*本文数据从猿辅导爬取,爬取工具为BeautifulSoup+jupyter notebook,共爬取课程条数1615个。(截至2018.10.18)
前言
本文以猿辅导为案例进行数据分析的第一篇文章,主要介绍数据分析的目标以及数据爬取的过程。希望通过本文和大家分享数据分析的一些方法,欢迎和我沟通交流。
还是先上图:
可以看到,数据分析主要分为四个步骤:明确目标、获取数据、数据处理以及数据展示。根据不同的场景,有些时候还可能会需要构建模型,或者有些人还会把数据处理分成观察数据和数据清洗。这里不多讨论。
概述
本文将从以上几个部分整理本次数据分析的过程。
涉及知识点:结构化思维、描述性分析、相关性分析、python爬虫、数据清洗、mysql、数据可视化等。
第一部分:明确目标
明确目标是第一步也是最关键的一步,要做到“如何将一个命题转化拆分为一个可用数据分析的问题”。首先我们来问三个问题吧:
问1:为什么要分析一家教育行业的公司,能解决什么问题?
答:通过对教育行业中一家企业的分析,可以对行业现状有一定的了解。同时对当前该公司课程销售和教师队伍的分析,可以加强对教育行业的理解以及对在线教育发展的理解。
问2:要解决这些问题能否借助数据分析?
答:数据分析是一个很好的方法,可以对“猿辅导的课程情况”进行拆解:课程、老师、报名情况、价格、年级等等。当然更深层的分析还需要行业经验的支持。
问3:为什么选择“猿辅导”,从哪些方面考虑?
答:我是从一下几个方面考虑的:
1、课程重点突出
相对于沪江网等课程繁多的网站,猿辅导主要面向k12人群,定位比较清晰。
2、成立时间
猿辅导成立于2012年,目前已融资到E轮。属于独角兽企业,有一定示范意义。
3、数据爬取方便
市面上部分教育行业的网站课程内容少,而猿辅导的网站内容比较清晰(如图):
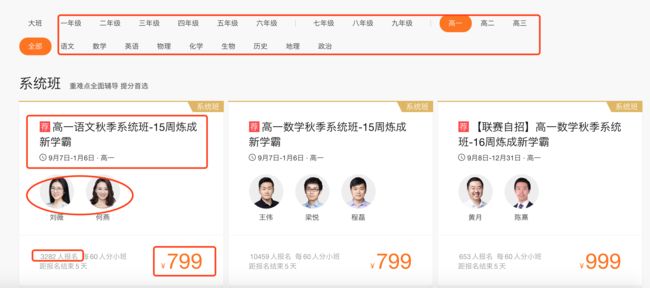
