列表、元组、字典、字符串、集合的使用、文件操作、字符编码和转码
变量的类型:
a=[1,2,3,4,···] ---列表
b=(1,2,3,4,···) ---元组
c={'name':'lishang','age':'23','sex':'man',···} ---字典
d='1,2,a,b,···' ---字符串
dasda ---集合
1、列表的操作(增、删、改、查)
names = ["LiShang","ZhaoXiaomeng","SunKaixin","tanke"]
print(names)
print(names[0]) #切片,取0的位置的元素
print(names[0:2]) #切片,左闭右开(要0的位置,不要2的位置),即取前两个
print(names[-1]) #切片,取倒数第一个元素
print(names[-2:]) #切片,取倒数第二个到最后
print(names[0:-1:2]) #切片,去全部的元素,每隔一个取一个,2是步长
print(names[::2]) #切片,与上一行的效果完全一样
names.append("Xiangmei") #添加Xiangmei到列表最后
print(names)
names.insert(1,"LiuMin") #添加LiuMin到下标为1的位置
names[2]="生前是个美人儿" #将下标为2的位置替换掉
print(names)
names.remove("tanke") #删除掉tanke
del names[4] #删除掉下标为4的位置的元素
names.pop() #pop删除,不加参数默认删除最后一个
names.pop(1) #加参数,删掉下标为1的位置的元素
print(names.index("SunKaixin")) #输出“SunKaixin”所在的下标位置(下标为3)
print(names.count("ZhaoXiaomeng")) #统计列表中“ZhaoXiaomeng”的数量(1个)
names.clear() #清空列表
print(names)
names.reverse() #反转列表(将列表元素顺序全部颠倒过来)
print(names)
names.sort() #排序(按照元素第一个,特殊符号→数字→大写字母→小写字母→中文)ASSIC码里的顺序
print(names)
names2=[1,2,3,4]
names.extend(names2) #将names2并入names,并且保留names2
print(names)
del names #删掉names列表
print('tanke' in names) #'tanke'是不是在names这个列表里,是返回True,否则返回False
--->
['LiShang', 'ZhaoXiaomeng', 'SunKaixin', 'tabke']
LiShang
['LiShang', 'ZhaoXiaomeng']
tanke
['SunKaixin', 'tanke']
['LiShang', 'ZhaoXiaomeng', 'SunKaixin', 'tanke', 'Xiangmei']
['LiShang', 'LiuMin', '生前是个美人儿', 'SunKaixin', 'tanke', 'Xiangmei']
['LiShang', 'LiuMin', '生前是个美人儿', 'SunKaixin', 'tanke']
3
1
[]
['tanke', 'SunKaixin', '生前是个美人儿', 'LiuMin', 'LiShang']
['LiShang', 'LiuMin', 'SunKaixin', 'tanke', '生前是个美人儿']
['LiShang', 'LiuMin', 'SunKaixin', 'tanke', '生前是个美人儿', 1, 2, 3, 4]
True
关于copy
1、names.copy — 浅copy,只复制第一层
names = ["LiShang","ZhaoXiaomeng","SunKaixin","tanke"]
names2 = names.copy() #复制names一份给names2
print(names)
print(names2)
names[1] = "赵晓萌"
names[2][0] = "LISHANG"
print(names)
print(names2)
--->
['LiShang', 'ZhaoXiaomeng', 'SunKaixin', 'tanke']
['LiShang', 'ZhaoXiaomeng', 'SunKaixin', 'tanke']
['LiShang', '赵晓萌', ['LISHANG', 'zhaoxiaomeng'], 'SunKaixin', 'tanke']
['LiShang', 'ZhaoXiaomeng', ['LISHANG', 'zhaoxiaomeng'], 'SunKaixin', 'tanke']
这种copy只是浅copy,names2与names公用一个内存地址,也就是更改names,names2也会改,并不完全独立
2、通过copy模块
import copy
names = ["LiShang","ZhaoXiaomeng",["lishang","zhaoxiaomeng"],"SunKaixin","tanke"]
#names2=copy.copy(names) #浅copy,这个copy与列表中的copy一样,也是浅copy
names2=copy.deepcopy(names) #深copy,复制完全独立的一份names给names2
print(names)
print(names2)
names[1] = "赵晓萌"
names[2][0] = "LISHANG"
print(names)
print(names2)
--->
导入copy模块之后,使用copy.copy方法与列表中的names.copy一样,是浅copy,names2并不是独立的
而使用copy.deepcopy就是深copy了,复制完全独立于names的列表names2
浅copy的三种方式:
person=['name',['a',100]]
p1=copy.copy(person)
p2=person[:]
p3=list(person)
p4=person.copy()
列表循环
for i in names:
print(i)
--->
LiShang
ZhaoXiaomeng
['LISHANG', 'zhaoxiaomeng']
SunKaixin
tanke
2、元组 (只读列表) 只能查,不能增删改,用小括号括起来
只有两种方法,count和index
names = ('LiShang','Zhaoxiaomeng')
print(names.count('LiShang')) #统计元组中出现的'LiShang'这个元素的次数
print(names.index('LiShang')) #返回元素'LIShang'的位置下标
--->
1
0
3、字典的操作—(字典是无序的)
#字典是key-vlaue的键值对
info = {
'stu1100':"MingRiHua QiLuo",
'stu1101':"TengLan Wu",
'stu1102':"LongZe LuoLa",
'stu1103':"DaQiao WeiJiu",
'stu1104':"ZaoYiNv LuYi"
}
print(info["stu1103"]) #字典是通过key来取值的(查找其中的元素)
info["stu1103"] = "大桥未久" #直接修改key='stu1103'的值,存在即修改
info["stu1105"] = "天海翼" #增加一个key='stu1105'的值,不存在即创建
del info["stu1101"] #删掉key='stu1101'的值
info.pop("stu1101") #删掉key='stu1101'的值
info.popitem() #随机删掉一个
print(info.get('stu1103')) #查找元素,key存在返回值,不存在返回None
print("stu1102" in info) #测试'stu1102'是否是字典的key,是返回True,否则返回False
--->
DaQiao WeiJiu
{
'stu1100': 'MingRiHua QiLuo', 'stu1101': 'TengLan Wu', 'stu1102': 'LongZe LuoLa', 'stu1103': '大桥未久', 'stu1104': 'ZaoYiNv LuYi'}
{
'stu1100': 'MingRiHua QiLuo', 'stu1101': 'TengLan Wu', 'stu1102': 'LongZe LuoLa', 'stu1103': '大桥未久', 'stu1104': 'ZaoYiNv LuYi', 'stu1105': '天海翼'}
{
'stu1100': 'MingRiHua QiLuo', 'stu1102': 'LongZe LuoLa', 'stu1103': '大桥未久', 'stu1104': 'ZaoYiNv LuYi', 'stu1105': '天海翼'}
{
'stu1100': 'MingRiHua QiLuo', 'stu1102': 'LongZe LuoLa', 'stu1103': '大桥未久', 'stu1104': 'ZaoYiNv LuYi', 'stu1105': '天海翼'}
{
'stu1100': 'MingRiHua QiLuo', 'stu1102': 'LongZe LuoLa', 'stu1103': '大桥未久', 'stu1104': 'ZaoYiNv LuYi'}
DaQiao WeiJiu
info = {
'stu1101':"MingRiHua QiLuo",
'stu1102':"DaQiao WeiJiu",
'stu1103':"ZaoYiNv LuYi"
}
print("stu1102" in info) #key='stu1102'存在就返回True,否则返回False
--->
True
多级字典嵌套
av_catalog = {
"欧美":{
"www.yourporn.com":["很多免费的,世界最大的","质量一般"],
"www.pornhub.com":["很多免费的,也很大","质量比yourporn高点"],
"letmedothisyou.com":["多是自拍,高质量图片多","资源不多,更新慢"],
"x-art.com":["质量很高,真的很高","全部收费,屌丝请绕路"]
},
"日韩":{
"tokyo-hot":["质量怎样不清楚,个人已经不喜欢日韩系列了","听说是收费的"]
},
"大陆":{
"1024":["全部免费,真好,好人一生平安","服务器在国外,更新慢"]
}
}
print(av_catalog)
av_catalog["大陆"]["1024"][1] = "能在国内做镜像就好了" #更改key='大陆'中key='1024'的下标为1的元素内容
print(av_catalog.get("大陆")) #取出key='大陆'的值的value内容
