目录:
4.1基本流程
4.2划分选择
4.3剪枝处理
4.4连续与缺失值
4.5多变量决策树
4.1基本流程
决策树(decision tree)是一个树结构(可以是二叉树或者非二叉树)。决策树分为分类树和回归树两种,分类树对离散变量做决策树,回归树对连续变量做决策树。
其中每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放在一个类别。使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,知道到达叶子节点,将叶子节点存放的类别作为决策结果。
决策树学习的目的是为 了产生一棵泛化能力强,即处理未见示例能力强的决策树,其基本流程遵循简 单且直观的"分而治之" (divide-and-conquer)策略
决策树算法原理:(主要分为三个部分)
第一,特征选择
特征选择是指从训练数据中众多的特征中选择一个特征作为当前节点的分裂标准,如何选择特征有着很多不同量化评估标准,从而衍生出不同的决策树算法。
第二,决策树生成
根据选择的特征评估标准,从上至下递归地生成子节点,直到数据集不可分则停止决策树停止生长。树结构来说,递归结构是最容易理解的方式。
第三,决策树的剪枝
决策树容易过拟合,一般来需要剪枝,缩小树结构规则,缓解过拟合,剪枝技术有预剪枝和后剪枝两种。

决策树的生成是一个递归过程。在决策树基本算法中,有三种情形会 导致递归返回:
(1) 当前结点包含的样本全属于同一类别,无需划分;
(2) 当前 属性集为空,或是所有样本在所有属性上取值相同,无法划分;
(3) 当前结点包 含的样本集合为空,不能划分。
关于决策树学习基本算法的课外补充请参考深入学习决策树算法原理 -博客园
4.2划分选择
4.21信息增益
由算法 4.2 可看出7 决策树学习的关键是第 8 行,即如何选择最优划分属性(我们希望决策树的分支结点所包含的样 本尽可能属于同一类别,即结点的"纯度" (purity)越来越高.)
Claude Shannon 定义了熵(entropy)和信息增益(information gain)。 下面先介绍一下概念:
熵(entropy)
在信息论与概率论中,熵(entropy)用于表示“随机变量不确定性的度量”
在决策树的算法中,熵是一个非常非常重要的概念,一件事发生的概率越小,我们说它蕴含的信息量越大。
信息量熵的定义:
设X是一个有限状态的离散型随机变量,其概率分布为:
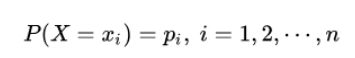
则随机变量X的熵定义为:
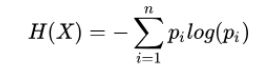
熵越大,则随机变量的不确定性越大。
当随机变量只有0和1两种取值的时候,假设P(X=1)=p,则有:
