;
background-position: center;
opacity: 0.1;
position: fixed;
top: 0;
left: 0;
width: 100%;
height: 100%;
z-index: -1;
}
style>
head>
<body>
<p>欢迎光临p>
今天的时间是{
{ time }}<br/>
{% for i in name %}
<li>
{
{ i }}
li>
{% endfor %}<br/>
任务:<br/>
<table border="1" style="border: aqua">
{% for key,value in task.items() %}
<tr>
<td>{
{ key }}td>
<td>{
{ value }}td>
tr>
{% endfor %} }
table>
<div>
<script src="https://eqcn.ajz.miesnfu.com/wp-content/plugins/wp-3d-pony/live2dw/lib/L2Dwidget.min.js">script>
<script src="https://blog-static.cnblogs.com/files/blogs/653554/jquery-2.2.0.min.js">script>
<script>
L2Dwidget.init({
"model": {
"jsonPath": "https://unpkg.com/[email protected]/assets/koharu.model.json",
"scale": 1
},
"display": {
"position": "right", //看板娘的位置
"width": 60, //宽度
"height": 80, //高度
"hOffset": 5,
"vOffset": 5
},
"mobile": {
"show": true,
"scale": 0.5
},
"react": {
"opacityDefault": 0.7,
"opacityOnHover": 0.2
}
});
script>
<script src="https://blog-static.cnblogs.com/files/blogs/653554/mouse-click.js">script>
<canvas width="1777" height="841"
style="position: fixed; left: 0; top: 0; z-index: 2147483647; pointer-events: none;">canvas>
<script type="text/javascript" src="https://blog-static.cnblogs.com/files/blogs/653554/canvas-nest.min.js">script>
<link rel="stylesheet" href="https://blog-static.cnblogs.com/files/blogs/653554/APlayer.min.css">
<script src="https://blog-static.cnblogs.com/files/blogs/653554/APlayer.min.js">script>
<script src="https://blog-static.cnblogs.com/files/blogs/653554/Meting.min.js">script>
<div id="player" class="aplayer aplayer-withlist aplayer-fixed" data-id="2878443703" data-server="netease"
data-type="playlist" data-order="random" data-fixed="true" data-listfolded="true" data-theme="orange">div>
div>
body>
html>
其中要访问的register.html页面如下
DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Titletitle>
head>
<body>
{# <form action="http://localhost:5000/result" method="post">#}
<form action="{
{ url_for('result') }}" method="post">
<p>姓名:<input type="text" name="name">p>
<p>年龄:<input type="text" name="age">p>
<p>性别:<input type="text" name="gender">p>
<p>地址:<input type="text" name="adress">p>
<p><input type="submit" value="提交">p>
form>
body>
html>
其中要访问的result.html页面如下
DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Titletitle>
head>
<body>
刚才提交的信息:
<table border="1" style="border: aqua">
{% for key,value in result.items() %}
<tr>
<th>{
{ key }}th>
<td>{
{ value }}td>
tr>
{% endfor %} }
table>
body>
html>
2、Echarts应用
GitHub网址:https://github.com/apache/echarts/tree/master/dist
官网:https://echarts.apache.org/examples/zh/index.html
示例:用echarts来展示柱状图
DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>EChartstitle>
<script src="https://blog-static.cnblogs.com/files/blogs/653554/echarts.min.js">script>
head>
<body>
<div id="main" style="width: 600px;height:400px;">div>
<script type="text/javascript">
// 基于准备好的dom,初始化echarts实例
var myChart = echarts.init(document.getElementById('main'));
// 指定图表的配置项和数据
var option = {
title: {
text: 'ECharts 入门示例'
},
tooltip: {
},
legend: {
data:['销量']
},
xAxis: {
data: ["衬衫","羊毛衫","雪纺衫","裤子","高跟鞋","袜子"]
},
yAxis: {
},
series: [{
name: '销量',
type: 'bar',
data: [5, 20, 36, 10, 10, 20]
}]
};
// 使用刚指定的配置项和数据显示图表。
myChart.setOption(option);
script>
body>
html>
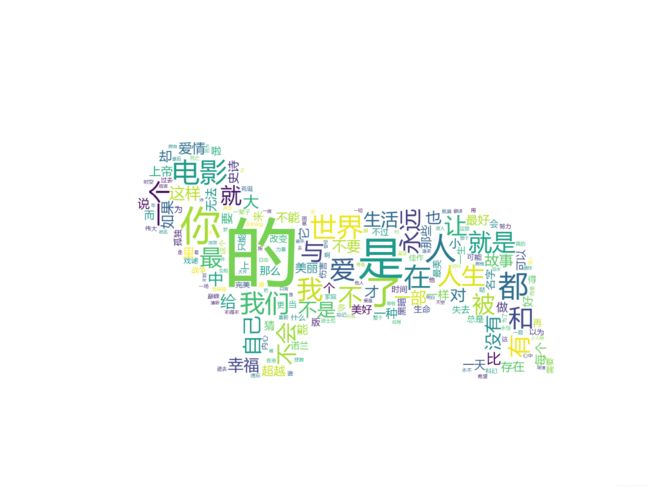
3、WordCloud应用
官网:http://amueller.github.io/word_cloud/auto_examples/single_word.html#sphx-glr-auto-examples-single-word-py
下载失败时可以试试非官方下载地址:https://www.lfd.uci.edu/~gohlke/pythonlibs/
#-*- coding:utf-8 -*-
import jieba # 分词
from matplotlib import pyplot as plt # 绘图,数据可视化
from wordcloud import WordCloud # 词云
from PIL import Image # 图片处理
import numpy as np # 矩阵运算
import sqlite3
def get_word():
'''获取需要展示的词语'''
con = sqlite3.connect("movie.sqlite")
cur = con.cursor()
sql = 'select one_hua from movie'
data = cur.execute(sql)
global text
text = ""
for item in data:
text = text + item[0]
cur.close()
con.close()
def fenci():
'''将获取的句子通过jieba库分成词语'''
global string
cut = jieba.cut(text)
string = ' '.join(cut)
# print(string)
def tu():
'''设置好图片'''
img = Image.open(r'dog.jpg') # 打开遮罩图片
img_arrag = np.array(img) # 将图片转化成数组
wc = WordCloud(
background_color='white',
mask=img_arrag,
font_path= 'C:\Windows\Fonts\msyh.ttc'
)
wc.generate_from_text(string)
fig = plt.figure(1)
plt.imshow(wc)
plt.axis('off') # 不显示坐标轴
# plt.show() # 显示输出的图片
plt.savefig(r'C:\Users\ThinkPad\Desktop\dogdog.png', dpi=800)
if __name__ == "__main__":
get_word()
fenci()
tu()
原图如下:

生成图如下: