学习shader之前必须知道的东西之计算机图形学(一)渲染管线
引言
shader到底是干什么用的?shader的工作原理是什么?
其实当我们对这个问题还很懵懂的时候,就已经开始急不可耐的要四处搜寻有关shader的资料,恨不得立刻上手写一个出来。但看了一些资料甚至看了不少cg的语法之后,我们还是很迷茫,UNITY_MATRIX_MVP到底是个什么矩阵?它和v.vertex相乘出来的又是什么玩意?当这些问题困扰我们很久之后,我们才发现,原来我们是站在浮沙上筑高台,根基都没有打牢当然不可能盖得起高楼大厦了。
那根基是什么呢?大牛曰,计算机图形学。
shader中文名叫着色器,顾名思义,它的作用可以先简单理解为给屏幕上的物体画上颜色。而什么东西负责给屏幕上画颜色?当然是GPU,所以我们写shader的目的就是告诉GPU往屏幕哪里画、怎么画。说到这其实大家应该很明白了,如果我们连GPU的工作原理都不知道,何谈指挥它?
说到计算机图形学,包括我在内很多同学都非常害怕它,因为里面包含了各种艰深的理论、变换,大量的公式什么的。其实我们大可不必一开始就吓倒自己,先从基本概念开始,慢慢来,总有一天我们也会成为大牛~!
最后,这篇文章不算是原创,最多算是摘要+读后感,很多概念性文字都是我从书里搬过来后再加上自己的理解,算是和大家一起学习,有理解不当之处还请多多指教。
废话不多说,让我们来进入第一章的学习,GPU的渲染管线。
正文
所谓GPU的渲染管线,听起来好像很高深的样子,其实我们可以把它理解为一个流程,就是我们告诉GPU一堆数据,最后得出来一副二维图像,而这些数据就包括了”视点、三维物体、光源、照明模型、纹理”等元素。
在各种图形学的书中,渲染管线主要分为三个阶段:应用程序阶段、几何阶段、光栅阶段。
1,应用程序阶段。
这个阶段相对比较好理解,就比如我们在Unity里开发了一个游戏,其实很多底层的东西Unity都帮我们实现好了,例如碰撞检测、视锥剪裁等等,这个阶段主要是和CPU、内存打交道,在把该计算的都计算完以后,在这个阶段的末端,这些计算好的数据(顶点坐标、法向量、纹理坐标、纹理)就会通过数据总线传给图形硬件,作为我们进一步处理的源数据。
2,几何阶段。
主要负责顶点坐标变换、光照、裁剪、投影以及屏幕映射,改阶段基于GPU进行运算,在该阶段的末端得到了经过变换和投影之后的顶点坐标、颜色、以及纹理坐标。简而言之,几何阶段的主要工作就是“变换三维顶点坐标”和“光照计算”。
问题随之而来,为什么要变换顶点坐标?我是这么理解的,比如你有一个三维游戏场景,场景中的每个模型都可以用一个向量来确定它的位置,但如何让计算机根据这些坐标把模型正确的、有层次的画在屏幕上?这就是我们需要变换三维顶点坐标的原因,最终目的就是让GPU可以将这些三维数据绘制到二维屏幕上。
根据顶点坐标变换的先后顺序,主要有如下几个坐标空间:Object space,模型坐标空间;World space,世界坐标空间;Eye space,观察坐标空间;Clip and Project space,屏幕坐标空间。下图就是GPU的整个处理流程,深色区域就是顶点坐标空间的变换流程,大家了解一下即可,我们需要关注的是每个坐标空间的具体含义和坐标空间之间转换的方法。