可见,猿辅导的网站结构化程度较好,数据比较容易爬取。
明确目标之后,还需要做的一件事情就是通过描述性分析和相关性分析建立起对获取数据的初步思考:
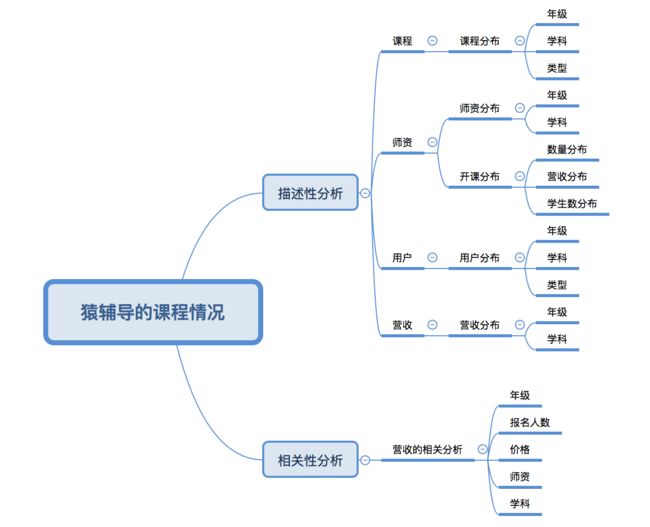
第二部分:数据获取
通过第一部分的整理我们已经有一定的对于获取哪些数据的概念了,下面就要具体来看一下了:
一、观察网页
正如前文所述,我们可以爬取每个课程的名称、年级、老师、报名人数、价格等信息。不过需要注意以下几点:
1、课程的分类依靠的是网址的不同,且每个年级下会有系统班、专题班等不同类型。
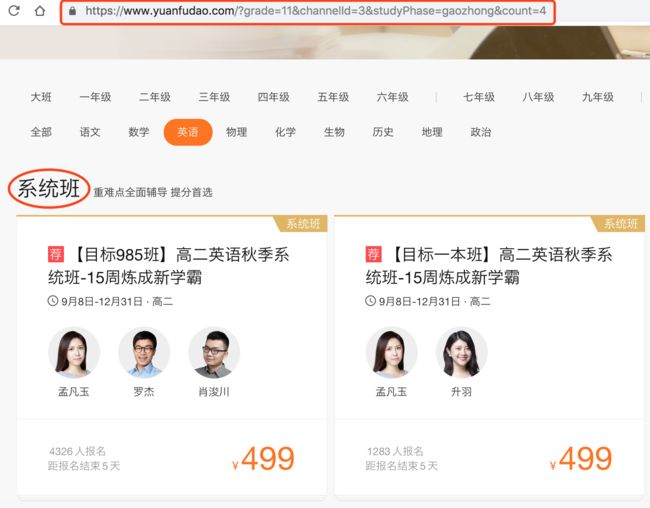
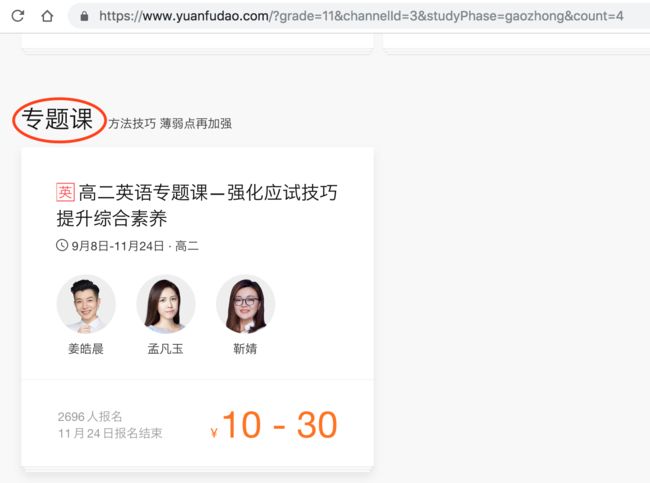
2、对于系统班,往往需要下钻一层获取该系统班下的每个课程信息
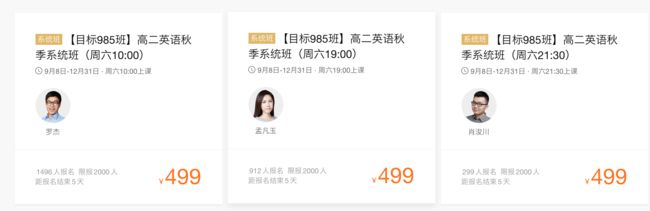
3、每个课程页面有细微的不同,在爬取时也要注意


二、爬虫层级结构
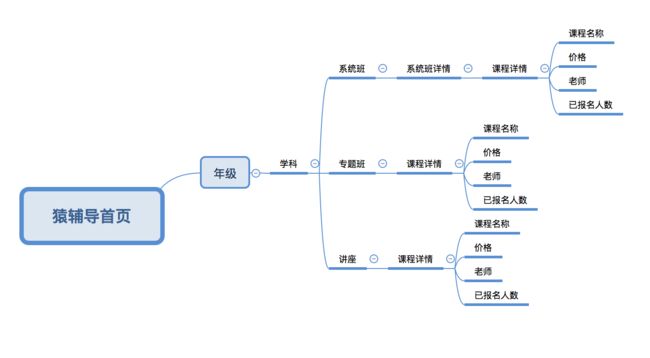
看一下网站的结构可能就更清晰了:
三、爬虫思路
根据上面的网站结构可以知道:
1、课程有三种类型,其中系统课多一层,因此系统课和专题/讲座的爬取可以分开;
2、年级学科是递进关系,可以使用for循环获取;
3、课程详情页面包含课程信息和教师信息,由于一个课程有可能有不止一位老师,可能导致主键的混乱,因此可以考虑分成课程表和教师表。
因此,最终我的爬虫代码分为三部分:
1、存放从首页获取的所有课程的课程id以及年级、学科等信息的课程表
2、从每个课程页面获取的课程详细信息如课程价格、报名人数等
3、从每个课程页面获取的教师详细信息如教师id、名字等
四、爬虫代码
说了那么多,具体的代码是什么样的呢?为了节省时间,我在关键的代码上面添加了备注。首先简单介绍一下我本次使用的爬虫方法:BeautifulSoup方法。
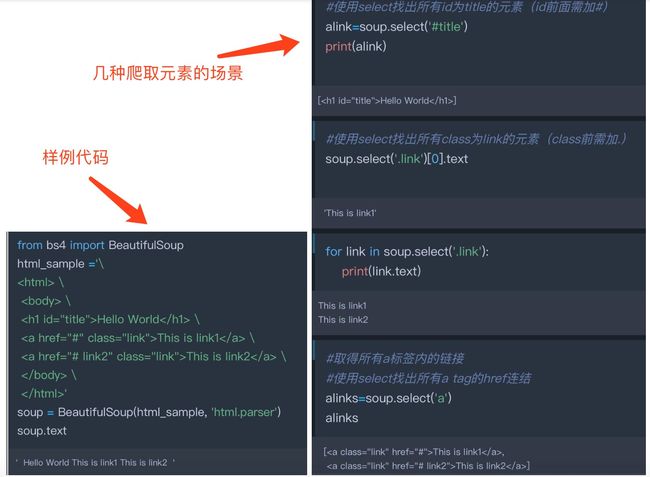
可以看出,在操作上只需要对不同类型的元素采用不同的标志即可爬取,方法简单容易上手。同时支持for循环,之后案例代码中也会提到。
再简单介绍一下如何观察网站:
如图所示,在Chrome浏览器中点“检查”后,可以得到类似上图的前端代码,通过观察元素、确定元素位置、确定元素路径可以定位到我们需要爬取到元素。
下面我们就重点分析一下爬虫的代码吧。根据上面的计划,爬虫代码也分为三部分:
1、爬取所有课程的概览信息
字段包括:studyphase(学段:小学、初中、高中)、grade(年级:1-12)、channelid(课程类型:语文、数学。。。)、groupid(系统课id)、groupname(系统课名称)、groupurl(系统课网址)、lessonid(课程id)、lessonname(课程名称)、lessonurl(课程url)。其中,lessonid为主键。
这一部分内容较多,因此在实际操作中我将爬虫程序分成几个部分编写:
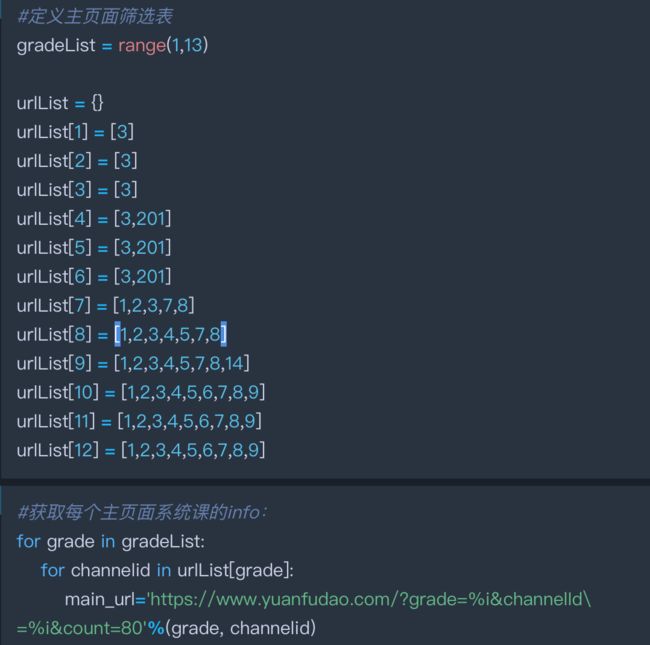
1.1 首先是获取首页上所有可能的URL组合:
通过观察网站我们可以知道,猿辅导的首页课程页可以分成“小学、初中、高中”、“一年级到高三”、“语文、数学到编程”三个部分。因此可以用下面代码获取所有URL组合:
1.2 获取首页下系统课的group名、groupid、groupurl:
因为上文提到过,系统课和专题/讲座课的层级不同,因此需要分开处理。
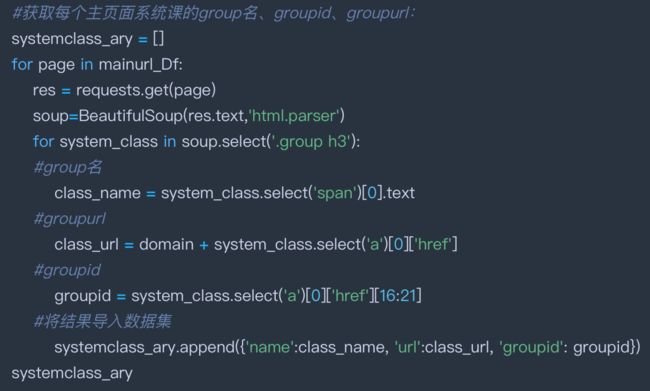
1.3 对每个groupurl下的页面提取lessonid、lesson名、lessonurl:

