一、NLP分类:
1.word level:序列标注任务:分词、词性标注、命名实体识别
2.sentence level :在句子层面分类的任务:如文本分类,情感识别,关系抽取,语音情感识别等。
3.entence-sentence level:序列和序列之间的分类,这种分类根据分类形式的不同又可以细分。如机器翻译,问答,对话都是sequence to sequence类型的问题。
二、语言模型与词向量
语言模型就是用来判断一个句子的合理性的置信度,最经典的就是n-gram语言模型和NNLM(Nerual Network Language Model)
1.n-gram语言模型
n-gram语音模型主要基于马尔科夫假设。理论上,n越大越好。但实践中常用unigram、bigram和trigram,n越大训练越慢,但精度会更高。

2.神经语言模型
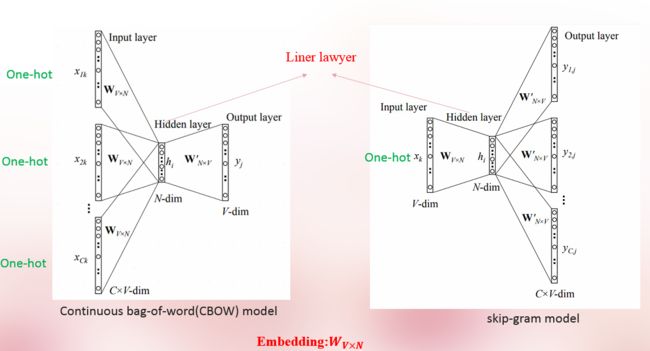
Word2vec就是利用一个简化版的语言模型来得到刚才提到的矩阵C,因为Hidden layer都是线性层。
CBOW利用一个词的上下文来预测中心词,skip-gram则是反过来利用中心词来预测上下文。
不同点:构建目标函数的方式不同。
CBOW: 根据词语上下文预测中心词
Skip-gram: 根据中心词预测上下文
共同点:以小窗粒度捕获词语与上下文的联系,然后滑动小窗,在整个语料上捕获联系。
思路:制定目标函数,量化这种联系,最优化,从而求得每个词的向量。
三、分词技术
分词任务,难点如下:
1.新词发现
未登录词(人名、机构名、商标名、公司名称)
2.词典与算法优先级
我们 中信 仰 佛教 的 人
3.歧义(颗粒度、交集等)
股份 有限公司 、郑州天和服装厂
分词的算法大致分为两种:
1.基于词典的分词算法
正向最大匹配算法 逆向最大匹配算法 双向匹配分词法
2.基于统计的机器学习算法
HMM、CRF、SVM、LSTM+CRF
Jieba的分词的API:
segWords_allmode = jieba.cut(str,cut_all=True) 全模式分词结果
segWords_accuratemode = jieba.cut(str,cut_all=False)精确模式分词结果
segWords_defaultmode = jieba.cut(str)默认模式分词结果
segWords_searchenginemode = jieba.cut_for_search(str)搜索引擎分词结果
全模式分词结果:我/是/最/懂/你/的/聊天/天机/机器/机器人/小/辛//
精确模式分词结果:我/是/最/懂/你/的/聊天/机器人/小辛/!
默认模式分词结果:我/是/最/懂/你/的/聊天/机器人/小辛/!
搜索引擎分词结果:我/是/最/懂/你/的/聊天/机器/机器人/小辛/!
注:HMM
HMM状态状态序列是马尔科夫链,凡是转移矩阵的参数不知道。
HMM是马尔科夫链一阶导数,多用于分词;CRF是隐马的复杂化。
HMM包含两个序列和三个元素。
序列:观测序列是我们能够看到的值,是基于状态序列生成的值;状态序列是未知的,是满足马尔可夫性质的。
元素:状态序列中间的状态初始概率矩阵:派
状态与状态之间的概率转移矩阵:A
状态到观测值的混淆概率矩阵:B
四、命名实体识别LSTM-CRF
识别文本中具有特定意义的实体(人名、地名、机构名、专有名词),从知识图谱的角度来说就是从非结构化文本中获取图谱中的实体及实体属性。
方法:
(1) 基于规则的方法。根据语言学上预定义的规则。但是由于语言结构本身的不确定性,规则的制定上难度较大。
(2) 基于统计学的方法。利用统计学找出文本中存在的规律。
主要有隐马尔可夫(HMM)、条件随机场(CRF)模型和Viterbi算法、支持向量机(Support Vector Machine, SVM)。
(3) 神经网络。
LSTM+CRF模型,基于RNN的seq2seq模型
难点:
1 中文实体识别
中文识别包含英文识别;英文直译实体;
2 特定领域的数据
爱尔眼科集团股份有限公司 B-agency,I-agency,
3数据清洗
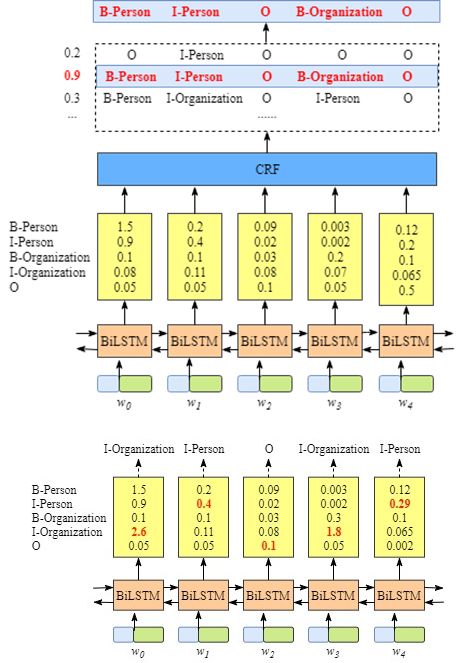
图中输入是word embedding,使用双向lstm进行encode,对于lstm的hidden层,接入一个大小为[hidden_dim,num_label]的一个全连接层就可以得到每一个step对应的每个label的概率,也就是上图黄色框的部分,到此,如果我们直接去最大的概率值就可以完成任务了,那么为什么还要接入一个CRF层?