2.1,从object space到world space
object space有两层核心含义,第一,object space中的坐标值就是模型文件中的顶点值,这些值是在建立模型时得到的,例如一个.max文件,里面包含的数据就是object space的坐标。第二,object space的坐标与其他物体没有任何参照关系,这是object space和world space区分的关键。world space坐标的实际意义就有有一个坐标原点,物体跟坐标原点相比较才能知道自己的确切位置。例如在unity中,我们将一个模型导入到场景中以后,它的transform就是世界坐标。
2.2,从world space到eye space
所谓eye space,就是以摄像机为原点,由视线方向、视角和远近平面,共同组成的一个梯形体,如下图,称之为视锥(viewing frustum)。近平面,是梯形体较小的矩形面,也是靠近摄像机的平面,远平面就是梯形体较大的矩形,作为投影平面。在这个梯形体的内的数据是可见的,超出的部分会被视点去除,也叫视锥剪裁。
例如在游戏中的漫游功能,屏幕的内容随摄像机的移动而变化,这是因为GPU将物体的顶点坐标从world space转换到了eye space。
2.3,从eye space到project and clip space
eye space坐标转换到project and clip space坐标的过程其实就是一个投影、剪裁、映射的过程。因为在不规则的视锥体内剪裁是一件非常困难的事,所以前人们将剪裁安排到一个单位立方体中进行,这个立方体被称为规范立方体(CCV),CVV的近平面(对应视锥体的近平面)的x、y坐标对应屏幕像素坐标(左下角0、0),z代表画面像素深度。所以这个转换过程事实上由三步组成:
(1),用透视变换矩阵把顶点从视锥体变换到CVV中;
(2),在CVV内进行剪裁;
(3),屏幕映射:将经过前两步得到的坐标映射到屏幕坐标系上。
2.4,primitive assembly(图元装配)和triangle setup(三角形处理)
到目前为止我们得到了一堆顶点的数据,这一步就是根据这些顶点的原始连接关系还原出网格结构。网格由顶点和索引组成,这个阶段就是根据索引将顶点链接到一起,组成线、面单元,然后进行剪裁,如果一个三角形超出屏幕以外,例如两个顶点在屏幕内,一个顶点在屏幕外,这时我们在屏幕上看到的就是一个四边形,然后把这个四边形切成两个小的三角形。
现在我们得到了一堆在屏幕坐标上的三角形面片,这些面片是用于光栅化的。
3,光栅化阶段。
经过上面的步骤之后,我们得到了每个点的屏幕坐标值,和我们需要绘制的图元,但此时还有两个问题:
(1)屏幕坐标是浮点数,但像素是用整数来表示的,如何确定屏幕坐标值所对应的像素?
(2)如何根据已确定位置的点,在屏幕上画出线段或者三角形?