1.4 对专题/讲座类课程做类似的操作
注意要判断是否为讲座类。

2、爬取每个课程页面的课程详细信息
字段包括:lessen_id(课程id)、price(课程价格)、signup_number(报名人数)。其中,lesson_id为主键。
由于上面一部分已经将课程名称取出,这一部分只需要根据课程URL获取课程价格和报名人数即可:

但是由于猿辅导的课程页面有不同情况,比如:


因此在实际爬取时要做一个if判断:

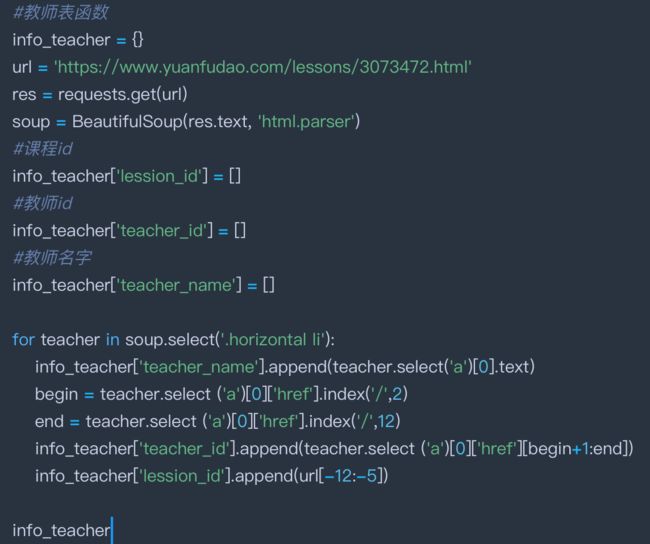
3、爬取每个课程页面的教师详细信息
字段包括:lessen_id(课程id)、teacher_id(课程价格)、teacher_name(老师名字)。其中,teacher_id为主键。
同样的道理,我们先对某一页面的教师情况做爬取测试:
五、爬取结果
讲上述程序重新组织一下就可以得到我们的最终爬虫代码了,这里不方便录入,有兴趣的小伙伴可以去我的知乎文章查看。
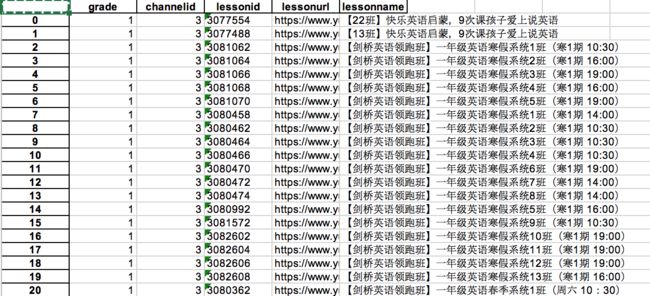
爬取结果如下:
all_lesson表(清洗前),共1615条记录。
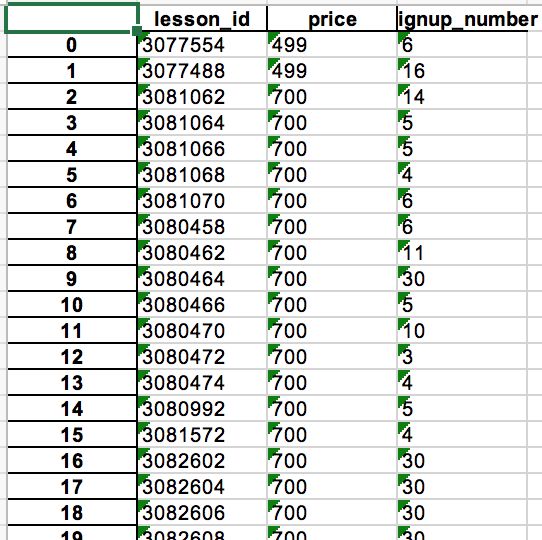
lesson_detail表(清洗前),共1615条记录。
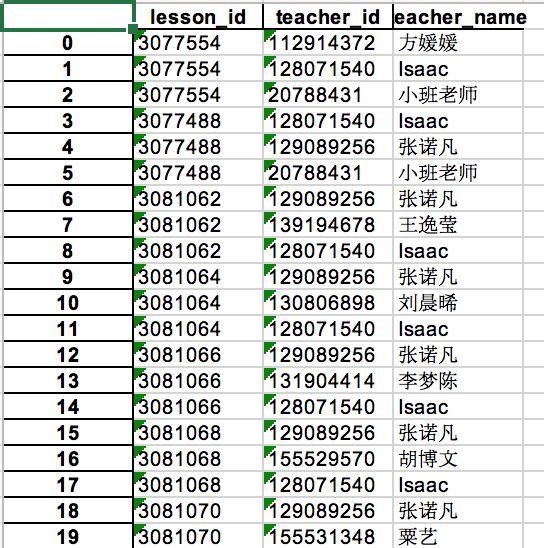
teacher_detail表(清洗前),共1915条记录(考虑到一门课有多名老师的情况)。
小结
本篇文章主要讨论了对猿辅导进行数据分析的目标和数据获取的方法。在确定目标时利用描述性分析和相关性分析确定应当获取的数据,获取数据则利用结构化思维对网站的数据结构进行了整理,并根据整理情况设计和实现了python爬虫。
最后,特别鸣谢:如何用数据分析方法剖析“猿辅导”K12课程