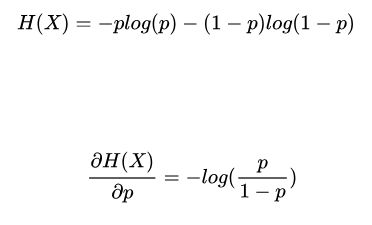
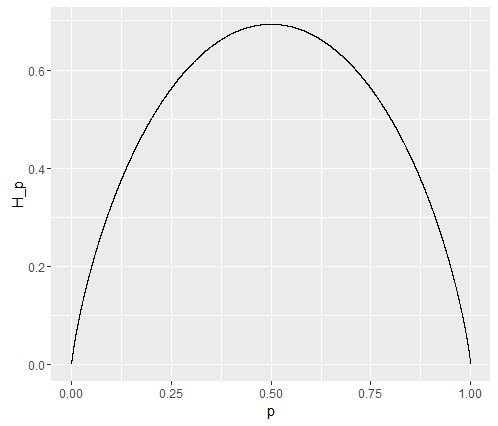
从而可知,当p=0.5时,熵取值最大,随机变量不确定性最大。如图:
同理,条件熵(conditional entropy):随机变量X给定的条件下,Y的条件概率分布的熵对X的数学期望
"信息熵" (information entropy)是度量样本集合纯度最常用的一种指标. 假定当前样本集合 D 中第 k 类样本所占的比例为 Pk (k = 1,2,. . . , IYI),则 D 的信息熵定义为:
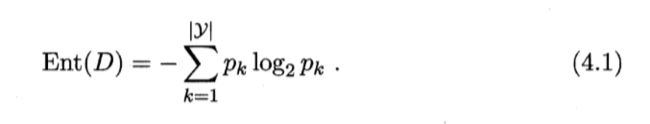
"信息增益"定义为:
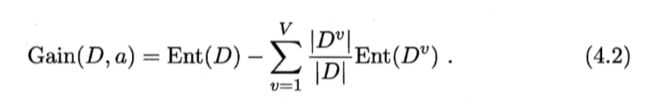
信息增益越大,则意味着使周属性 α 来进行划分所获得的"纯 度提升"越大
对于判断西瓜好坏问题上,属于二分类问题(Y=2),Pk,k=1(好瓜),k=2(不是好瓜),根结点包含 D 中的所有样例,其中正例占 P1 =8/17,反例占P2 =9/17;代入可得Ent(D)
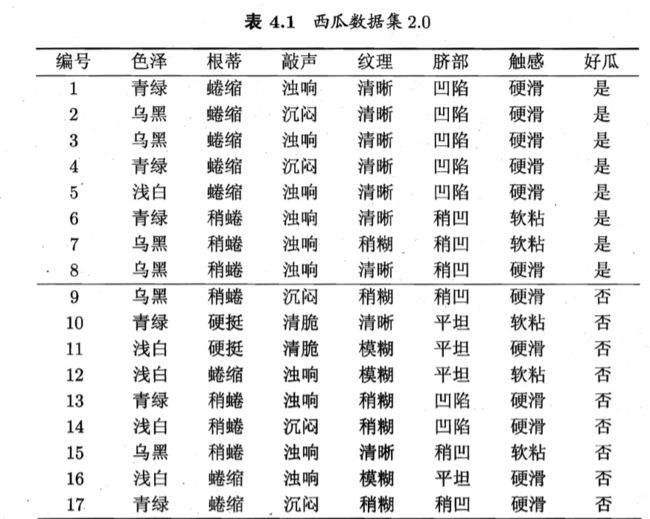
同理,若使用该属性对 D 进行划分,则可得到 3 个子集,分别记为: D1 (色泽=青绿), D2 (色泽2 乌黑), D3 (色泽=浅白).
子集 D1 包含编号为 {1,4, 6, 10, 13, 17} 的 6 个样例,其中正例占 p1=3/6, 反例占p2=3/6; D2 包含编号为 {2, 3, 7, 8, 9, 15} 的 6 个样例,其中正、反例分 别占 Pl = 4/6, P2 = 2/6; D3 包含编号为 {5, 11, 12, 14, 16} 的 5 个样例,其中正、 反例分别占 p1=1/5,p2=4/5.根据式(4.1)可计算出用"色泽"划分之后所获得 的 3 个分支结点的信息熵。Ent(D1)、Ent(D2)、Ent(D3)
于是,根据式(4.2)可计算出属性"色泽"的信息增益为:
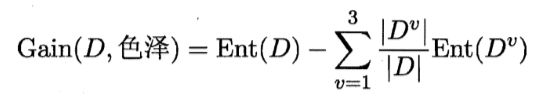
类似的,我们可计算出其他属性的信息增益:
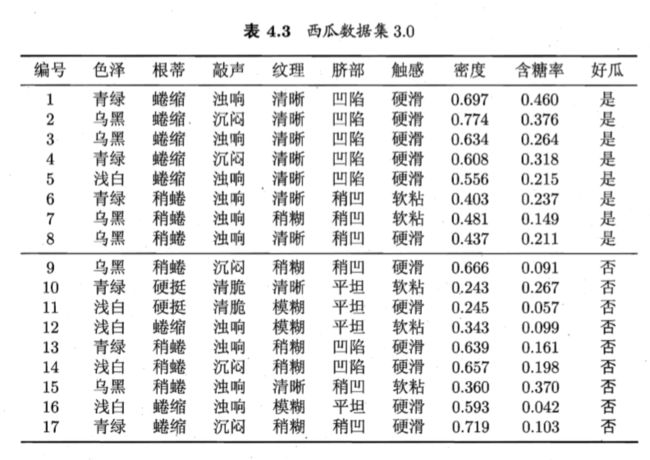
Gain(D,根蒂) = 0.143; Gain(D,敲声) = 0.141; Gain(D,纹理) = 0.381; Gain(D,脐部) = 0.289; Gain(D, 触感) = 0.006.显然,属性"纹理"的信息增益最大?于是它被选为划分属性.图 4.3 给出 了基于"纹理"对根结点进行划分的结果,各分支结点所包含的样例子集显示在结点中.
