什么是Spring IOC / DI
大家都知道,Spring是一个管理Bean的容器,IOC承担着控制反转的责任,不论是我们之前单纯使用Spring框架去管理Bean还是之后接触到的SSM框架,再到SpringBoot中的IOC承担更大的责任,管理的是整个应用需要使用到的Bean,我喜欢把Spring组成的一系列体系叫做生态圈,IOC容器就相当于是生态圈中的户籍登记处,管理着每一个Bean
依赖注入,依赖注入的场景在使用Spring开发的时候程序员都经历过,之前仅仅停留在Java语言的角度上的时候,我们使用的一切对象都是需要我们自己new出来的,这种方式称为主动创建对象,而使用Spring的DI注入之后配合着IOC的控制反转,我们之前主动创建对象的操作,交由给Spring容器去管理,并且之后通过DI注入所需的依赖,简单地来说,使用了Spring的IOC和DI之后,将不用程序员自己去管理一个实例的生命周期,并且交由Spring管理的Bean可以通过Scope字段去设置Bean的模式,例如单例模式,以及设置一个Bean创建的作用域
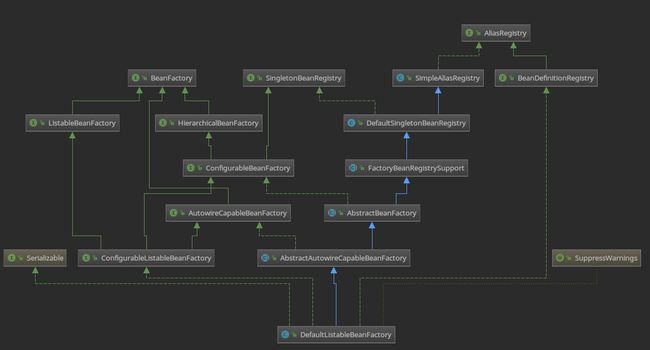
BeanFactory
其中BeanFactory作为最顶层的一个接口类,它定义了IOC容器的基本功能规范,BeanFactory 有三个子类:ListableBeanFactory、HierarchicalBeanFactory 和AutowireCapableBeanFactory。
那为何要定义这么多层次的接口呢?查阅这些接口的源码和说明发现,每个接口都有他使用的场合,它主要是为了区分在 Spring 内部在操作过程中对象的传递和转化过程中,对对象的数据访问所做的限制。
ListableBeanFactory 接口表示这些 Bean 是可列表的
HierarchicalBeanFactory 表示的是这些 Bean 是有继承关系的,也就是每个Bean 有可能有父 Bean
AutowireCapableBeanFactory 接口定义 Bean 的自动装配规则
这四个接口共同定义了 Bean 的集合、Bean 之间的关系、以及 Bean 行为,但是从上图中我们可以发现最终的默认实现类是 DefaultListableBeanFactory,他实现了所有的接口。
在这篇总结中将不会贴出源码,因为一个是量多,一个是源码中藏着的注释比较多,篇幅可能会很大,在接下来的说明中将只会阐述主要的观点
public interface BeanFactory {
//用于取消引用实例并将其与FactoryBean创建的bean区分开来。例如,如果命名的bean是FactoryBean,则获取将返回Factory,而不是Factory返回的实例。
String FACTORY_BEAN_PREFIX = "&";
//根据bean的名字,获取在IOC容器中得到bean实例
Object getBean(String name) throws BeansException;
//根据bean的名字和Class类型来得到bean实例,如果想要获取的bean实例的name与传入的类型不符将会抛出异常
Object getBean(String name, Class requiredType) throws BeansException;
//根据bean的name获取这个bean,允许指定显式的构造参数,覆盖bean定义中缺省的构造参数
Object getBean(String name, Object... args) throws BeansException;
//返回唯一匹配给定对象类型的bean实例(如果有)
T getBean(Class requiredType) throws BeansException;
//返回唯一匹配给定对象类型的bean实例(如果有),并且指定bean的构造参数
T getBean(Class requiredType, Object... args) throws BeansException;
//返回指定bean的Provider,允许对实例进行惰性按需检索,包括可用性和唯一性选项
ObjectProvider getBeanProvider(Class requiredType);
//返回指定bean的Provider,参数为可解决的类型,这种类型可以更好的支持传入类型的各种方法,包括泛型
ObjectProvider getBeanProvider(ResolvableType requiredType);
//检查工厂中是否包含给定name的bean,或者外部注册的bean
boolean containsBean(String name);
//检查所给定name的bean是否为单例
boolean isSingleton(String name) throws NoSuchBeanDefinitionException;
//检查所给定name的bean是否为原型
boolean isPrototype(String name) throws NoSuchBeanDefinitionException;
//判断所给name的类型与type是否匹配
boolean isTypeMatch(String name, ResolvableType typeToMatch) throws NoSuchBeanDefinitionException;
//判断所给name的类型与type是否匹配