print(av_catalog.values()) #取出全部的values
print(av_catalog.keys()) #取出全部的key
av_catalog.setdefault("taiwan",{
"www.baidu.com":[1,2]}) #若key='taiwan'存在就返回之前的,不存在则创建新的
print(av_catalog) #输出字典
--->
{
'欧美': {
'www.yourporn.com': ['很多免费的,世界最大的', '质量一般'], 'www.pornhub.com': ['很多免费的,也很大', '质量比yourporn高点'], 'letmedothisyou.com': ['多是自拍,高质量图片多', '资源不多,更新慢'], 'x-art.com': ['质量很高,真的很高', '全部收费,屌丝请绕路']}, '日韩': {
'tokyo-hot': ['质量怎样不清楚,个人已经不喜欢日韩系列了', '听说是收费的']}, '大陆': {
'1024': ['全部免费,真好,好人一生平安', '服务器在国外,更新慢']}}
{
'1024': ['全部免费,真好,好人一生平安', '能在国内做镜像就好了']}
dict_values([{
'www.yourporn.com': ['很多免费的,世界最大的', '质量一般'], 'www.pornhub.com': ['很多免费的,也很大', '质量比yourporn高点'], 'letmedothisyou.com': ['多是自拍,高质量图片多', '资源不多,更新慢'], 'x-art.com': ['质量很高,真的很高', '全部收费,屌丝请绕路']}, {
'tokyo-hot': ['质量怎样不清楚,个人已经不喜欢日韩系列了', '听说是收费的']}, {
'1024': ['全部免费,真好,好人一生平安', '能在国内做镜像就好了']}])
dict_keys(['欧美', '日韩', '大陆'])
{
'欧美': {
'www.yourporn.com': ['很多免费的,世界最大的', '质量一般'], 'www.pornhub.com': ['很多免费的,也很大', '质量比yourporn高点'], 'letmedothisyou.com': ['多是自拍,高质量图片多', '资源不多,更新慢'], 'x-art.com': ['质量很高,真的很高', '全部收费,屌丝请绕路']}, '日韩': {
'tokyo-hot': ['质量怎样不清楚,个人已经不喜欢日韩系列了', '听说是收费的']}, '大陆': {
'1024': ['全部免费,真好,好人一生平安', '能在国内做镜像就好了']}, 'taiwan': {
'www.baidu.com': [1, 2]}}
info = {
'stu1101':"LongZe LuoLa",
'stu1102':"DaQiao WeiJiu",
'stu1103':"ZaoYiNv LuYi"
}
b = {
"stu1101":"lishang",
1:3,
2:4
}
info.update(b) #两个字典合并,key相同的,value=字典b中的值,不同的则添加
print(info)
print(info.items()) #将字典转换成列表,列表由一个个元组组成,每个元组又由初始字典的key和valus构成
c = dict.fromkeys([5,6,7],"lishang") #初始化一个新的字典,key分别为5,6,7;值全部为'lishang'
print(c)
--->
{
'stu1101': 'lishang', 'stu1102': 'DaQiao WeiJiu', 'stu1103': 'ZaoYiNv LuYi', 1: 3, 2: 4}
dict_items([('stu1101', 'lishang'), ('stu1102', 'DaQiao WeiJiu'), ('stu1103', 'ZaoYiNv LuYi'), (1, 3), (2, 4)])
{
5: 'lishang', 6: 'lishang', 7: 'lishang'}
字典循环
info = {
'stu1101':"LongZe LuoLa",
'stu1102':"DaQiao WeiJiu",
'stu1103':"ZaoYiNv LuYi"
}
for i in info:
print(i,info[i])
--->
stu1101 LongZe LuoLa
stu1102 DaQiao WeiJiu
stu1103 ZaoYiNv LuYi
还有一种循环方法:
for k,v in info.items(): #效果完全一样,但效率较低,多了将字典转成列表的过程
print(k,v)
--->
stu1101 LongZe LuoLa
stu1102 DaQiao WeiJiu
stu1103 ZaoYiNv LuYi
4、字符串的操作
name = "my \tname is lishang"
print(name.expandtabs(tabsize=30)) #tab键的位置补全30个空格
--->
my name is lishang
name = "my name is lishang"
print(name.capitalize()) #首字母大写
print(name.count("a")) #统计字符串中'a'的个数
print(name.center(50,"-")) #字符串在中间,两端用'-'补全,凑齐50个字符
