说起聊天机器人,我们先熟悉一下不同名称对话系统的概念。
单轮对话
单轮与传统的问答系统相类似,是智能对话系统的初级应用。一般表现为一问一答的形式,用户提出问题或前发出请求,系统识别用户意图,做出回答或执行特定操作。单轮对话也强调自然语言理解,但一般不涉及上下文、指代、省略或隐藏信息,相对来说实现难度更低,产品的应用也更加成熟可靠。
多轮对话
多轮对话一般是任务驱动的多轮对话,用户是带着明确的目的的,如订餐,订票,叫车,寻找音乐、电影或某种商品等比较复杂的需求来,而这中间有很多限制条件,用户并不能一次将任务所需的关键信息一次性说完,说清楚,因此就要分多轮进行QA问答一方面,用户在对话过程中,可以不断修正和完善自己的需求;另一方面,当用户在陈述需求不够具体和明确时,机器人可以通过询问,澄清和确认来帮助用户寻找满意的结果,并且在任务的驱动下与用户完成日常的交互,以此不断完善对于用户需求的满足。因此,任务驱动的多轮对话不是一个简单的自然语言理解加信息检索的过程,而是一个决策过程,需要机器在对话过程中不断根据当前的状态决策下一步应该采取的最优动作(如:提供结果,询问特定限制条件,澄清或确认需求,等等)从而最有效的辅助用户完成信息或服务获取的任务。
模块化的对话系统
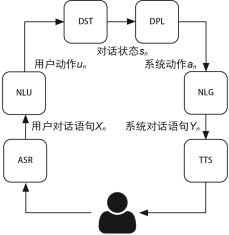
分模块串行处理对话任务,每一个模块负责特定的任务,并将结果传递给下一个模块,通常由NLU(Natural Language Understanding,自然语言理解)、DST(Dialogue State Tracking,对话状态追踪)、DPL(Dialogue Policy Learning,对话策略学习)、NLG(Natural Language Generation,自然语言生成)4个部分构成。在具体的实现上,可以针对任一模块采用基于规则的人工设计方式,或者基于数据驱动的模型方式。
(1)NLU:将用户输入的自然语言语句映射为机器可读的结构化语义表述,这种结构化语义一般由两部分构成,分别是用户意图(user intention)和槽值(slot-value)。
(2)DST:这一模块的目标是追踪用户需求并判断当前的对话状态。该模块以多轮对话历史、当前的用户动作为输入,通过总结和推理理解在上下文的环境下用户当前输入自然语言的具体含义。对于对话系统来说,这一模块有着重大意义,很多时候需要综合考虑用户的多轮输入才能让对话系统理解用户的真正需求。
(3)DPL:也被称为对话策略优化(optimization),根据当前的对话状态,对话策略决定下一步执行什么系统动作。系统行动与用户意图类似,也由意图和槽位构成。
(4)NLG:负责把对话策略模块选择的系统动作转化为自然语言,最终反馈给用户。
端到端的对话系统
考虑采用由输入直接到输出的端到端对话系统,忽略中间过程,采用数据驱动的模型实现。
目前,主流的任务对话系统实现为模块化方式,由于现有训练数据规模的限制,端到端的方式仍处于探索阶段。
对话流程如下图所示:
1、首先接受用户消息,并将该消息送到Interpreter,可以理解为一个解析器,它会把用户的输入内容转变为一个字典,其中包括原始信息,意图,实体等等,其实就是Rasa的NLU模块所做的事情。
2、接下来会把字典送给Tracker,这个是用来记录对话状态并跟踪对话进度的。
3、Policy会接收到Tracker当前的状态,并根据这个状态选择一个合适的Action
4、Action一方面会把信息发送给Tracker,让它记录下当前的状态,另一方面还会给用户发送信息。
今天我们着重讲一下NLU模块。