如果将lstm接全连接层的结果作为发射概率,CRF的作用就是通过统计label直接的转移概率对结果lstm的结果加以限制(这样条件随机场的叫法就很好理解了)
比如I这个标签后面不能接O,B后面不能接B,如果没有CRF,光靠lstm就做不到这点,最后的score的计算就将发射概率和转移概率相加就ok了,我这里给出的是直观感受,不做理论上的讲解。
项目:
双向lstm或IdCNN模型,找到x,y. y是双标签,x是文字word2vec映射成的词向量。
如何拟合x.y:拟合之前第一步提取x的特征,用BiLstm或idCNN对x做特征提取,+分类器(crf条件随机场)
idCNN与cnn的区别是,idCNN的卷积核是扁的:找一句话之间的关系可以用扁的, 好处:可以有效地抗噪音:完形填空时,扁的卷积核它只会扫当前这句话,不会把上下文卷进来,抗的是上下文的躁
CNN和RNN本质上没有太大差别,都是把局部的相关性体现出来,CNN体现在空间上,RNN体现在时间时序上
crf:条件随机场。跟rnn很类似,提供了一个分类结果,当然它也可以做特征提取。它的分类需要算一个联合概率
第一步,找到x,y
第二步,对x做特征提取、特征工程(之前所有的resnet等都是为特征工程服务的),对y做one_hot向量(或二分类)
第三步,去拟合,分类
五、主题模型
1.PCA主成分分析
是一种无监督学习的降维技术,思想是:投影后样本越分散,保留的信息越多
做法:将所有的样本点向直线w投影,目标函数:让投影后的样本方差 极大
通过特征值和特征向量来降维
2.LDA线性判别分析
是一种监督学习的降维技术,思想是:投影后类内方差最小,类间方差最大
做法:计算直线上,每个类别下样本的方差,目标函数:让均值的投影点间的距离/各类别组内方差和极大。
3.LDA隐含狄利克雷分布(主题模型)
Beta分布:是估计硬币正面朝上概率的分布,x轴表示出现正面的概率,y表示出现正面概率的可能性。
狄利克雷分布:是beta分布的推广情形,抛出的结果可能有很多种
np.random.beta(20,20)
np.random.dirichlet(100,100,100,100,100,100)
4.负采样Negative sampling总结
首先为所有的词随机初始化自己的向量(200维)
在基于Negative sampling的CBOW模型中,对某个词w来说,构造一个函数:
预测出词w的概率*不预测出其他词的概率,这是我们想要的极大的,扩展到整个语料库,就是让每个词的函数累乘极大,这便是最终需要最大化的目标函数。

六、知识图谱
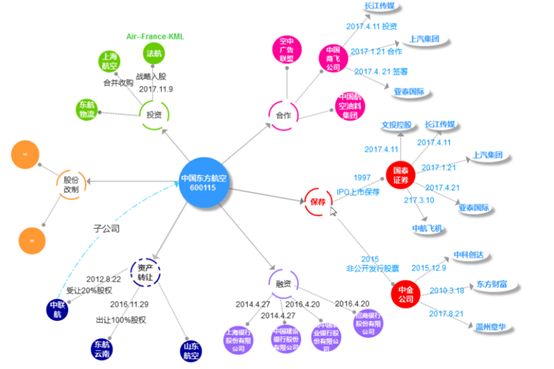
关系抽取是知识图谱中将文本数据进行结构化的一种方法。
从非结构化文本中获取图谱中的实体及实体属性。
之前实习的任务就是从大量的数据中抽取图中的每个实体节点。条件:有的只有未标注的数据和一些数据库中的词典,要做的就是从数据库中抽取原始数据和每个类别的词典进行标注还原。
那么标注还原怎么做呢?这里可以直接将词典导进分词器的,将类别作为词性标注的标签进行标注,这样既做了分词也做了标注。实体识别完成后就是数据入库审核工作了,然后就是做词典更新,添加识别出的新词,继续做模型训练。
数据清洗总结:
1.数据中句子的切割:要做成训练数据那样的标注并不容易,有些句子长度得有1000+个字了,我们尽量把句子的长度控制在100左右,同时要保证词语的完整性。
2.符号清理:这里尽量保证句子中乱七八糟的符号不要太多。
3.然后舍去全是‘O’的标注句子。其实有标注的句子占的比重不大,这里要注意清洗干净。
4.如果对数字识别不做要求,干脆转换成0进行识别
https://github.com/FuYanzhe2/Name-Entity-Recognition
【Batch Normalization】
https://www.cnblogs.com/guoyaohua/p/8724433.html
https://www.cnblogs.com/skyfsm/p/8453498.html
【马尔科夫链--马尔科夫随机场--条件随机场】
https://www.cnblogs.com/lijieqiong/p/6673692.html
https://blog.csdn.net/Jum_Summer/article/details/80793835