boolean isTypeMatch(String name, Class typeToMatch) throws NoSuchBeanDefinitionException;
//获取给定name的bean的类型
@Nullable
Class getType(String name) throws NoSuchBeanDefinitionException;
//返回给定name的bean的别名
String[] getAliases(String name);
}
补充部分
Improved programmatic resolution of dependencies
Spring Framework 4.3 also introduces ObjectProvider, an extension of the existing ObjectFactory interface with handy signatures such as getIfAvailable and getIfUniqueto retrieve a bean only if it actually exists (optional support) or if a single candidate can be determined (in particular: a primary candidate in case of multiple matching beans).
@Service
public class FooService {
private final FooRepository repository;
public FooService(ObjectProvider repositoryProvider) {
this.repository = repositoryProvider.getIfUnique();
}
}
You may use such an ObjectProvider handle for custom resolution purposes during initialization as shown above, or store the handle in a field for late on-demand resolution (as you typically do with an ObjectFactory).
上述文档是Spring官方文档中的一部分,可以看到当需要使用注入IOC中bean的时候,我们可以使用ObjectProvider针对注入点进行一些处理,比如是否存在该bean或者是否可用以及是否唯一
上面代码是BeanFactory接口的抽象方法的声明,BeanFactory的子类有很多,其中DefaultListableBeanFactory是整个bean加载的核心部分
而要知道工厂是如何产生对象的,我们需要看具体的IOC容器实现,spring提供了许多IOC容器的实现。比如XmlBeanFactory,ClasspathXmlApplicationContext等
其中XmlBeanFactory就是针对最基本的IOC容器的实现,这个IOC容器可以读取XML文件定义的BeanDefinition(XML文件中对bean的描述),XmlBeanFactory在5.1.2版本中已被声明为不希望继续被使用
ApplicationContext是Spring提供的一个高级的IoC容器,它除了能够提供IoC容器的基本功能外,还为用户提供了以下的附加服务。
支持信息源,可以实现国际化。(实现MessageSource接口)
访问资源。(实现ResourcePatternResolver接口)
支持应用事件。(实现ApplicationEventPublisher接口)
BeanDefinition
Spring IOC容器管理我们声明的各种bean之间的关系,bean的实例在Spring的实现中是以BeanDefinition来描述的

xml文件的读取是Spring中的重要功能,bean的解析过程很复杂,功能也同样被划分得很细,其中的解析过程主要由下列的类去完成

XmlBeanFactory流程 已被声明为不建议使用
@SuppressWarnings({"serial", "all"})
public class XmlBeanFactory extends DefaultListableBeanFactory {
private final XmlBeanDefinitionReader reader = new XmlBeanDefinitionReader(this);
/**
* Create a new XmlBeanFactory with the given resource,
* which must be parsable using DOM.
* @param resource the XML resource to load bean definitions from
* @throws BeansException in case of loading or parsing errors
*/
public XmlBeanFactory(Resource resource) throws BeansException {
//调用第二个构造器传入这个Resource实例,即传入转换后的Xml文件资源
this(resource, null);
}
/**
* Create a new XmlBeanFactory with the given input stream,
* which must be parsable using DOM.
