欢迎阅读数据库内核杂谈。这期我们先暂时抛开主线剧情,插播一期番外篇。话说为什么会有番外篇呢?上次休假写上一篇数据库杂谈-排序和聚合的时候正值Pinterest上市,小葡萄就问了一句“Pinterest上市啦!话说,写了这么多期数据库,那你知道Pinterest用的是什么数据库吗?”。“嗯,that's a very good question! 首先他们需要blah blah blah ...”,我开始一本正经地说... “太多啦,我不要听啦,要不你写一期Pinterest的数据库吧,算是数据库内核杂谈的番外篇?” 这一期,咱们就围绕着Pinterest有哪些数据要存储和处理,来聊聊Pinterest可能会用到的大数据系统。为了写这一期,我翻阅了一系列Pinterest的技术博客外加一些自己的理解。如有不当,欢迎拍砖和指正,尤其是Pinterest的朋友!
用户信息怎么存?
首先,Pinterest有很多用户,得有个系统存储这些用户信息。网上能查到的数字是超过250Million月活(写这篇文章的时候,月活肯定已经超过这个数字了)。用户信息,比如用户名,登陆信息,偏好等等是非常结构化的信息,属于非常典型的关系型数据库应用。那么多用户,你可能会觉得,需要很多台服务器再搭载分布式数据库才能存储。其实,做个简单计算,250M * 10KB(假设每个用户信息存放10KB,我已经很大方啦) = 2.5TB。一台安装关系型数据库(可选用受欢迎的开源数据库MySQL或者Postgres) Amazon x1e.32xlarge 服务器(搭载2块2TB硬盘)就可以勉强存下所有的用户数据啦。存是存下了,那么多用户的请求,一台服务器是否能处理过来呢?对于用户的请求分为读请求和写请求:读请求可以理解为用户登陆,需要确认登陆信息,这类请求的数量巨大;写请求可以理解为新用户注册或者现有用户更改信息。考虑到用户更改信息的频率不会太高以及网站已经比较知名,不太可能再出现短时间内大量新用户注册。而一台MySQL服务器至少能做到100K QPS(我找了很久,也没找到非常靠谱的benchmark,请读者赐教),所以,如果优化得好,一台服务器是勉强可以处理所有写请求的。对于读请求,其实很容易想到,虽然量巨大,但因为数据不变,没必要每次都从数据库读取,完全可以用Memcached或者Redis这类缓存来处理高并发请求。可见,并不是动不动就需要分布式数据库的。当然,我们的计算非常理想主义,完全没有考虑容错,备份,灾难恢复等。在现实情况下,Pinterest肯定会对用户信息做sharding(每个shard数据库只保存一部分用户信息),并且对每个shard还会有replica做备份(也可以用Master-slave模式,master负责处理所有的写请求,slave同步数据并且负责处理所有的读请求)。
Pin - Interest
Pinterest用户当然是来分享和浏览Pin的。Pin的主要格式为图片,动图(gif)或者视频格式。网上查到的数字是超过175Billion个Pin。假设每个Pin的大小是500KB(估算相对保守), 175Billion * 500KB = 87.5PB。OMG!87.5PB的数据。假设还是用前面提到的Amazon x1e.32xlarge, 要超过22000台服务器才能存下,还不算备份。Pin这类图片或者视频都是字节流文件,属于非格式化信息,一次写完后都不需要再改变,读取主要是通过key-value读取,属于典型的NoSQL应用。我大致搜索了Pinterest的技术博客,确实没有发现提到存储Pin用的是什么NoSQL系统,最像的可能就是Cassandra了。Cassandra是Facebook开源的key-value的NoSQL系统,源于Amazon的Dynamo系统,咱就不先细聊,以后单独一篇来讲。一言以蔽之,Cassndra通过一种叫consistent hashing的技术来维护一大群key-value服务器成为一个集群。每个服务器用来存储一部分的数据,任何服务器都能接受读请求,当所读数据不在本地时,会发送给有这个数据的服务器。虽然理论上是可以建立超大规模集群,但实际情况可能是一个集群有1000+左右的服务器。如此,即便每台服务器加载10块2T硬盘,一个1000+的Cassandra集群也只能存储20PB的数据,依然没有计算冗余备份。所以,如果Pinterest使用Cassndra存储Pin,那还需要在application层面再做一层sharding。这层sharding可能基于区域划分:不同数据中心存储各自新增的Pin,或者根据数据冷热划分:新鲜的数据都存放在一个集群,并且在每个数据中心都备这样一个集群,超级热的数据应该也会缓存到CDN上,冷数据单独存放因为读取需求不大。如果没有用开源的NoSQL系统,也可能是in-house自建了一个,就像Facebook的Haystack系统专门用来存储图片视频。
关注的背后是怎样的?
