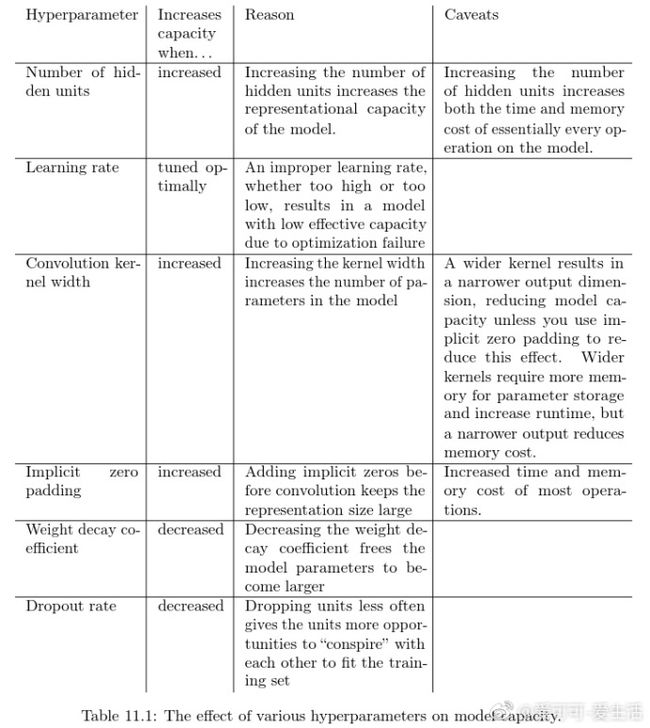
从各处窜来的系统性的调参方式和papers,为了做记录和总结,非原创。
一、参数角度
1.学习率
learning ratio从0.01到10的-6或-7就可以了
Contouring learning rate to optimize neural nets
large batch size与learning rate的关系?
理解深度学习中的学习率及多种选择策略
2.梯度
梯度裁剪:限制最大梯度 或者设置阀值,让梯度强制等于10,20等
梯度更新的步长:很重要,一般0.1是个万能数值。调参可改进结果,具体做法是人肉监督:用另外的验证集观察测试错误率,一旦不降了,步长减半甚至更多。
梯度归一化:除以minibatch size ,这样就不显式依赖minibatch size
限制权重参数最大值:防止跑飞,一般最大行范数不超过2或者4,否则同比收缩到这个值。梯度大致应该总是只改变参数的千分之一,偏离这个数字太远的,调之。
3.参数初始化
高斯,若某两层的梯度计算相差太大,就要调整小的那层的std了。
-可以先用随机初始化的方式训练一个简单的网络模型,再将训练好的权值初始化给复杂的网络模型,复杂的网络模型采用高斯初始化可能会更好(VGG)
-太小了,参数根本走不动。一般权重参数0.01均方差,0均值的高斯分布是万能的,不行就试更大的。偏差参数全0即可。
4.激活函数
-relu+bn
-relu一定要用
5.优化方法
SGD:[paper]When Does Stochastic Gradient Algorithm Work Well?