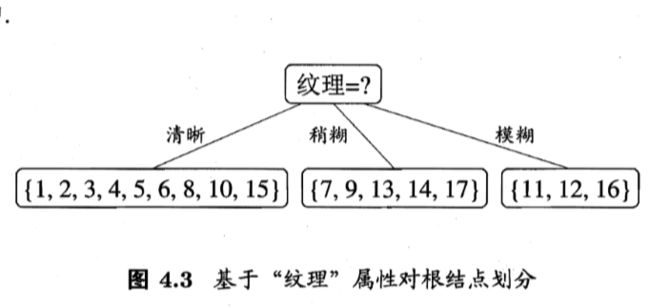
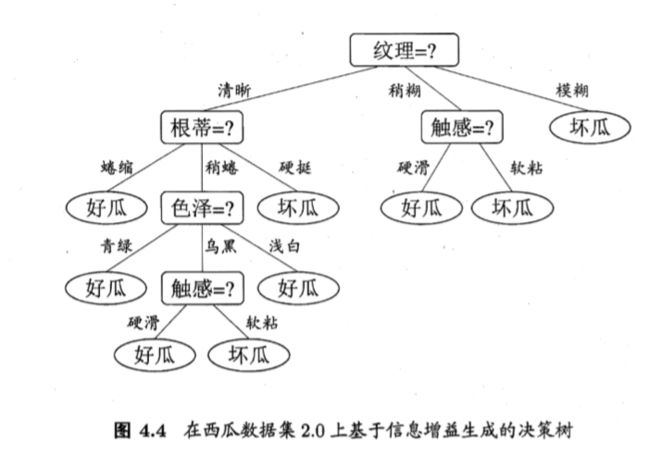
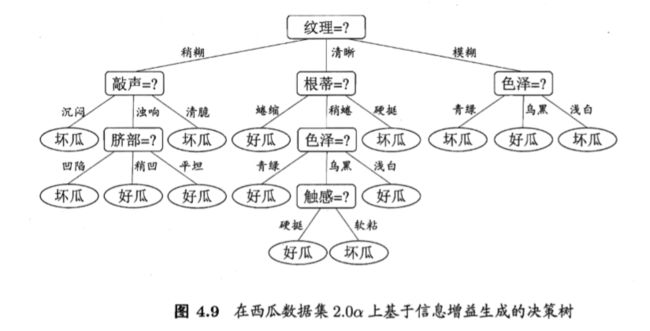
然后,决策树学习算法将对每个分支结点做进一步划分.以图 4.3 中第一 个分支结点( "纹理=清晰" )为例,该结点包含的样例集合 D1 中有编号为 {1,2, 3, 4, 5, 6, 8, 10, 15} 的 9 个样例,可用属性集合为{色泽,根蒂,敲声,脐部7,触感(因为“纹理”已经确定,就不用计算”纹理“)}.基于 D1 计算出各属性的信息增益;三个信息增益值最大的属性("根蒂"、 "脐部"、 "触感"),类似的,对每个分支结点进行上述操作,最终得到的 决策树如圈 4.4 所示.
小结:
基于数据信息生成决策树步骤:
1.算出以每个属性划分之后所获得的分支结点的信息熵,多少分支(多少个属性值)就多少个信息熵。(计算公式参考公式4.1)
2.从而算出每个属性的信息增益(计算公式参考公式4.2)
3.求出信息增益最大的那个属性为根节点,对每个分支结点做进一步划分。以其属性值分类,重复上面两步的方法,算出各分支最大信息增益的属性(不用算上一分支的属性)
4.类似的,层层算出,对每个分支结点进行上述操作,最终得到决策树。
增益率:

称为属性 α 的"固有值" (intrinsic value) [Quinlan, 1993J. 属性 α 的可能 取值数目越多(即 V 越大),则 IV(α) 的值通常会越大。
基尼指数
直观来说, Gini(D) 反映了从数据集 D 中随机抽取两个样本,其类别标记 不一致的概率.因此, Gini(D) 越小,则数据集 D 的纯度越高.
采用与式(4.2)相同的符号表示,属性 α 的基尼指数定义为:
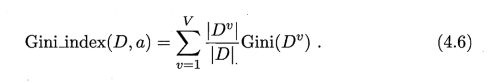
4.3 剪枝处理
剪枝(pruning)是决策树学习算法对付"过拟合"的主要手段,决策树剪枝的基本策略有"预剪枝" (prepruning)和"后剪枝"(post" pruning) [Quinlan, 1993].
