Spark MLlib
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
MLlib(Machine Learnig lib) 是Spark对常用的机器学习算法的实现库,同时包括相关的测试和数据生成器。MLlib目前支持4种常见的机器学习问题: 分类、回归、聚类和协同过滤。在Spark官方首页中展示了Logistic Regression算法在Spark和Hadoop中运行的性能比较,如图下图所示。

本文基于经典的机器学习数据集iris,给出了Spark MLlib库中常见的分类器(朴素贝叶斯,决策树,随机森林,支持向量机,以及logistics回归)的应用实例。
Iris数据集
Iris数据集是常用的分类实验数据集,由Fisher, 1936收集整理。Iris也称鸢尾花卉数据集,是一类多重变量分析的数据集。数据集包含150个数据集,分为3类,每类50个数据,每个数据包含4个属性。可通过花萼长度,花萼宽度,花瓣长度,花瓣宽度4个属性预测鸢尾花卉属于(Setosa,Versicolour,Virginica)三个种类中的哪一类。
将样本中的4个特征两两组合(任选2个特征分别作为横轴和纵轴,用不同的颜色标记不同品种的花),可以构建12种组合(其实只有6种,另外6种与之对称),如图所示:

实验步骤
1.数据处理
Resilient Distributed Dataset(RDD) 弹性分布式数据集是Spark的核心数据结构。它是一个数据集,就像Array,List和Set等一样的数据结构。RDD的内容是平铺的,可以顺序遍历;RDD是分布式存储的,支持并行计算;RDD的分布是弹性的,某些操作会使不同的数据块重新汇聚和分布;RDD是只读的,可以通过重复计算获得(高可靠性);RDD可以缓存在内存中,故对迭代式计算效率更高。
LabeledPoint 标记点是Spark MLlib 分类模型API中的一种数据类型。它包含两个部分:标记位以及属性列表。属性列表从表现形式上来看可以是稀疏的,也可以是稠密的。创建LabeledPoint对象的python代码示例:
from pyspark.mllib.linalg import SparseVector
from pyspark.mllib.regression import LabeledPoint
pos = LabeledPoint(1.0, [1.0, 0.0, 3.0])
neg = LabeledPoint(0.0, SparseVector(3, [0, 2], [1.0, 3.0]))
Spark MLlib的分类器接受的输入数据是LabeledPoint类型的RDD,原始的数据集格式如下:
5.1,3.5,1.4,0.2,Iris-setosa
4.9,3.0,1.4,0.2,Iris-setosa
4.7,3.2,1.3,0.2,Iris-setosa
4.6,3.1,1.5,0.2,Iris-setosa
要想转换成LabeledPoint类型的RDD,由于LabeledPoint 的标记必须是整型的数,故首先需要将Iris-setosa,Iris-versicolour,Iris-virginica转化成0,1,2来表示。生成LabeledPoint类型RDD,有两种方式供选择:
1.利用loadLibSVMFile接口从LibSVM格式的文件读取数据。当然首先需要把原始的数据文件转换成LibSVM格式。LibSVM格式:
[label] [index1]:[value1] [index2]:[value2]
例如:0 1:5.1 2:3.5 3:1.4 4:0.2 ,表示训练用的特征有4维,第一维是5.1,第二维是3.5,第三维是1.4,第四维是0.2 ,目标值是0。将Iris数据集从原始格式转换成LibSVM格式的python代码:
file =open('E:\iris.data','r')
datas =list(map(lambda x:x.strip().split(","),file.readlines()))
file.close()
Output =''
for data in datas:
if data[4] =='Iris-setosa':
data[4] =0
elif data[4] == 'Iris-versicolor':
data[4]=1
else:
data[4] =2
out=str(data[4])+' '+'1:'+str(data[0])+' '+'2:'+str(data[1])+' '+'3:'+str(data[2])+' '+'4:'+str(data[3])+'\n'
Output +=out
file=open('E:\iris_libsvm.data','w')
file.write(Output)
file.close()
然后调用loadLibSVMFile接口就可以生成LabeledPoint类型的RDD了。
from pyspark.mllib.util import MLUtils
data = MLUtils.loadLibSVMFile(sc,'E:\iris_libsvm.data')
2.先用textFile 读取数据,然后对string类型的RDD调用map操作,转换成LabeledPoint类型的RDD:
