表结构
CREATE TABLE `test` (
`i1` int(11) NOT NULL DEFAULT '0',
`i2` int(11) NOT NULL DEFAULT '0',
`d` date DEFAULT NULL,
`f` int(11) DEFAULT '0',
PRIMARY KEY (`i1`,`i2`),
KEY `IX_TEST_N1` (`d`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO TEST VALUES
(1, 1, '1998-01-01',1), (1, 2, '1999-01-01',2),
(1, 3, '2000-01-01',1), (1, 4, '2001-01-01',2),
(1, 5, '2002-01-01',1), (2, 1, '1998-01-01',2),
(2, 2, '1999-01-01',1), (2, 3, '2000-01-01',2),
(2, 4, '2001-01-01',1), (2, 5, '2002-01-01',2),
(3, 1, '1998-01-01',1), (3, 2, '1999-01-01',2),
(3, 3, '2000-01-01',1), (3, 4, '2001-01-01',2),
(3, 5, '2002-01-01',1), (4, 1, '1998-01-01',2),
(4, 2, '1999-01-01',1), (4, 3, '2000-01-01',2),
(4, 4, '2001-01-01',1), (4, 5, '2002-01-01',2),
(5, 1, '1998-01-01',1), (5, 2, '1999-01-01',2),
(5, 3, '2000-01-01',1), (5, 4, '2001-01-01',2),
(5, 5, '2002-01-01',1);
- Using where: 表示MySQL服务器在存储引擎收到记录后进行“后过滤”(Post-filter),如果查询未能使用索引,Using where的作用只是提醒我们MySQL将用where子句来过滤结果集。这个一般发生在MySQL服务器,而不是存储引擎层。一般发生在不能走索引扫描的情况下或者走索引扫描,但是有些查询条件不在索引当中的情况下。
- Using index:表示直接访问索引就能够获取到所需要的数据(覆盖索引),不需要通过索引回表;
- Using index condition :
在MySQL 5.6版本后加入的新特性(Index Condition Pushdown);会先条件过滤索引,过滤完索引后找到所有符合索引条件的数据行,随后用 WHERE 子句中的其他条件去过滤这些数据行;
个人推论
覆盖索引cover不了列内容并且
where 条件包含多个索引信息并且optimizer_switch='index_condition_pushdown=on
就会走Using index condition,engine会根据多个索引筛选数据。同样的条件如果optimizer_switch='index_condition_pushdown=off'; 就会走Using where
下图看起来我的推论是正确的,第一张图覆盖索引能cover 查询列内容,所以没有走icp

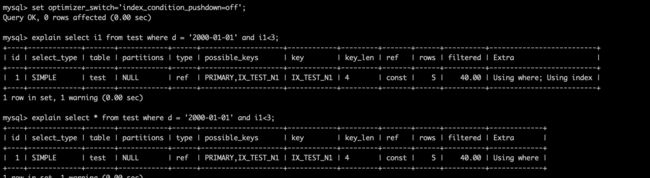
下图又一次证明我的推论是正确的,当optimizer_switch='index_condition_pushdown=off时和上图一样的语句走了Using where
但是看起来下图和我上边的结论相悖,为啥=查询就变成using where 而不是Using index condition,因为下图选中的key是PRIMARY(l1,l2),mysql优化器认为按照主键索引在engine筛选记录,然后把记录给到server让server根据d去过滤,性能更好,所以没有选择icp。

补充:而且并非全部WHERE条件都可以用ICP筛选,如果WHERE条件的字段不在索引列中,还是要读取整表的记录到Server端做WHERE过滤。


下面是博客Index Condition Pushdown中的两幅插图,形象的描述了使用ICP和不使用ICP,优化器的数据访问和提取的过程。


总结:所以mysql explain 的extra 是用来告诉你sql语句实际运行的优化选择,而最好不要根据语句和表结构去尝试反推出extra是什么。
参考资料