对于问题1,绘制的位置只能接近两指定端点间的实际线段位置,例如,一条线段的位置是(10.48, 20.51),转换为像素位置就是(10,21)。
问题2,涉及到具体的画线和填充算法,有兴趣的话可以研究。
这个过程结束后,顶点和图元已经对应到像素,之后的流程就是如何处理像素,即给像素赋予颜色值。
给像素赋予颜色的阶段称为Pixel Operation,是在更新帧缓存之前,执行最后一系列针对每个片段的操作,其目的是计算出每个像素的颜色值。在这个阶段,被遮挡的面通过一个被称为深度测试的过程消除。
pixel operation包含下面这些流程:
(1)消除遮挡面;
(2)Texture operation,纹理操作,根据像素的纹理坐标,查询对应的纹理值;
(3)Blending,通常称为alpha blending,根据目前已经画好的颜色,与正在计算的颜色的alpha值混合,形成新的颜色。
(4)Filtering,将正在计算的颜色经过某种滤镜后输出。
该阶段之后,像素的颜色值被写入帧缓存中。
图形渲染管线
在实时计算机图形学中,可以将管线结构粗略地分为3个阶段:应用程序、几何、光栅。
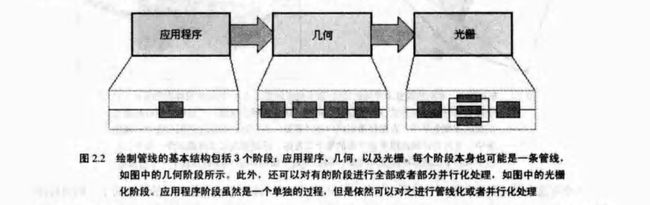
应用程序阶段由应用程序来驱动,因此可以通过软件来实现。这个阶段可以包括碰撞检测、加速算法、动画以及力反馈等。几何阶段,可以用软件或硬件实现,包括变换、投影、光照等处理。此阶段主要计算绘制的内容、如何绘制,以及在什么地方绘制。光栅阶段是利用前面阶段产生的数据进行图像绘制。
在应用程序阶段的末端,将需要绘制的几何体输入到绘制管线的下一个阶段,这些几何体都是绘制图元(如点、线、矩形等)。这就是应用程序阶段的主要任务。
几何阶段主要负责大部分多边形和顶点操作,可以将这个阶段进一步划分为几个功能阶段。如图:

1) 模型与视点变换
在屏幕上的显示过程中,模型通常需要变换到若干不同的空间或坐标系统中。模型变换的变换对象是模型的顶点和法线。物体的坐标为模型坐标,如果将模型变换应用到这些坐标中,就可以说这个模型位于世界坐标系。相机在世界坐标系中有一个位置和方向,用来放置和校准相机。为了方便投影和裁减,必须对相机和所有模型进行视点变换。如图:
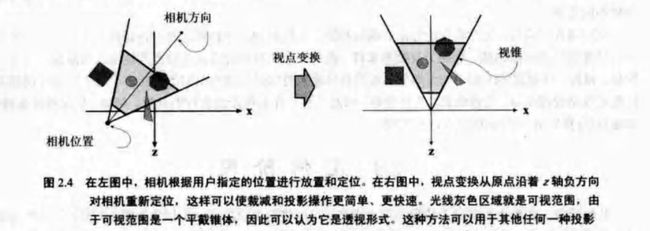
所有的模型变换和视点变换都用一个4x4矩阵来实现。出于效率的考虑,在模型变换之前首先将所有的矩阵联合起来,彼此相乘,形成一个矩阵。需要注意的是,经过这种方式,世界坐标系(World)将不复存在——模型直接变换到了观察空间。(View)。
2)光照和着色
为了让模型看起来更加真实,可以给场景配上一个或多个光源。对于受光源影响的模型来说,可以用光照方程来计算模型上每个顶点的颜色。通常,光照计算是在世界坐标系中进行的。但是,如果对光源进行视点变换,在观察空间中会得到同样的光照效果。这是因为,即使将参与光照计算的所有实体都变换到同一个空间(即观察空间)中,光源,相机以及模型之间的相对位置依然保持不变。
3)投影