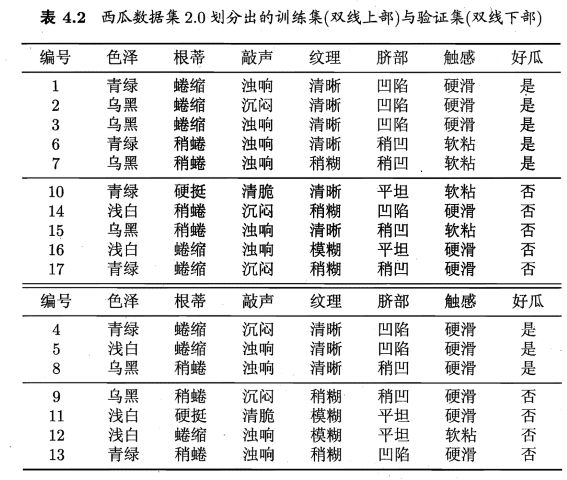
本节假定采用留出法,即预留一部分数据用作"验证集"以进行性 能评估.例如对表 4.1 的西瓜数据集 2札我们将其随机划分为两部分:
4.3.1 预剪枝
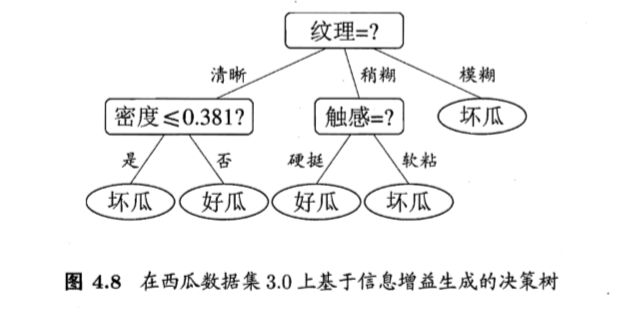
我们先讨论预剪枝.基于信息增益准则,我们会选取属性"脐部"来对训 练集进行划分,并产生 3 个分支。在划分之前,所有样例集中在根结点.若不进行划分,则根据算法 4.2 第 6 行,该结点将被标记为叶结点,其类别标记为训练样例数最多的类别,假设我们将这个叶结点标记为"好瓜"用表 4.2 的验证集对这个单结点决策树进行评估?则编号为 {4,5,8} 的样例被分类正确?另外 4 个样例分类错误,于是,验证集精度为3/7 x 100% = 42.9%
在用属性"脐部"划分之后,图 4.6 中的结点②、③、④分别包含编 号为 {1, 2, 3, 14}、 {6, 7, 15, 17}、 {10, 16} 的训练样例,因此这 3 个结点分别 被标记为叶结点"好瓜"、 "好瓜"、 "坏瓜"此时,验证集中编号为 {4, 5, 8,11, 12} 的样例被分类正确,验证集精度为5/7 x 100% = 71.4% > 42.9% 于是,用"脐部"进行划分得以确定.
然后,决策树算法应该对结点②进行划分,基于信息增益准则将挑选出划 分属性"色泽"然而,在使用"色泽"划分后,计算各叶节点的验证集精度,与划分前比较。若精度大于划分前的,则进行下一级划分,反之则终止划分。
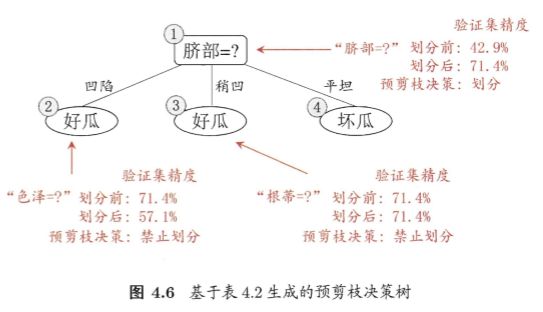
优点:预剪枝不仅降低的过拟合的风险,还减少了决策树训练时间和测试时间的开销。
缺点:有些分支的当前划分虽不能提升泛化性能、甚至可能导致泛化性能暂时下降?但在其基础上进行的后续划分却有可能导致性能显著提高; 预剪枝基于"贪心"本质禁止这些分支展开,给预剪枝决策树带来了 欠拟含的风险。
4.3.2 后剪枝
后剪枝先从训练集生成一棵完整决策树?例如基于表 4.2 的数据我们得到 如图 4.5 所示的决策树.易知, 该决策树的验证集精度为 42.9%。
后剪枝首先考察图 4.5 中的结点⑥.若将其领衔的分支剪除,则相当于 把⑤替换为叶结点.替换后的叶结点包含编号为 {7, 15} 的训练样本,于是,该叶结点的类别标记为"好瓜",此时决策树的验证集精度提高至 57.1%. 于是, 后剪枝策略决定剪枝,如图 4.7 所示:
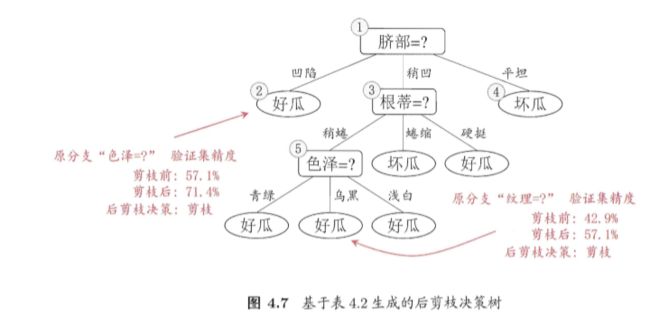
然后考察结点⑤,若将其领衔的子树替换为叶结点,则替换后的叶结点包含编号为 {6, 7, 15} 的训练样例,叶结点类别标记为"好瓜',此时决策树验证集精度仍为 57.1%.。于是,可以不进行剪枝.