有了用户,用户能发Pin看Pin,还有什么信息需要保存呢?你可能会在Pinterest上关注了某网红(influencer),想第一时间看到她(他)发出的pin,需要follow她(他)。这层follower关系同样需要存储。这类信息也是非常结构化的信息,依然可以选择用关系型数据库来存储。或者也可以用图数据库(graph database)来存储。我个人感觉如果单单是follower关系,查询通常只需要针对直接follower信息,最多再加一次跳转用来推荐熟人或好友,因此并不需要用到特别复杂的图查询操作,其实关系型数据库已经可以很好地处理这种请求了。
搜索,推荐时,都发生了什么?
聊完Pin,用户和follow关系,读者可能觉得,数据大头都搞定啦。用户可以登陆,可以发pin,也可以第一时间浏览关注网红发的pin啦。真的是这样吗?打开app后,会给你一个可以无限下拉的下拉框,随着你不断下拉,持续刷新你关注的网红发的pin,这些pin多以时间排序,也可能根据相关度做微调。你可能会有疑问,如果每次打开App,浏览关注网红的pin,都要直接先从follow关系出发,找到关注账号,再去获取关注账号最新发布的pin,最后再聚合,排序发给你。即使前面所有的数据都已经放入缓存,也要花不少时间聚合,肯定会影响用户体验。到底是怎么实现的?至此,feed流系统闪亮登场。概括来讲,feed流系统的职责就是空间换时间,利用额外的资源提前把要发送给你的pin聚合好,当你发出请求时(甚至可以不定期主动推送),直接把结果发给你。一种实现的方法是,为活跃用户(如果不是活跃用户,当有请求发来再计算就好,同时也降低了资源的使用)维护一个固定的队列用来缓存最新需要推送的pin,当有关注账号发了新的pin后就推送到这个队列进行排序。然后根据请求把缓存的好的pin发给用户。
除了feed流应用,还有什么常见的需求?有读者肯定猜到了,搜索!用户通过搜索来找相关的pin。和搜索息息相关的另一个应用就是推荐。为了让你花费更多时间在app上(increase user engagement),系统会时不时地推荐一些它认为你感兴趣的东西。为什么说搜索和推荐特别相关呢?引用一句名人名言:搜索是有关键字的推荐,推荐是无关键字的搜索。而且很多相关技术都相通。对于搜索和推荐系统,读者可能会听到很多下面这些buzz word:用户画像,协同过滤,倒排索引,多轮打分等等。搜索和推荐系统本身就和数据库一样,是个非常复杂的系统。今天咱们就不跑题啦,有机会可以再作一期番外篇(有幸做过facebook搜索,知道些皮毛,可以和大家分享)。
点击Pin后,Pinterest都做了什么?
