最近在老师的推荐下,看了几篇论文。下面来总结一下FM的“延申宝宝”——FFM、UP-FM和CFM。
这篇主要解决以下问题:
FFM、UP-FM和CFM的原理以及如何 基于FM做改变。
一、FM(Factorization Machines,因子分解机)
关于FM之前有比较详细地介绍过(https://www.jianshu.com/p/249e4a74825e),这里就不介绍了。
FM的公式为:
二、FFM(Field-aware Factorization Machine)
FFM在FM的基础上进一步改进,在模型中引入类别的概念,即field。将同一个field的特征单独进行one-hot,因此在FFM中,每一维特征都会针对其他特征的每个field,分别学习一个隐变量,该隐变量不仅与特征相关,也与field相关。
假设样本的个特征属于个field,那么FFM的二次项有nf个隐向量。而在FM模型中,每一维特征的隐向量只有一个。FM可以看做FFM的特例,把所有特征都归属到一个field的FFM模型。其模型方程为:
其中是第的特征所属的字段。
2.1 损失函数
FFM将问题定义为分类问题,使用的是logistic loss,同时加入正则项:
求解方法参考FM的求解方法。
2.2 小结
与FM对比,FFM做得更精细,FM中每个特征对应一个隐变量,FFM每个特征对应多个隐变量
参考:
FM系列算法解读(FM+FFM+DeepFM)
CTR预估算法之FM, FFM, DeepFM及实践——https://blog.csdn.net/john_xyz/article/details/78933253
三、UP-FM(基于用户画像和因子分解机)
3.1 用户画像
用户画像是通过用一系列数据来构建真实用户的用户模型。用户画像技术主要通过构建用户标签的方式来表征用户信息,实现对用户特征全面、精准的刻画和描述。构建用户画像是实现个性化推荐和精准推荐的前提。
3.2 基于用户画像和因子分解机建模
在《基于用户画像和因子分解机的推荐算法研究》这篇论文中,有很详细地说明了如何基于用户画像和因子分解机的建模过程。
以上论文的做法:将用户画像的多维特征信息引入到 FM 模型中,构建基于用户画像和因子分解机的点击预测模型。主要研究框架如下图:
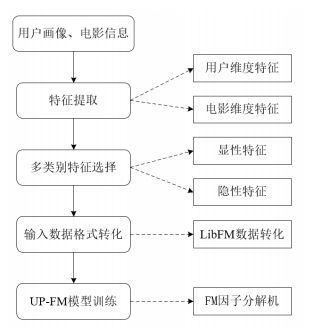
用户维度特征:从用户画像信息中提取。为了让因子分解机理解,首先需要将用户画像信息转化成特征向量。对于用户性别、年龄和学历等实值数据,直接将该值作为特征值。
电影维度特征:从电影信息中提取。在文中电影维度特征主要以电影类别为主,而电影类别除了与用户自然属性有关之外,还与用户的主题词有密切关系,用户的主题词总会触发特定类型的电影。(提取电影维度特征模型在论文中有提到)
显性特征:可以直接从用户和电影数据中获得。例如用户ID、电影ID
隐形特征:对用户行为数据以及电影数据进行深入挖掘、组合,从而提取到特征。例如电影类别、用户曾经评价的电影属于用户的显示反馈、用户的自然属性特征\用户-电影触发主题词(用户的主题词与电影的内容描述是有内在联系的词语)
输入数据格式转化:在进行模型训练前,需要对模型的输入数据进行格式转化,即对用户画像信息和待推荐电影信息进行有效特征编码,使之适用于 FM 这一基于特征的推荐模型,每一个特征维度对应一个低纬的隐含因子表示。
3.2.1 UP-FM模型训练
输入:用户画像特征集U 、电影特征集 M 、用户-电影触发主题词T 。
输出:中心用户对电影的点击率。
步骤 1 :从用户画像信息和电影信息中分别提取用户维度特征U 和电影维度特征M ,还包括触发主题词这一用户和电影共同的语义特征T 。