在光照处理之后,绘制系统就开始进行投影,目的是将视体变换为一个单位立方体,这个单位立方体的对角顶点分别为(-1,-1,-1)和(1,1,1,)。通常也称单位立方体为规范视体。目前主要有两种投影方法,平行投影(也称正投影)和透视投影。
平行投影的可视体通常是一个矩形盒子,平行投影可以将这个视体变换为单位立方体。平行投影的主要特性是平行线在投影之后彼此依然保持平行。这种变换是平移和缩放的组合。
透视投影中,物体距离相机越远,投影之后变得越小。所以透视变换和人类感觉物体大小的过程非常相似。透视投影的视体是一个以矩形为底面的被截金字塔,同样也可以把这个锥平截头体变换为单位立方体。
平行投影和透视投影都可以通过4x4矩阵实现。在任何一种变换后,都认为模型位于归一化处理后的设备坐标系(规范化设备坐标系)。
这种投影形式将模型从三维投影到二维。投影之后产生的图像中的z坐标系将不复存在(但是在Z缓冲器中保留有z坐标值)。
4)裁减
舍弃掉超出单位立方体(规范视体)的图元。
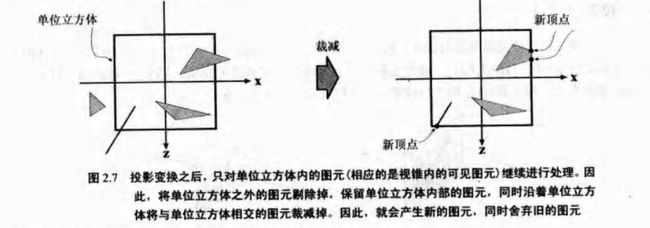
5)屏幕映射
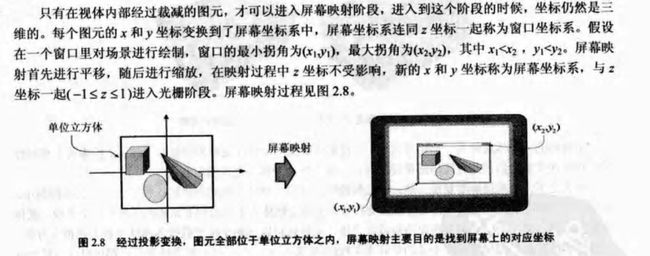
光栅阶段
光栅阶段的目的是给每个像素正确配色,这个过程称为光栅化,也就是把屏幕空间的二维顶点转化为屏幕上的像素。屏幕空间有一个z值(深度值)、一种或两张颜色,以及一组或多组纹理坐标,纹理坐标会与顶点联系在一起。不像几何阶段那样进行的是单多边形操作,光栅化进行的是单个像素的操作。每个像素的信息存储在颜色缓冲器里, 颜色缓冲器是一个矩形的颜色序列,光栅阶段必须在硬件中完成。(管线图有时候用两个部分描述这个阶段。第一部分是三角形设置,其中计算三角形表面的各种微分和其他数据,第二部分为光栅化,其中对像素进行检查并填充。
为了避免观察者体验到对图元进行处理并发送到屏幕的过程,图形系统一般采用双缓冲机制,也有三缓冲等。这说明屏幕的绘制是在一个后置缓冲器中以离屏方式进行的。当完成后台的绘制,后置缓冲器中的内容就不断与已经在屏幕上显示过的前置缓冲器中的内容进行交换。
Z缓冲器(深度缓冲器)是用来负责可见性问题的。比如,一个距离相机更近的物体会挡住后面的物体。Z缓冲器和颜色缓冲器的形状大小一样,每个像素都存储着一个z值,这个z值是从相机到最近图元的距离,当将一个图元绘制为相应的像素时,需要计算像素位置处图元的z值并与同一像素的Z缓冲器中的内容进行比较。如果这个z值远远小于Z缓冲器中的z值,那么像素的z值和颜色就由当前图元对应的z值和颜色进行更新。否则不变。在这个Z缓冲器算法中,像素的绘制顺序是任意的。注意:对于部分透明的像素的绘制,必须在所有非透明像素绘制之后进行。
模板缓冲器的内容以后讲解。
Unity中的深度测试相关知识与问题
深度缓冲格式、深度冲突及平台差异
深度测试
UnityZ-Fighting产生原因
Unity Shader - Offset 的测试,解决简单的z-fighting情况
unity shader Offset Factor, Units详解