说了这么多关于feed流,搜索和推荐系统的事,我想引出的关键问题其实是要建立一个优秀的feed流,搜索或者推荐系统的重中之重在于(敲黑板!),需要收集大量的高质量的用户行为数据(当然是在用户知情并且允许的前提下)。读者可能会有疑问,哪些行为数据会对构建上述系统有帮助呢?举个例子,你对某个Pin的点击,在这个Pin停留了几秒,都隐式地反馈了你对这个Pin的喜爱程度,当然如果你选择转发,点赞,或者关注都显式地表达了你对这个Pin的喜爱。这个行为,不仅可以帮助系统完善对你的用户画像:假设这个Pin是体育相关,系统可能对于你是个体育爱好者这个维度上进行加分,也同时完善了这个Pin的信息:比如统计全球范围内被多少人喜欢,喜欢它的人都是什么类型等等。这些信息都会最终被推荐和搜索系统用来建模,训练生成机器学习模型来服务新的搜索和推荐需求。简而言之,任何形式的用户行为信息都可能对系统改进有帮助,所以当然是多多益善。这类信息多以事件或者log形式存在,定期地传回服务器端。这类数据有多大呢?我在一篇博客中看到,Pinterest每天会记录100TB的log(https://medium.com/@Pinterest_Engineering/scalable-and-reliable-data-ingestion-at-pinterest-b921c2ee8754) (这个数据应该除了用户数据还包括各种其他日志数据)。事件信息根据事件不同,所存储的属性也各不相同,因此并不适合用关系型数据库。除了数据量大,这类数据的另一个特点是会被不同的下游应用所需要。比如,对于Pin的点击事件,一小时最热榜说我需要这个数据实时地传输给我,方便我计算出上一个小时最受欢迎的pin。搜索系统说,我需要统计每个Pin在前90天总共的点击次数,不需要实时,每天发给我一次即可。除了手机端的用户数据,服务器端也会生成相关行为数据,这些数据也同时被不同应用所需要。于是,整个数据流变成了如下这么个复杂的交互:

怎么才能很好地解决这类量大,错综交错复杂,对实时性要求高的数据需求呢?Linkedin的大牛们发明了Kafka,一个分布式,高并发,低延时的消息发布订阅系统。所有的数据源都把数据以topic的形式在Kafka上发布,不同的应用只要订阅相关的topic来获取数据即可。Pinterest也使用了Kafka来处理分发log数据。有了Kafka,上述的交互就变得清爽多了,如下图所示:
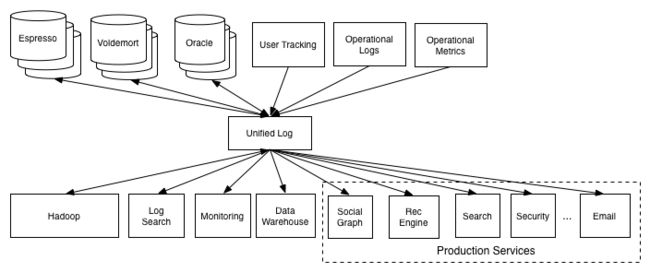
这里,我们也不展开讲Kafka,强烈推荐Kafka作者之一,Confluent公司CEO Jay Kreps的一篇博文:The log: What every software engineer should know about real-time data's unifying abstraction。
有了Kafka这个实时数据分发中心,我们再来看有哪些下游应用。一类应用属于实时类,这类应用数据量不会太大,但对延时要求高。现在特别火的流式处理系统(streaming processing)正好非常契合这类应用,比如Spark, Storm, Flink等,包括Kafka也在集成streaming的功能。数据从Kafka中取出,再流入这些系统的计算节点后,就能产生相应的结果而被使用。另一类实时性的数据系统称之为时序数据库系统(Timeseries Database),专门用来查询,展示和时序相关的数据。除了应用相关的数据比如实时的点击率,搜索次数,QPS变化等。另一个主要应用在于监控整个数据流和系统稳定性,比如服务器的带宽,CPU,内存使用等等。Pinterest一开始使用开源的OpenTSDB,后来自行开发了Goku。聊完了实时性要求高的,自然也有没那么紧迫的应用,也称batch job,频率一般是每天运行一次,对实时性要求并不高,可能几小时,或者只要保证24小时内能完成(不至于job一天一天不断积压)。但是数据量会特别大,比如搜索系统可能希望对前90天所有浏览过的pin统计浏览次数。流系统为了追求性能,数据处理多放在内存中,显然并不是很好的候选方案。这时,咱们的老朋友map reduce就该出场啦。Pinterest使用开源的Hadoop来支持大数据存储和处理。HIVE,基于Hadoop,提供了类似SQL的语法来省去程序员自己写map reduce job。一般的数据处理流程会被分成好几个阶段,这些阶段成DAG(directed acyclic graph)状。每个阶段会等待前一阶段的job完成,然后将这些job的输出(比如生成的HIVE table)作为这个阶段的输入。这类场景就是原来数据库应用里的ETL(extract, transform and load),只是传统的数据库可能处理不了这么大量的数据,才催生出了大数据产品。