sc =SparkContext("local[*]","classification")
def toLabeledPoint(line):
label =0
if line[-1] =='Iris-setosa':
label=0
elif line[-1]=='Iris-versicolor':
label=1
else:
label =2
return LabeledPoint(label,[float(i) for i in line[:-1]])
data =sc.textFile('E:\iris.data')
data =data.map(lambda line:toLabeledPoint(line.split(',')))
实践中根据需要选取任意一种方式即可。
2.训练模型及模型评估
实验中选取了朴素贝叶斯,决策树,随机森林,支持向量机,以及logistics回归共5种分类算法。采用留出法对建模结果评估,留出30%数据作为测试集,评估标准采用精度accuracy。由于不同模型,其调用接口过程类似,故以朴素贝叶斯为例,介绍使用Spark MLlib 进行分类的代码:
traindata,testdata = data.randomSplit([0.7,0.3])
# 朴素贝叶斯训练,评估
Bayesmodel = NaiveBayes.train(traindata,1.0)
predictionAndLabel_Bayes = testdata.map(lambda p :(Bayesmodel.predict(p.features),p.label))
accuracy_Bayes = 1.0*predictionAndLabel_Bayes.filter(lambda p1: p1[0]==p1[1]).count()/testdata.count()
值得注意的是:支持向量机(SVM),logistics回归是二分类的算法,由于本数据集有多个类别,所以本文利用了多个二分类分类器来实现多分类目标。在周志华的西瓜书中提到利用多个二分类器构造多分类的一般方法大致有3种:One vs. Rest,One vs. One,和Many vs. Many。本文利用One vs. One 的方法,基本思想:每一个分类器区分两个类别Ci 和Cj ;对于有n个类别的分类任务,需要构造n(n-1)/2个分类器;最终结果,投票产生。
#用多个SVM分类器实现多分类
model1 = SVMWithSGD.train(train0_1, iterations=1000)
model2 =SVMWithSGD.train(train0_2,iterations=1000)
model3 = SVMWithSGD.train(train1_2,iterations=1000)
predictions1 = model1.predict(testdata.map(lambda x :x.features))
predictions2 = model2.predict(testdata.map(lambda x :x.features))
predictions3 = model3.predict(testdata.map(lambda x :x.features))
true_label = testdata.map(lambda x :x.label).collect()
label_list1=predictions1.collect()
label_list2=predictions2.collect()
label_list3=predictions3.collect()
#投票产生结果
predict_label =[]
account =0
for index in range(len(true_label)):
dictionary ={0.0:0,1.0:0,2.0:0}
if label_list1[index] ==0:
dictionary[0.0] +=1
else:
dictionary[1.0]+=1
if label_list2[index] ==0:
dictionary[0.0]+=1
else:
dictionary[2.0] +=1
if label_list3[index] ==0:
dictionary[2.0]+=1
else:
dictionary[1.0]+=1
maxlabel = 0.0
for item in dictionary.keys():
if dictionary[item]>dictionary[maxlabel]:
maxlabel =item
if maxlabel==true_label[index]:
account+=1
predict_label.append(maxlabel)
accuracy_SVM =1.0*account/len(true_label)
由于单次运行结果可能不具备代表性,同样的代码循环10次,对比结果如下:
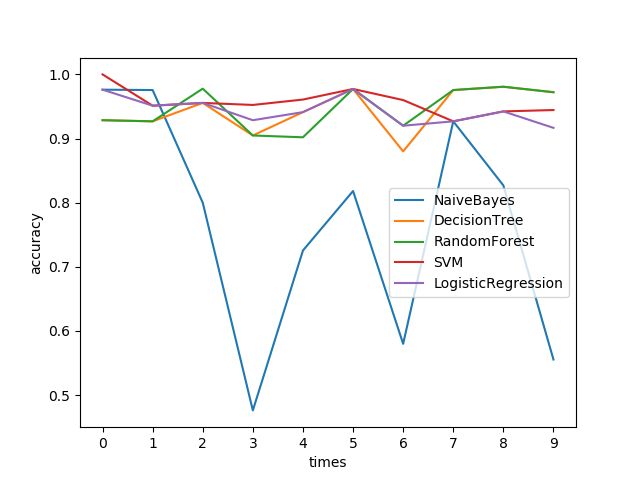
结果分析:除了朴素贝叶斯,其他的分类器精度基本上都在0.95附近,波动不大。朴素贝叶斯结果波动较大,与数据集的划分有很大关系:一共150条数据,70%用作训练,30%做测试,极端情况下30%的数据可能大部分都是某一类的。朴素贝叶斯是概率化的方法,依赖于训练集数据的分布,故产生这样的结果也是情理之中的事。