对于面向任务的对话系统来说,NLU的主要作用是对用户输入的句子或者语音识别的结果进行分析,提取用户的对话意图以及用户想要传递的真实意图。涉及的主要技术是意图识别和槽位填充,这两种技术分别对应用户动作的两项结构化参数,即意图和槽位。
当用户输入“明天天气如何?、明天是晴天还是雨天?明天需要抹防晒霜吗?”聊天机器人只需要理解用户是想查询天气;当用户输入“如何包龙虾馅的饺子时”,聊天机器人要正确理解为“包饺子”而不是“包龙虾”才行......所以正确的识别用户意图是一个聊天机器人有无价值的重要基础。
意图识别的方法:
一、规则模板方法
通过专家手工编写规则模板来识别意图。比如:
买 .* 《地名》 .* 《地名》.* 机票 =》 买机票
模板构成: 字符串、词性、正则表达式。
通过匹配上述模板,即可识别出对应的意图。
缺点:
1、人工编写工作量大,易冲突
2、规则模板覆盖面较小,使用通配符可以解决一部分问题,但带来了匹配优先级的问题
3、适用于垂直领域,在通用领域则无法推广
二、基于统计的方法
使用意图词典做词频统计,取词频最大的就是对应的意图
缺点
1、覆盖面比规则模板广,但容易误识别
三、基于语法的方法
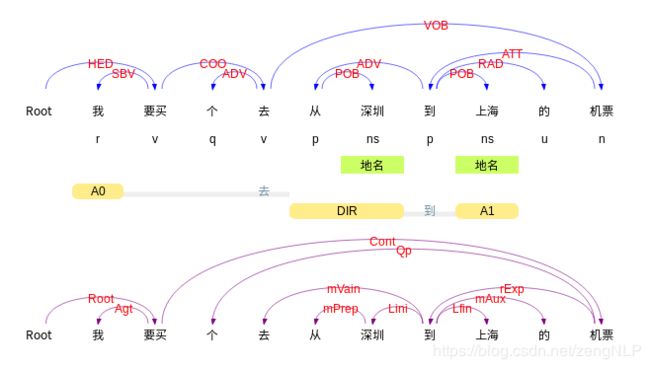
先对句子做语法分析,找到中心动词及名词,再根据意图词典即可识别出意图来。如:
我要买从深圳到上海的机票

2、再根据意图词典即可识别出“买机票”意图
基于机器学习的方法
a.数据标注 b.数据预处理 c.训练集拆分 d.特征提取 e.特征向量化 f.使用模型训练
基于深度学习方法
核心思想:把意图识别看成是文本分类任务。
a.语料标注 b.分词 c.搭建模型
槽值填充
槽位,即意图所带的参数。一个意图可能对应若干个槽位,例如询问公交车路线时,需要给出出发地、目的地、时间等必要参数。
槽的属性:
1、可默认填写/不可默认填写;
2、澄清话术(当槽不可默认填写且又没有填写的时候,就要进行澄清);
3、平级槽或依赖槽(根据槽和槽之间是否独立,后续的槽是否依赖于前面的槽决定);
4、多轮记忆状态(槽位没有填满则反复询问,直到填充完毕)。
要使一个面向任务的对话系统能正常工作,首先要设计意图和槽位。意图和槽位能够让系统知道该执行哪项特定任务,并且给出执行该任务时需要的参数类型。对于一个单一的任务,上述定义便可解决任务需求。其实在真实的业务环境下,一个面向任务的对话系统往往需要能够同时处理若干个任务。对于同一系统处理多种任务的复杂情况,一种优化的策略是定义更上层的领域,可以简单地将领域理解为意图的集合。定义领域并先进行领域识别的优点是可以约束领域知识范围,减少后续意图识别和槽位填充的搜索空间。此外,对于每一个领域进行更深入的理解,利用好任务及领域相关的特定知识和特征,往往能够显著地提升NLU模块的效果。
槽位填充的三种方法
1、把槽位填充任务转变成关系抽取任务,用传统的信息抽取方法是实现槽值填充,按照具体实现方法不同,信息抽取方法又可以分为模式匹配的方法和基于分类器的方法;
2、以问答系统为基础,通过槽值填充任务中定义的每一个等价问题集合的方式来完成槽值填充;
3、基于规则的方法,直接依靠人工的方法为每一个槽位构建对应的模式库或者规则库,然后以这些模式或规则为标准从测试语料中检索出符合标准的实例来完成槽值填充任务。
意图识别实际上是一个分类任务,槽位填充实际是一种序列标注的问题。
为了更好地融合意图识别与槽位填充,提出了很多很好的模型来完成这项任务。
1、利用双向的GRU+CRF作为意图与槽位的联合模型;
2、利用语义分析树构造路径特征实现槽位填充与意图识别联合的模型;
3、基于CNN+Tri-CRF的模型;
.......