除了上述两类,当然还会有数据量大,同时延时要求高的应用(人类真是贪得无厌呢!),比如,Data scientists可能会想要运行一些adhoc query来快速验证某些想法,如果这些query需要运行好几个小时,DS岂不是哭晕在厕所了。这就不得不搬出分布式OLAP数据库啦(终于说到老本行了)。Pinterest使用的是AWS提供的Redshift数据库。按照博客中写的,Redshift对于90%的查询语句能在120秒内完成,相对于HIVE的增速在50到100倍。不过同时也提到,使用Redshift并不是没有代价的,Redshift使用的是列存,存储方式和Hadoop不兼容,专门需要一个ETL job负责每天导出导入100TB的数据,同时还需要保证数据的完整和正确性。Facebook内部使用的是Presto,好处在于直接兼容HIVE数据格式。
上述提到的三种类型的应用,对应三种不同的数据系统,可以覆盖大部分的业务逻辑需求。不同的组根据自身业务不同,分别用对应的数据系统去实现自身的应用。比如,搜索系统的某些模块需要实时更新,可以使用流系统处理,而基数索引只需要每天更新,可以运行batch map reduce job来做统计。
数据安全和隐私保护
收集数据最终是为了能够更好地改进App,提供更好的用户体验。但必须强调,数据安全和隐私保护永远是第一位的。有哪些实践操作来保护数据安全和隐私呢?对数据进行加密和提高服务器安全性能可以很好地保护数据安全。对于用户隐私的保护,可以选择在收集用户行为数据时作随机采样,在基数足够的前提下,不会对应用或算法模型产生不良影响。就像Mark Zuckerberg说的,future is private。保护用户隐私一直是很火热的研究方向,如differential privacy,或者Google最近提到的federated training(把ML模型推送到device端做training和evaluation来避免敏感数据传回服务器端)。另一个实践是对于已经收集和存储的用户数据,设置一个table retention,如超过30天或90天后就删除原始数据。读者可能提问,只能保存90天是不是太短了。对于需要长期收集的信息,可以根据用户画像的维度作统计信息而不是保留原始数据。路漫漫其修远兮,我们都需要再接再厉!
总结
至此,我们结合Pinterest的业务和数据流图,讨论了它可能会用到的各种数据系统。要做好一个app,还有许多我们能想到的,不能想到的业务和逻辑,本文也只能从3000miles角度,概括地介绍各种系统。画了一张图,一起围绕这张图总结一下。

从App出发:
1)对于强一致,结构化的数据如用户信息等,使用关系型数据库存储
2)对于非结构化的数据如Pin的图片,视频,使用NoSQL系统存储
3)对于各种用户行为信息,app log,和服务器端log,用Kafka作消息分发订阅系统
4)下游应用,根据数据量和延时要求,又大致分为:
4.1)对数据量不大,延时要求高,采用流式系统或者时序数据库作实时数据处理
4.2)对数据量大,延时要求不高的应用,可以用Hadoop/HIVE作batch处理
4.3)对数据量大,同时有延时要求的,将数据导入到高性能的OLAP数据库作分析查询
5)对于不同业务逻辑需求,如搜索,feed,或者推荐,会根据需要采用4)中提到的方法来生成和消费相应数据
6)这些业务逻辑最终和app作交互
最后,贴一下Pinterest Engineering的blog地址:https://medium.com/@Pinterest_Engineering
以及文中提及的一些blogs:
https://medium.com/@Pinterest_Engineering/powering-interactive-data-analysis-by-redshift-b108c2ea9165
https://medium.com/@Pinterest_Engineering/building-pinalytics-pinterests-data-analytics-engine-e14c651780ca
https://medium.com/pinterest-engineering/looking-inside-the-technology-that-powers-pinterest-2e8bd1cfc329
https://medium.com/@Pinterest_Engineering/scalable-and-reliable-data-ingestion-at-pinterest-b921c2ee8754
https://medium.com/pinterest-engineering/goku-building-a-scalable-and-high-performant-time-series-database-system-a8ff5758a181
感谢阅读,下期,咱们回归主线,接着聊table join!