以此类推,直到剪到结点①。
优点:后剪枝决策树的欠拟合风险很小,泛化性能往往优于预 剪枝决策树
缺点:后剪枝过程是在生成完全决策树之后进行的, 并且要自底向上地对树中的所有非叶结点进行逐一考察,因此其训练时间开销比未剪枝决策树和预剪枝决策树都要大得多。
4.4连续与缺失值
4.4.1 连续值处理
给定样本集 D 和连续属性 α,假定 α 在 D 上出现了 n个不同的取值,将这 些值从小到大进行排序,记为 {α1 α2 . . , an},在区间[ai, ai+1) 中取任意值所产生的划分结果相同。因此,对连续属性 a, 我们可考察包含 n-1 个元素的候选划分点集合。即把区间 [ai, ai+1) 的中位点{(ai+ai+1)/2 }出作为候选划分点。
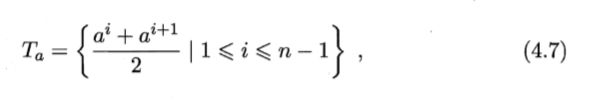
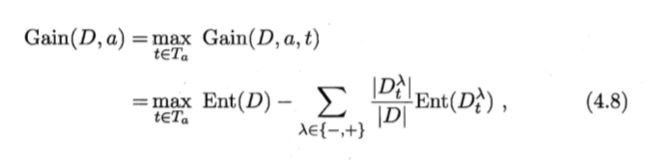
对属性"密度",,该属性的候选划分点集合包含 16 个候选值: T密度 {0.244, 0.294, 0.351, 0.381, 0.420, 0.459, 0.518, 0.574, 0.600, 0.621, 0.636, 0.648, 0.661, 0.681, 0.708, 0.746}。 由式(4.8) 可计算 出属性"密度"的信息增益为 0.262,对应于划分点 0.381(根据表中是否好瓜的最小临界值求出)。
同理,对属性"含糖率"其候选划分点集合也包含 16 个候选值:'L含糖率=
{0.049, 0.074, 0.095, 0.101, 0.126, 0.155, 0.179, 0.204, 0.213, 0.226, 0.250, 0.265, 0.292, 0.344, 0.373, 0.418}. 类似的,根据式(4.8)可计算出其信息增益为 0.349, 对应于划分点 0.126。(根据表中是否好瓜的最小临界值求出)
接下来,根据第二节学习的方法步骤(离散型),求出决策树。
需注意的是,与离散属性不同,若当前结点划分属性为连续属性,该属性还 可作为其后代结点的划分属性。例如在父结点上使用了 "密度'<=0.381" ,不会禁 止在子结点上使用"密度<=0.294" 。
4.4.2 缺失值处理
如果简单地放弃不完整样本,仅使用无缺失值的样本来进行学习,显然是对数据信息极大的浪费。
我们需解决两个问题: (1) 如何在属性值缺失的情况 下进行划分属性选择? (2) 给定划分属性,若样本在该属性上的值缺失,如何对样本进行划分?
