一、做项目时是先创模型还是先创建数据库
1、
正向工程:通过面向对象的模型迁移创建数据库的二维表(模型相对比较简单,没有专业的DBA,暂时也不考虑数据访问的优化)
python manage.py makemigrations ——生成迁移
python manage.py migrate ——执行迁移
反向工程:根据关系型数据库的二维表来生成对应的模型(有专业的DBA,模型比较复杂,项目的规模比较大)
python manage.py inspectdb (--database XXX) >app/models.py
——》python会把默认的数据库反向生成models.py,括号里可以选填某个数据库反向导出模型。

说明:默认数据库指的是default!!!
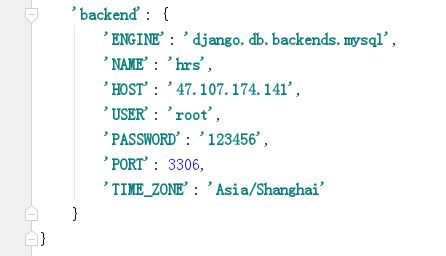
注意:(--database XXX)中的XXX对应的是backend,而不是数据库名hrs!!!
2、
如果django中配置了多个数据库,那么需要配置数据库路由。
我们可以这样给各个app文件夹的models.py文件中的模型(类)添加app_label属性打一个标签,这样的话我们可以通过检查模型的app_lable来决定访问数据库时路由到哪个数据库。
为models.py文件中的模型添加app_label属性
class TbEmp(models.Model):
eno = models.IntegerField(primary_key=True)
class Meta:
managed = False
db_table = 'tb_emp'
app_label = 'hrs' ——添加此属性
为settings.py文件添加以下代码
DATABASE_ROUTERS = [
'app.routers.AuthRouter',
]
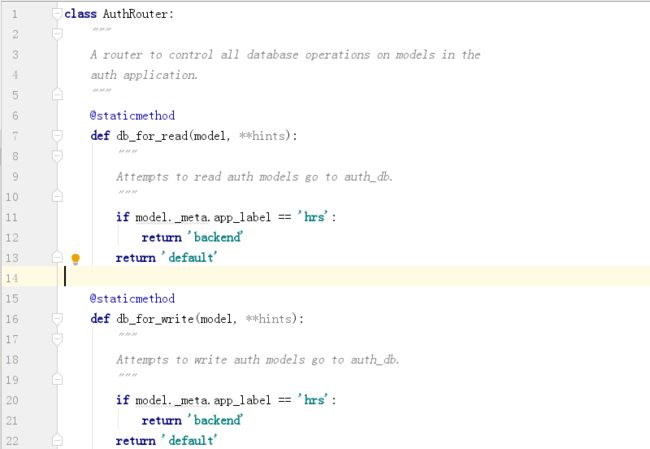
新增routers.py文件到app文件夹下,并完成有关代码!
路由类需要提供4个方法:
db_for_read
db_for_write
allow_relation --> True
allow_migration --> True
对应看下图表

======================================
数据库单表查询时,对表中属性选择性的查询能提高查询性能和节约内存,采取only方法来优化:
emps=Models.objects.all().only('name','gender','age')
=========================
props=('ename','job','sal','comm')
emps=TbEmp.objects.all().only(*props).order_by('-sal')[:10]
在使用ORM框架处理关联查询,联表查询时如果不做任何处理将会导致1+N查询问题。如果希望使用内连接或者左外连接来优化查询,
那么可以使用下面的方式优化:
-select_related('关联属性') ——多对一
-prefetch_related('关联属性') ——多对多
props=('ename','job','sal','comm')
emps=TbEmp.objects.all().only(*props).select_related('外表A属性1').select_related('外表B属性2')
django框架中对查询的数据分页处理流程
1、前端传回一个page参数,没有则默认为第一页;
2、查询符合条件的模型对象(访问数据库),并对模型对象进行切片处理(模型对象是一个列表,故可切片)
props = ('no', 'name', 'job', 'mgr', 'sal', 'dept')
emps = Emp.objects.all().only(*props)\
.select_related('mgr').select_related('dept')\
.order_by('-sal')[(page - 1) * size:page * size]
size即为每页的数据个数,自定。
==============================================
如果django的ORM框架在功能或者性能上达不到要求那么也可以通过原生的SQl查询来代替ORM框架的工作
django框架中如何写原生sql代码
1、连接数据库并获取游标
from django.db import connections,connection
con=connection.cursor() #连接default数据库并获取游标
con=connections['dafault'].cursor()
con=connections['backend'].cursor() #连接backend对应的数据库并获取游标
2、编写sql代码
con.excude('sql代码') #sql代码要用引号包起来,同时如果存在字符串格式化,要用 百分号%s 占位符格式 而不用 f'{}' 格式
3、获取数据库返回结果
result=con.fetch() #获取一个结果
result=con.fetchall() #获取所有结果
result=con.fetchmany() #获取多个结果
from django.db import connections
def data_bar(request):
names, totals = [], []
# connections['default'] <==> connection
with connections['default'].cursor() as cursor:
cursor.execute('select name, total from tb_agent t1 '
' left outer join '
' (select agentid, count(agentid) as total '
' from tb_agent_estate group by agentid) t2 '
' on t1.agentid = t2.agentid')
for row in cursor.fetchall():
names.append(row[0])
totals.append(row[1])
return JsonResponse({'x_data': names, 'y_data': totals})
============================================
pip install django -i https://pypi.doubanio.com/simple
pip install -U pip 更新pip
虚拟环境依赖项
1、将依赖项导出到文件requirment.txt
pip freeze > requirment.txt
2、将依赖项安装到虚拟环境中
pip install requirment.txt
更改pip的配置文件
windows系统下的pip文件夹更改pip.ini ( cd C:\Users\Administrator\pip)
linux系统下.pip隐藏文件夹更改pip.conf (cd .pip)