ShaderLab culling and depth testing
一直想梳理一下Unity中深度缓冲相关知识,以及Unity shader Offset的用法,今天看到一篇文章,讲得非常好,转发记录一下。
这里先说一下深度测试。
深度测试
在场景中我们会通过虚拟摄像机拍摄到当前视角下的物体渲染最终画面,而画面是由虚拟相机可视范围内的所有可见的三维物体通过计算并映射到二维得到的,最终会呈现出远小近大(透视模式)的效果,在映射到二维空间时,显卡会通过插值运算将每一个顶点进行光栅化,最终得到的片元,每个片元到摄像机的近裁剪面的距离转换为一个深度值,保存在深度缓冲中,用于确定每个像素渲染时的顺序,以此来保证物体的深度关系。
我们知道半透明物体渲染由远及近(可以看到物体后面的物体),不透明物体由近及远(只需要看到最近的物体,交叉物体只需要看到最近的部分),因为没有必要渲染看不到的部分,浪费资源,所以需要通过测试来过滤掉被遮挡的片元,下面是一位知乎大佬关于深度测试与深度写入的总结,我觉得说的很好:
深度测试的意义在于舍弃片元与否。
深度写入的意义在于深度测试的基础上,要不要覆盖深度缓冲,即重新设立深度测试的标准。
GPU的渲染流程:

GPU的渲染流程
深度测试的大概流程:
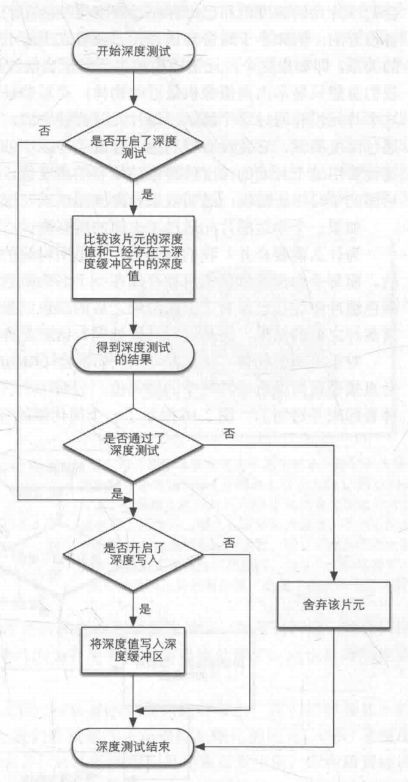
深度测试流程
混合的大概流程:
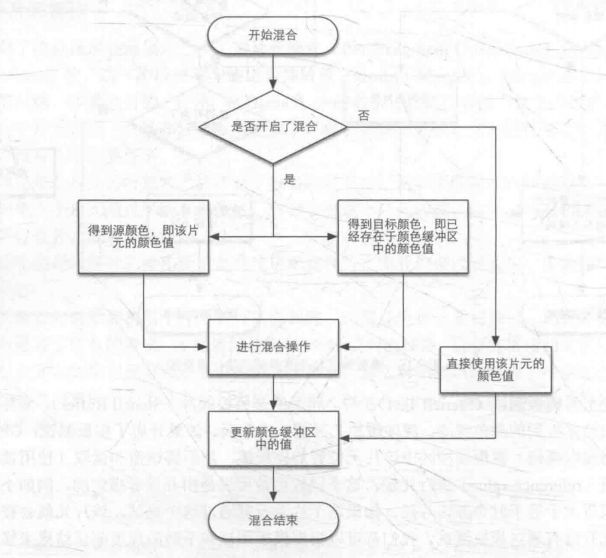
混合流程
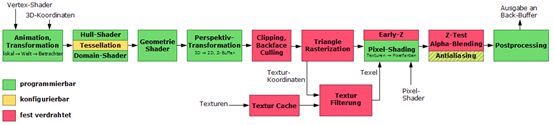
另外现代GPU为了提高性能,还会有一个Early-Z的过程,即提前到光栅化之后,片元函数之前进行一次快速的深度测试,避免在片元函数中再进行逐像素的处理,节省性能,加快渲染速度,这里放两张图,更多信息,可以网上自己搜一下。
Unity Shader-渲染队列,ZTest,ZWrite,Early-Z
Early-Z
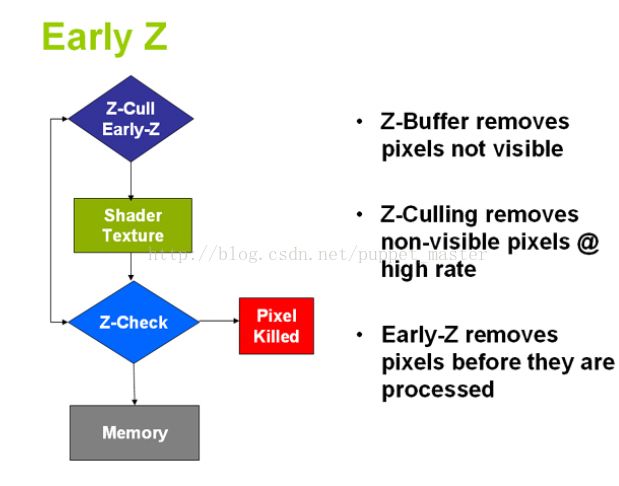
Early-Z
不过要注意在移动平台的GPU架构TBR(Tile-Base-Rendering)和TBDR(Tile-Base-Deffered-Rendering),与PC平台GPU的IR(Immediate-Rendering)架构的差异,TBDR还采用了HSR(Hidden Surface Removal)技术,可以实现零Overdraw,性能更好,iOS采用的就是TBDR架构。
移动设备GPU架构知识汇总(转)
非线性的Depth Buffer
我们知道顶点从View Space中转换到NDC的过程,也叫做投影。
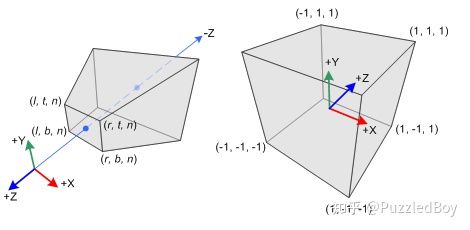
视锥体将顶点从View Space变换到NDC(OpenGL)
投影过程中x和y分量都只是分别做了简单的线性的变化,如上图x从[l,r]线性映射到了[-1,1],y从[b,t]到[-1,1]。