给定训练集 D 和属性 α,令 D 表示 D 中在属性 α 上没有缺失值的样本子 集。对问题(1),显然我们仅可根据 b 来判断属性 α 的优劣.假定属性 α 有 V 个 可取值 {α1,α2 …, αV}, 令 D~V 表示 D ~中在属性 a上取值为av的样本子集,D~k 表示 b 中属于第 k 类 (k = 1,2, .. . , lyl)的样本子集。

对属性 α, ρ 表辰无缺失值样本所占的比例, Pk 表示无缺失值样本中 第 k 类所占的比例?ι 则表示无缺失值样本中在属性 α 上取值旷的样本所占的比例。

根结点包含样本集 D 中全部 17 个样例,各样例的权值 均为1.以属性"色泽"为例,该属性上无缺失值的样例子集 b 包含编号为 {2, 3, 4, 6, 7, 8, 9, 10, 11, 12, 14, 15, 16, 17} 的 14 个样例.显然,D~的信息熵为Ent(D~),再求出子集Ent(D1)、Ent(D2)、Ent(D3),求得Gain(D~,属性),最后求得属性信息增益Gain(D,属性)=p(完整的占全部的比例)*Gain(D~,属性)
求得各属性的信息增益后,再根据前面的方法,划分过程递归执行,求得决策树。
小结:
信息增益的三个表达式:
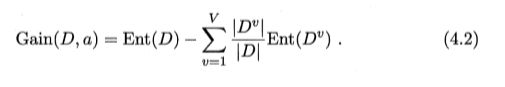
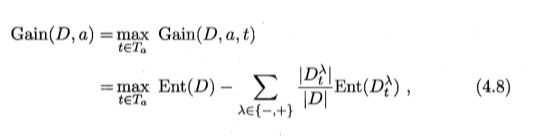
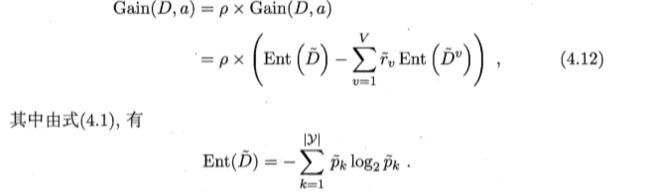
4.5 多变量决策树
若我们把每个属性视为坐标空间中的一个坐标轴,则 d 个属性描述的样本 就对应了 d 维空间中的一个数据点。
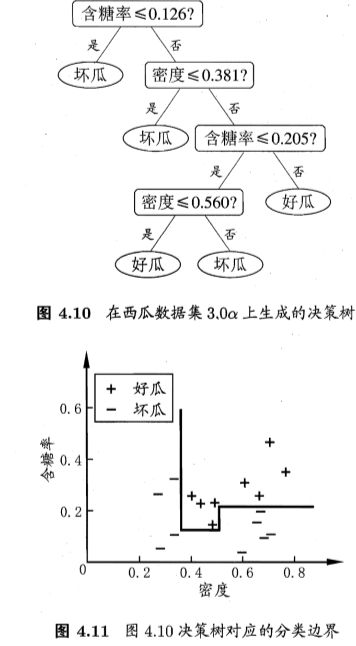
若能使用斜的划分边界,如图 4.12 中红色线段所示,则决策树模型将大为 简化"多变量决策树" (multivariate decision tree),非叶结点不再是仅对某个属性,而是对属性的线性组合进行测试。
每个非叶结点是一个形如叫线性分类器,其中是属性的权重,和 t 可在该结点所含的样本集和属性集上学得.
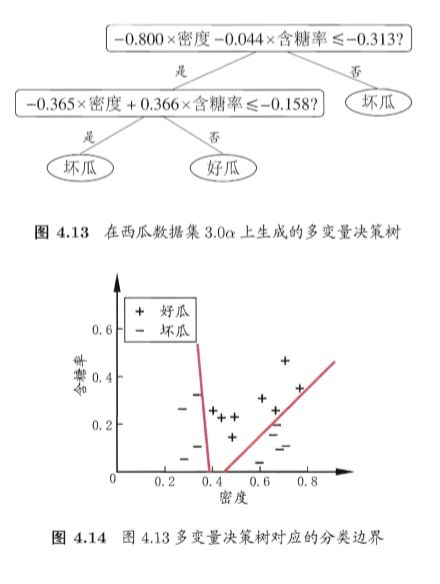
在多变量决策树的学习过程中, 不是为每个非叶结点寻找一个最优划分属性,而是试图建立一个合适的线性分类器。
详细了解线性学习器,请点击CS231n——机器学习算法——线性分类(上: 线性分类器)