print(name.endswith("ng")) #判断是否以'ng'结尾,是的话返回Ture
print(name.find("name")) #查找'name',返回下标
print(name[name.find("name"):]) #find延伸,字符串切片,与列表一致
--->
My name is lishang
2
----------------my name is lishang----------------
True
3
name is lishang
name = "my name is {name} and I am {age} years old"
print(name.format(name='lishang',age='22'))
print(name.format_map( {
'name':'lishang','age':'22'} ))
print(name.isalnum()) #是否只有阿拉伯数字和字母
print('adb123'.isalnum()) #是否只有阿拉伯数字和字母
print('adaDSA'.isalpha()) #是否为字母,包含大写字母
print('16B'.isdecimal()) #是否为十进制
print('812'.isdigit()) #是否为整数数字
print('a 1A'.isidentifier()) #是不是一个合法的标识符(变量名)
print('aaSS'.islower()) #是不是小写
print(' '.isspace()) #是不是空格
print('My Name Is Zhaoxiaomeng'.istitle()) #是不是标题(每个词首字母大写)
print('ada'.isprintable()) #是不是可打印的,tty文件就无法打印
print('daAA'.isupper()) #是不是全为大写
--->
my name is lishang and I am 22 years old
my name is lishang and I am 22 years old
False #name中有空格还有{
}符号,为False
True #'adb123'只包含数字和字母,为True
True #'adaDSA'只包含字母,为True
False #'16B'是16进制数字,为False
True #'812'是整数,为True
False #'a 1A'包含空格,为False
False #包含大写,为False
True 是空格,返回真
True #每个单词首字母大写,返回真
True #字符串这种肯定为真,向终端设备/dev/1等为False
False #'daAA'不是全为大写,返回False
name = "my name is {name} and I am {age} years old"
print('+'.join(['1','2','3'])) #列表变成字符串,前面是间隔符
print(name.ljust(50,'*')) #长度为50,不够用'*'补全,字符靠左
print(name.rjust(50,'*')) #长度为50,不够用'*'补全,字符靠右
print('ZhaoXiaomeng'.lower()) #将大写字母变为小写
print('ZhaoXiaomeng'.upper()) #将小写字母变为大写
print('\nlishang'.lstrip()) #去掉字符串左边的空格和换行
print('lishang\n'.rstrip()) #去掉字符串右边的空格和换行
print('\nlishang\n'.strip()) #去掉字符串两边的空格和换行
--->
1+2+3 #列表[1,2,3]变成字符串,用'+'间隔
my name is {
name} and I am {
age} years old********
********my name is {
name} and I am {
age} years old
zhaoxiaomeng
ZHAOXIAOMENG
lishang
lishang
lishang
随机密码生成
p = str.maketrans("abcdefgh",'12345678')
print("li shang".translate(p))
--->
li s81n7 #只有在maketrans("abcdefgh",'12345678')中对应的元素会改变
name = "my name is {name} and I am {age} years old"
print('qqq123'.replace('q','Q',2)) #替换(将'q'替换为'Q',替换前两个)
print('lin shang'.rfind('n')) #与find一样,找到最右边的'n',返回下标
print('li shang girl friend is zhao xiaomeng'.rsplit(' ')) #将字符串变成列表,rsplit('分隔符')
print('li\nsh\nang'.splitlines()) #字符串分成列表,按照换行符分隔
print('12345asdf6789'.startswith('asdf',5,9)) #在下标为5-9(不包含9)之间,是否以'asdf'开头
print('Li Shang'.swapcase()) #大小写互换
print('li shang'.title()) #变成标题,首字母大写
print('li shang'.zfill(50)) #在前面用'0'补位,补够50位
--->
QQq123
7
['li', 'shang', 'girl', 'friend', 'is', 'zhao', 'xiaomeng']