步骤 2 :为 UP-FM 模型输入进行多类别特征选择。
步骤 3 :将模型的输入数据转化为 LibFM 向量格式。
步骤 4 :采用 Adaptive SGD 训练用于用户-电影点击预测的 UP-FM 模型:

步骤 5 :重复步骤 4,直到模型参数达到最优。将训练得到的 UP-FM 模型用于测试集,得到中心用户对不同电影的点击率。
3.3 UP-FM小结
UP-FM 算法,既结合了 FM 模型刻画特征交互和较高质量预测大型稀疏矩阵的优点,又将用户画像引入进来,并且还引入触发主题词的概念,从语义方面有效的将用户画像特征和被推荐物品特征结合在一起。不仅解决了数据稀疏的问题,而且还考虑到了特征间的两两交互问题,提高了推荐的准确率。当面对新用户时,首先对新用户进行用户群体预测,然后根据不同用户群体对不同电影的点击率进行电影推荐,有效解决了冷启动问题。
参考:《基于用 户 画像和 因 子分解机的推荐算法研究》——杨 捷
四、CFM(基于交叉网络的因子分解机模型)
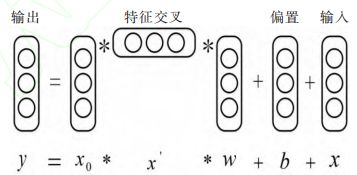
4.1 交叉网络(Cross Network)
交叉网络是人工神经网络模型的一种形式,其每一层的网络表达式如下:
其中分别表示交叉网络第层和第层的输出向量,表示该网络第层的权重和偏置参数。交叉网络一层结构如下图所示:
4.2 基于交叉网络的因子分解机模型
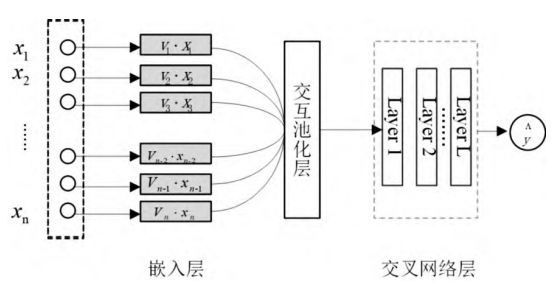
4.2.1 模型框架
整个模型由3个基本模块组成:因子分解机、交互池化层和交叉网络层。基于深度学习的高阶特征交互模型框架如下图所示:
给定一个输入数据,CFM模型的估计目标函数可以表示为:
式中前两项为因子分解机模型的线性部分,表示特征之间的高阶交互信息。
4.2.2 嵌入层
嵌入层是各维度特征到一个向量空间之间的映射,令为输入数据第个特征的嵌入表示。可以得到
4.2.3 交互池化层
将嵌入曾集合输入到交互层,一个将嵌入向量转换成一个向量的表达式:
其中表示向量对应元素的乘积,交互层的输出为一个维向量,编码了特征在嵌入空间的二阶交互信息。
4.2.4 交互网络层
将因子分解机模型的池化输出数据输入到多层交叉网络中。多层交叉网络定义如下:

其中,交叉网络的每层输出,其中为交叉网络层数。
4.2.5 预测层
将交叉网络的最后一层输出向量转化为最终预测:
其中,表示预测层的权重向量。因此,基于交叉
网络的因子分解机模型预测表达式为:
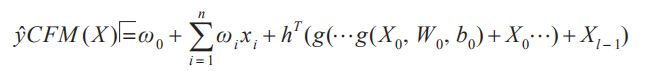
整个模型参数为:
4.3 小结
CFM 模型使用具有较低复杂度的交叉网络代替前馈神经网络,实验表明,CFM 模型具有很好的泛化性能。
参考:《神经因子分解机推荐模型改进研究》——吴韦俊、李烨
五、总结
FFM:
FFM在FM的基础上进一步改进,在模型中引入类别的概念,即field。FFM做得更精细,FM中每个特征对应一个隐变量,FFM每个特征对应多个隐变量。
UP-FM:
UP-FM 算法,将用户画像引入进来,并且还引入触发主题词的概念,从语义方面有效的将用户画像特征和被推荐物品特征结合在一起,提高了推荐的准确率。当面对新用户时,首先对新用户进行用户群体预测,然后根据不同用户群体对不同电影的点击率进行电影推荐,有效解决了冷启动问题。
CFM:
CFM属于神经因子分解机,CFM可以避免其他神经网络因子分解机(如NFM)复杂度较高的问题。 CFM 模型使用具有较低复杂度的交叉网络代替前馈神经网络,并且实验表明,CFM 模型具有很好的泛化性能。