SGD+Momentum 效果往往可以胜过adam等,虽然adam收敛更快,据说初始几轮momentum设置的小一点会更好,这点待验证。用SGD ,minibatch size 128。或者更小size ,但那样吞吐量变小,计算效率变低。
用带momentum的SGD
带动量的随机梯度下降法
�Adam法
RMSprop法
Adadelta法
其中,RMSprop,Adadelta和Adam法都是一种自适应优化算法,因为它们会自动更新学习速率。如果使用普通的随机梯度下降法,你需要手动地选择学习率和动量参数,设置动量参数是为了随着时间的推移来不断地降低学习率。
在实践中,自适应优化器往往比普通的梯度下降法更快地让模型达到收敛状态。然而,选择这些优化器的模型最终性能通常都不太好,而普通的梯度下降法通常能够达到更好的收敛最小值,从而获得更好的模型性能,但这可能比某些优化程序需要更多的收敛时间。此外,随机梯度下降法也更依赖于有效的初始化方法和学习速率衰减指数的设置,这在实践中是很难确定的。
因此,如果你只是想快速地获得一些结果,或者只是想测试一个新的技术,自适应优化器将会是不错的选择。Adam是个容易上手的自适应优化器,因为它对初始学习率的设置没有很严格的要求,对于学习率的变化过程也并不是很敏感,因此非常利于深度学习模型的部署。如果你想获得模型的最优性能,可以尝试选择带动量的随机梯度下降法,并通过设置学习率,衰减率和动量参数来最大化模型的性能。
最近的研究表明,你可以混合地使用两类优化器:由Adam优化器过渡到随机梯度下降法来优化模型,能够获得最顶尖的训练模型!具体的做法是,在训练的早期阶段,往往是模型参数的初始化和调整非常敏感的时候。因此,我们可以使用Adam优化器来启动模型的训练,这将为模型的训练节省很多参数初始化和微调的时间。一旦模型的性能有所起伏,我们就可以切换到带动量的随机梯度下降法来进一步优化我们的模型,以达到最佳的性能!
6.数据预处理方式
白化
zero-center
输入输出数据做好归一化,以防出现数值问题。方法就是主成分分析啥的。
7.normal & batch
Weight Normalization 相比batch Normalization 优点
Batch normalization和Instance normalization
https://www.bilibili.com/video/av9770302/index_18.html#page=18
NTIRE2017夺冠的EDSR去掉了Batch Normalization层就获得了
YJango的Batch Normalization--介绍
深度学习中 Batch Normalization为什么效果好
Understanding the Disharmony between Dropout and Batch Normalization by Variance Shift:发现理解 Dropout 与 BN 之间冲突的关键是网络状态切换过程中存在神经方差的(neural variance)不一致行为
Layer Normalization:
rnn trick batch size=1效果会更好(待验证)real?
8.Dropout
Analysis of Dropout in Online Learning:https://arxiv.org/abs/1711.03343
二、模型表现角度
参数有一些是现在大家默认选择的,比如激活函数我们现在基本上都是采用Relu,而momentum一般我们会选择0.9-0.95之间,weight decay我们一般会选择0.005, filter的个数为奇数,而dropout现在也是标配的存在。这些都是近年来论文中通用的数值,也是公认出好结果的搭配。所以这些参数我们就没有必要太多的调整。下面是我们需要注意和调整的参数。
1. 完全不收敛
请检测自己的数据是否存在可以学习的信息,这个数据集中的数值是否泛化(防止过大或过小的数值破坏学习)。如果是错误的数据则你需要去再次获得正确的数据,如果是数据的数值异常我们可以使用zscore函数来解决这个问题(博客:http://blog.csdn.net/qq_20259459/article/details/59515182)。如果是网络的错误,则希望调整网络,包括:网络深度,非线性程度,分类器的种类等等。
2. 部分收敛
underfitting:
增加网络的复杂度(深度),降低learning rate,优化数据集,增加网络的非线性度(ReLu),采用batch normalization,
overfitting:
丰富数据,增加网络的稀疏度,降低网络的复杂度(深度),L1 /L2 regulariztion, 添加Dropout,Early stopping, 适当降低Learning rate,适当减少epoch的次数,
3. 全部收敛
调整方法就是保持其他参数不变,只调整一个参数。这里需要调整的参数会有:
learning rate, minibatch size,epoch,filter size, number of filter,(这里参见我前面两篇博客的相关filter的说明)
copy 自 http://blog.csdn.net/qq_20259459/article/details/70316511
三、learning to learning
1. 自动选模型+调参:谷歌AutoML背后的技术解析
ref:
1.训练的神经网络不工作?一文带你跨过这37个坑
主要是讲如何查问题的。
2.调参技巧大汇总
3.深度学习中训练参数的调节技巧