['li', 'sh', 'ang']
True
lI sHANG
Li Shang
000000000000000000000000000000000000000000li shang
5、集合(无序的,不重复的数据组合)
1、去重,把一个列表变成集合,就自动去重了
2、关系测试,测试两组数据之间的交集、差集、并集等关系
list_1= [1,4,5,7,3,6,7,9,1]
list_1 = set(list_1) #set将列表变成集合
print(list_1,type(list_1))
list_2 = set([2,6,0,66,22,8,4])
list_3 = {
1,5,9}
print(list_1.intersection( list_2)) #取出list_1和list_2的交集
print(list_1.union(list_2)) #取并集
print(list_1.difference(list_2)) #差集,list_1减去list_2
print(list_2.difference(list_1)) #差集,list_2减去list_1
print(list_1.issubset(list_2)) #list_1是list_2的子集吗?True or False
print(list_3.issubset(list_1)) #list_3是list_1的子集吗?True or False
print(list_1.issuperset(list_3)) #list_1是list_3的父集吗
print(list_1.symmetric_difference(list_2)) #对称差集,俩集合的全集去掉交集
print(list_2.isdisjoint(list_3)) #若俩集合无交集,返回True
--->
{
1, 3, 4, 5, 6, 7, 9} <class 'set'> #将列表list_1变成集合输出,还有类型
{
4, 6} #交集
{
0, 1, 2, 3, 4, 5, 6, 7, 66, 9, 8, 22} #并集
{
1, 3, 5, 7, 9} #list_1去掉两个集合重复的
{
0, 2, 66, 8, 22} #list_2去掉两个集合重复的
False #list_1不是list_2的子集
True #list_3是list_1的子集
True #list_1是list_3的父集
{
0, 1, 2, 66, 3, 5, 8, 7, 9, 22} #俩集合的全部去掉都有的
True
也可以用运算符来祖宗关系测试:
a = t | s #并集
a = t & s #交集
a = t - s #差集(在t中,但不在s中)
a = t ^ s #对称差集(在t中或者在s中,但不在两者的交集中)
集合的基本操作
list_1= [1,4,5,7,3,6,7,9,1]
list_1 = set(list_1) #set将列表变成集合
list_1.add(999) #添加一项
list_1.update([10,11,12]) #添加多项
print(list_1)
list_1.remove(12) #删除一项,若删的元素不存在,会报错
print(list_1)
print(len(list_1)) #集合的长度
list_1.pop() #pop随机删一个
print(list_1)
print(list_1.discard('sadad')) #删除一项,若删的元素不存在,返回None,不报错
--->
{
1, 3, 4, 5, 6, 7, 999, 9}
{
1, 3, 4, 5, 6, 7, 999, 9, 10, 11, 12}
{
1, 3, 4, 5, 6, 7, 999, 9, 10, 11}
10
{
3, 4, 5, 6, 7, 999, 9, 10, 11} #随机删掉一个
None #要删的元素不存在,返回False
6、文件操作
f.readlines把内容读到内存里,只适合小文件
f = open("yesterday",'r',encoding = "utf-8") #'r'以读的方式打开,不写默认为'r'
data = f.read() #读取文件的内容
print(data) #输出
print(f.readline()) #只读取第一行,并输出
for line in f.readlines(): #readlines()是生成列表,元素是每一行内容
print(line.strip()) #输出每一行,strip()取出左右的空格和换行
'w’方式打开,但是会创建一个新的,若原来有,会覆盖掉,千万注意
f = open("yesterday",'w',encoding = "utf-8") #'w'以写的方式打开,但是会创建新的,覆盖原来的
--->cat yesterday
为空
打开文件时,最好打开一个新的文件
f = open("yesterday2",'w',encoding = "utf-8")
f.write("我爱北京天安门\n") #f.write("qaq") 往文件里写入qaq
f.write("天安门上太阳升\n")
--->cat yesterday2
我爱北京天安门
天安门上太阳升
还有一种方式’a’,追加写的方式,不会覆盖原来的内容
f = open("yesterday2",'a',encoding = "utf-8")
f.write("我爱北京天安门,\n")
f.write("天安门上太阳升.\n")
--->cat yesterday2
我爱北京天安门,
天安门上太阳升.
我爱北京天安门,
天安门上太阳升.