z也做了映射,但是却不是线性的!而是越靠近摄像机近平面的两个顶点,深度值相差会越大,它们的关系曲线如下:
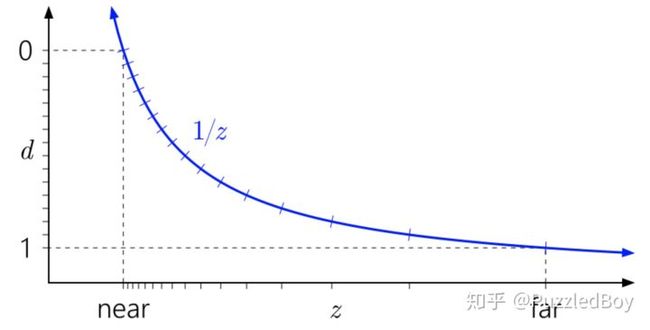
深度缓冲d和View Space z的关系
注:深度值d和NDC中的z是什么关系?d就是Depth Buffer中的值,OpenGL中Depth Buffer只是将NDC的z从[-1,1]线性映射到了[0,1]而已;而D3D中,由于NDC z取值范围已经是[0,1],所以两者是相同的。因此你大可以认为d等价于NDC z。
从图中我们可以看到距离摄像机很近的地方,占据了大半的深度取值范围。
为什么z->d的映射是非线性的?
实用层面的理解:计算机存储一个值是有精度的,摄像机中离我们越远的物体,信息就越少,对画面的贡献也越少,我们根本不需要为远处物体的数据提供更高的精度。所以深度值在靠近近平面精度越高,越远精度越低。
在数学上的理解:我们都知道光栅化时片段的各种属性(纹理坐标、颜色等)需要经过GPU插值,其实这个插值并不是线性的,因为在投影面上等距的两点,对应的被投影的两点并不是等距的:
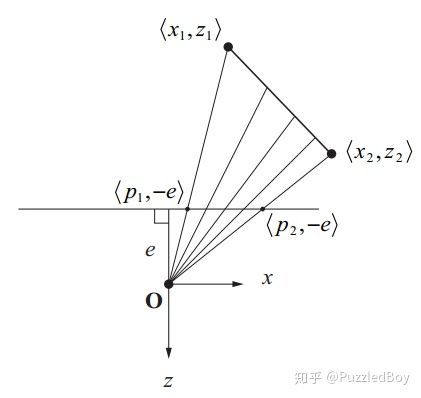
投影面上等距的两点,对应的被投影的两点并不等距
如图,把线段 (x1,z1)(x2,z2) 投影到屏幕上 z=-e上,我们会发现在屏幕上取等距离的两点,对应线段上的点距离并不相等。然后经过数学推导发现,顶点属性的插值不和z成线性关系,而是和1/z成线性关系! 这样就和为什么深度不是线性的产生了联系。
扩展:如果想彻底了解投影的数学过程,可以参考一些图形学数学书或OpenGL Projection Matrix
作为工程师,不用记住数学,只要记住Depth Buffer是非线性的就行了。
所以在Fragment Shader中操作Depth Buffer的时候,比如制作雾效、深度可视化等,一定先将z变换到线性空间。公式参考如下:

其中

其中d表示片段在Depth Buffer中深度值,n表示摄像机的近平面near,f表示摄像机的远平面far。这个公式是从投影矩阵中推导出来的,如果对数学有兴趣可以参考前面的扩展链接。
在Shaderlab中可以用内置Linear01Depth函数做深度的线性化:
float Linear01Depth( float z )
深度冲突(Z-Fighting 、Depth-Fighting)
前面提到了Depth Buffer是非线性的,越靠近摄像机的地方,精度越高。
因此在远离摄像机的地方,精度不够了,就容易出现两个深度值很接近的片段不断闪烁的问题,看上去就像它们在争夺谁显示在前面的权利。
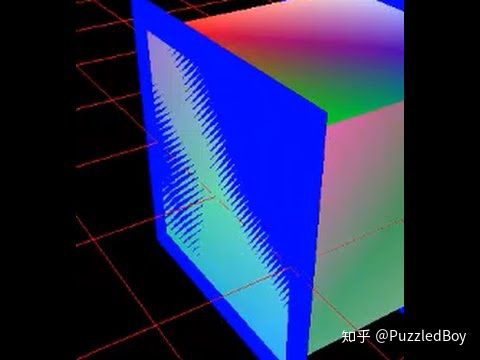

深度冲突导致的闪烁
解决的思路分为三种,一是可以增加深度的精度,二是杜绝物体Z过于接近的情况,三是在Shader中利用Offset语法。