每次读一行,第10行不输出,输出一个分割符的标识
for index,line in enumerate(f.readlines()):
if index == 9:
print("-----------分隔线-------------")
continue
print(line.strip())
换一种方式,读取一行输出后,然后在内存里删掉
f = open("yesterday",'r',encoding = "utf-8") #yesterday中存着一首歌曲
#此时f变成了一个称之为迭代器的东西
for i in f:
print(i)
f.tell()—显示光标位置
f = open("yesterday",'r',encoding = "utf-8")
print(f.tell()) #tell会计数光标指针的位置
print(f.read(5)) #读前5个字符
print(f.tell())
--->
0 #初始位置在一开始,为0
When #读前5个字符,输出
5 #读取完5个字符之后,再查光标的位置,为5
----------------------------"华丽的分割线"------------------------------------
f = open("yesterday",'r',encoding = "utf-8")
print(f.tell()) #初始光标位置
print(f.readline()) #读取一行
print(f.readline()) #再读取一行
print(f.readline()) #在读取一行
print(f.tell()) #读取三行之后再显示光标位置
--->
0 #初始光标位置为0
When I was young #第一行内容
当我小时候 #第二行内容
I'd listen to the radio #第三行内容
60 #读完三行之后的光标位置
f.seek(0) #f.seek(0)将光标返回至开头0的位置
print(f.readline()) #再次输出
print(f.tell()) #光标位置
--->
When I was young #这时候一查,已经是第一行的内容了
18 #读取完第一行之后,光标是18了
----------------------------"华丽的分割线"------------------------------------
print(f.encoding) #打印当前文件编码
print(f.fileno()) #操作系统打开文件的接口的编号
print(f.name) #打印文件名字
print(f.isatty()) #是否是终端设备
print(f.readable()) #是否可读
print(f.writable()) #是否可写
f.flush() #实时刷新到硬盘上
f.truncate(20) #截断,从光标位置为0开始截取到20
--->
utf-8 #utf-8编码
3 #编号是3
yesterday #文件名为yesterday
False #不是终端设备
True #因为以读的方式打开的文件,所以可读
False #因为以读的方式打开的文件,所以不可写
我爱北京天安 #只保留了20个字符,其他删掉
修改文件,既能读又能写
f = open("yesterday",'r+',encoding = "utf-8") #'r+' 读写的方式打开,只在最后追加写
f = open("yesterday",'w+',encoding = "utf-8") #'w+' 写读的模式打开,打开文件读、追加写
f = open("yesterday",'a+',encoding = "utf-8") #'a+' 追加写读的模式打开,在文件后追加写,可读
f = open("yesterday",'rb') #'rb' 读二进制文件(视频、音频等),无编码
print(f.readline()) #在网络传输中,用'rb'二进制格式
f = open("yesterday",'wb') #'wb' 写二进制文件
f.write("Hello World\n".encode(encoding="utf-8")) #将字符串编码成二进制写入
--->
b'---------diao------------1\r\n' #二进制文件读取,开头带着b(byte),结尾的\n变成\r\n
yesterday
陌上花开,可缓缓归矣。(钱缪)
因为这一句甜美的情话,钱王缪和钱王妃的爱情,成为了千古绝唱。
后来春雨落汴京,只君一人雨中停。(黄仁宇)
情人眼里出西施,情人眼里也自动pass掉别人,从此,雨落汴京,三千繁华,就只剩下一个你,一个在我眼中永远不变的你。
你说,我们就山居于此吧,胭脂用尽时,桃花就开了。(与谢野晶子)
这是我读过的最甜最美的情话,没有之一。有诗意也有韵味,百读不厌,唇齿留香。
对一个文件修改部分内容,将内容写到新文件,不修改原文件
f = open("yesterday2",'r',encoding="utf-8") #读原文件
f_new = open("yesterday2.bak",'w',encoding="utf-8") #创建新文件
for line in f: #循环旧文件
if "钱王缪和钱王妃的爱情" in line: #找到要修改的字段
line = line.replace("钱王缪和钱王妃的爱情","李尚和赵晓萌的爱情") #文字替换
f_new.write(line) #是不是匹配都写入新文件
f.close() #关闭两个文件
f_new.close()
将写死的内容改为执行脚本传参数的方式
import sys
f = open("yesterday2",'r',encoding="utf-8") #读原文件
f_new = open("yesterday2.bak",'w',encoding="utf-8") #创建新文件
find_str = sys.argv[1] #查找的内容
replace_str = sys.argv[2] #要替换的内容
for line in f: #循环旧文件
if find_str in line: #找到要修改的字段
line = line.replace(find_str,replace_str) #文字替换
f_new.write(line) #是不是匹配都写入新文件
f.close() #关闭两个文件
f_new.close()
with语句
为了避免打开文件后忘记关闭,可以通过管理上下文,即:
with open("yesterday2.bak",'r',encoding="utf-8") as f: #with执行完毕之后,文件就关闭了
for line in f:
print(line)
****************并且支持同时打开多个文件****************将两个文件分到两行里写,更清晰
with open('log1') as obj1,\
open('log2') as obj2:
pass
进度条
import sys,time
for i in range(30):
sys.stdout.write("#")
sys.stdout.flush()
time.sleep(0.2)
7、字符编码和转码
python3默认关键点:
#1、在python3中,默认输入就是'unicode'编码,所以可直接对字符串进行编码,如:
#1、在python3中,decode解码时()里要声明原来的编码集,默认全都解码成unicode;decode时()里要声明转成什么样的编码集
#3、在python3中,encode时不但转了编码还变为了byte类型,再decode时就又转回了字符串
s = '李尚' #此时s就是'unicode'编码的
print(s)
print(s.encode("gbk")) #将s编码成'gbk'
print(s.encode("utf-8")) #将s编码成'utf-8'
print(s.encode("utf-8").decode("utf-8").encode("gb2312")) #转成'utf-8'再转成'gb2312'
print(s.encode("utf-8").decode("utf-8").encode("gb2312").decode("gb2312")) #再解码一次就显示中文了
--->
李尚
b'\xc0\xee\xc9\xd0' #'gbk'编码,向下兼容'gb2312'
b'\xe6\x9d\x8e\xe5\xb0\x9a' #'utf-8'编码
b'\xc0\xee\xc9\xd0' #'gb2312'编码与'gbk'一样,被'gbk'兼容
李尚
#查看系统默认编码
import sys
print (sys.getdefaultencoding())
--->
ascii
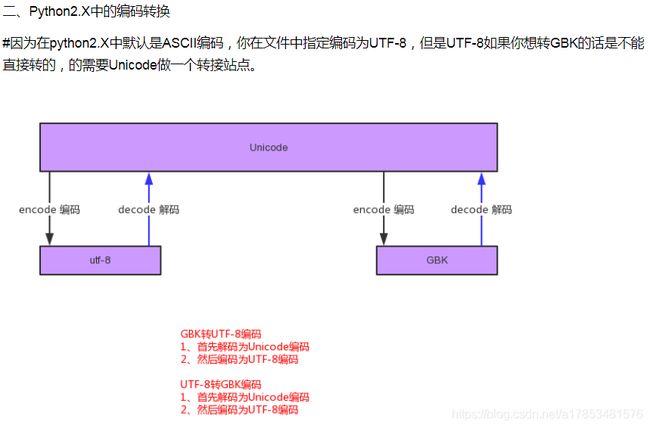
#将utf-8编码的字符转成gbk编码的字符(utf-8–>unicode–>gbk)-------python2
#-*- coding:utf-8 -*-
s = "你好"
#s = u"你好" #如果这样写,s就已经是'unicode'了,下面就不需要解码了
s_to_unicode = s.decode("utf-8") #将'utf-8'先解码成为'unicode'
print(s_to_unicode)
s_to_gbk = s_to_unicode.encode("gbk") #将'unicode'再编码成为'gbk'
print(s_to_gbk)
--->
你好
ţº
#将gbk编码的字符转成utf-8编码的字符(gbk–>unicode–>utf-8)-------python2
#-*- coding:gbk -*-
s = "你好"
gbk_to_utf8 = s.decode("gbk").encode("utf-8")
print(gbk_to_utf8)
--->
你好
如果是python3呢,开头不需要声明编码集了,python3默认就是unicode编码了
s = "你好" #python3里,默认就是'unicode'编码了,不需要再解码
s_to_gbk = s .encode("gbk") #直接编码成为'gbk'就OK了
print(s_to_gbk)
--->
s = '李尚'
print(s)
s_to_gbk = s.encode("gbk") #默认为utf-8,转成gbk
print(s_to_gbk)
print(s.encode()) #转成utf-8的字节形式
gbk_to_utf8 = s_to_gbk.decode("gbk").encode("utf-8") #将gbk再转成utf-8,与前一行输出一致
print(gbk_to_utf8)
--->
李尚
b'\xc0\xee\xc9\xd0'
b'\xe6\x9d\x8e\xe5\xb0\x9a'
b'\xe6\x9d\x8e\xe5\xb0\x9a'
#!/usr/bin/env python
#-*- coding:utf-8 -*-
#author lishang
import chardet
tim = '你好'
print chardet.detect(tim)
#先解码为Unicode编码,然后在从Unicode编码为GBK
new_tim = tim.decode('UTF-8').encode('GBK') #'UTF-8'是声明之前的编码是utf-8,decode一下,就解码成为unicode,然后再encode编码一下,编码成为'GBK'
print chardet.detect(new_tim)
#结果
'''
{
'confidence': 0.75249999999999995, 'encoding': 'utf-8'}
{
'confidence': 0.35982121203616341, 'encoding': 'TIS-620'}
'''