第一种方法可以通过增大深度缓冲本身的数据位数来做到,但是一般来说不会这么做,因为为了解决深度冲突而增大显存的占用并不是很明智。还有一种方法就是修改摄像机的近远平面,让其范围更小,范围小了之后数据能够表示的精度自然就上升了。
第二种方法其实是很实用的,略微在场景中移动物体坐标,错开那些靠的很近的物体,其实基本上都能解决问题。
第三种,利用Offset语法,以Shaderlab为例,Offset指定片段深度的偏移量来解决这个问题:
Offset Factor, Units
片段深度的偏移量offset = m * factor + r * units 其中m是多边形在深度方向的斜率的最大值,r是深度缓冲中可以分辨的差异最小值,是一个常数。
平台差异
在实际项目中,你可能遇到这样的情况,在iOS和PC上是没有问题的,但是打包到Android后却出现了片段闪烁问题,疑似深度冲突,但是又因为平台差异让你不太确信。 其实你的猜测8成是对的,就是深度冲突问题,但为什么只有Android才会呢?这就要从深度缓冲的取值范围变化历史说起了。 我们现在知道,OpenGL的深度范围是[-1,1],DirectX是[0,1],但其实这只是早期的说法,现在已经不准确了。在Unity的这一篇文章中,提到了这样一段话:

总结一下:
对于DirectX 11,DirectX12,PS4,Xbox One,和Metal,现在使用的都是新的方法Reversed direction。即NDC的取值范围是[1,0]。对于其他的图形接口,保持传统的取值范围。即我们前文提到的,OpenGL是[-1,1],DirectX是[0,1] (在文档中提到都是[0,1]我认为这里是文档错误。
在最后一段特别提到了,新的方法Reversed direction比旧的方法精度更高。这也是为什么在PC(DirectX11 或12)或iOS(Metal)不会出现深度冲突,但是打包在Android(OpenGL ES)确出现的原因。
为啥取值范围从[0,1]变成[1,0]精度就更高了?
你或许对Unity文档最后的那段话感到好奇,为什么单纯反一下取值范围精度就更高了呢?其实在Nvidia这一篇 文章中有解释到原因。大意就是,我们之前认为在距离d上数值的分布应该是等距的,但其实这不对,因为计算机存储浮点数是按照 尾数^指数 的方式存储的,数值是离散的而且不等距:
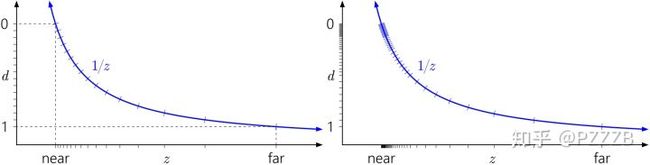
左(不考虑浮点数存储格式),右(考虑浮点数存储格式)
注意看y轴上点的分布,这也导致了在实际情况下,精度的衰减其实更快,在稍微远离近平面不远的地方或许精度就不够用了。但是如果我们把y轴范围反一下,即Reversed direction,就会变成这样:
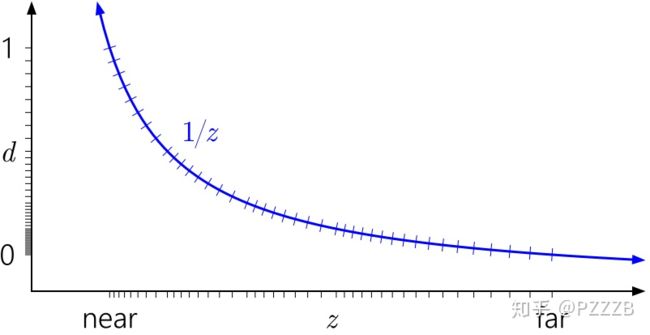
精度衰减的没那么快了,而且基本上是相同精度。因此新的接口都使用Reversed direction的方法,不过可惜OpenGL ES的取值仍然是传统取值(Android说你呢!),因此才有Unity文档中的那么一说。