* @param resource the XML resource to load bean definitions from
* @param parentBeanFactory parent bean factory
* @throws BeansException in case of loading or parsing errors
*/
public XmlBeanFactory(Resource resource, BeanFactory parentBeanFactory) throws BeansException {
//调用父类构造器传入一个父bean工厂
super(parentBeanFactory);
//加载bean的定义(这里的定义其实就是解析Xml文件装配一个Bean)
this.reader.loadBeanDefinitions(resource);
}
}
接下来看一下具体的加载逻辑
/**
* Load bean definitions from the specified XML file.规定的XML文件
* @param resource the resource descriptor for the XML file
* @return the number of bean definitions found
* @throws BeanDefinitionStoreException in case of loading or parsing errors
*/
@Override
public int loadBeanDefinitions(Resource resource) throws BeanDefinitionStoreException {
return loadBeanDefinitions(new EncodedResource(resource));
}
上述方法返回值为一共解析出了多少个bean的信息
/**
* Load bean definitions from the specified XML file.
* @param encodedResource the resource descriptor for the XML file,
* allowing to specify an encoding to use for parsing the file
* @return the number of bean definitions found
* @throws BeanDefinitionStoreException in case of loading or parsing errors
*/
public int loadBeanDefinitions(EncodedResource encodedResource) throws BeanDefinitionStoreException {
Assert.notNull(encodedResource, "EncodedResource must not be null");
//是否启用跟踪log
if (logger.isTraceEnabled()) {
logger.trace("Loading XML bean definitions from " + encodedResource);
}
//获取当前正在被加载的Xml中bean定义的Set
Set currentResources = this.resourcesCurrentlyBeingLoaded.get();
if (currentResources == null) {
//若正在被加载的bean的资源Set为空 则初始化
currentResources = new HashSet<>(4);
this.resourcesCurrentlyBeingLoaded.set(currentResources);
}
//Set在add时出现重复会返回false 则抛出循环加载
if (!currentResources.add(encodedResource)) {
throw new BeanDefinitionStoreException(
"Detected cyclic loading of " + encodedResource + " - check your import definitions!");
}
try {
//获取Xml资源的输入流
InputStream inputStream = encodedResource.getResource().getInputStream();
try {
InputSource inputSource = new InputSource(inputStream);
//判断原始资源的编码为InputSource设置编码
if (encodedResource.getEncoding() != null) {
inputSource.setEncoding(encodedResource.getEncoding());
}
return doLoadBeanDefinitions(inputSource, encodedResource.getResource());
}
finally {
inputStream.close();
}
}
catch (IOException ex) {
throw new BeanDefinitionStoreException(
"IOException parsing XML document from " + encodedResource.getResource(), ex);
}
finally {
//从正在加载的Set中移除这个Xml资源
currentResources.remove(encodedResource);
if (currentResources.isEmpty()) {
this.resourcesCurrentlyBeingLoaded.remove();
}
}
}
接下来进一步看解析Xml的过程
/**
* Actually load bean definitions from the specified XML file.
* @param inputSource the SAX InputSource to read from
* @param resource the resource descriptor for the XML file
* @return the number of bean definitions found
* @throws BeanDefinitionStoreException in case of loading or parsing errors
* @see #doLoadDocument
* @see #registerBeanDefinitions
*/
protected int doLoadBeanDefinitions(InputSource inputSource, Resource resource)
throws BeanDefinitionStoreException {
//将Xml文件资源转换为Document对象
Document doc = doLoadDocument(inputSource, resource);
//注册Document对象的所有声明的bean
int count = registerBeanDefinitions(doc, resource);
if (logger.isDebugEnabled()) {
logger.debug("Loaded " + count + " bean definitions from " + resource);
}
//返回新注册bean的数量
return count;
}
/**
* 注册Xml中bean的定义
* Register the bean definitions contained in the given DOM document.
* Called by {@code loadBeanDefinitions}.
* Creates a new instance of the parser class and invokes
* {@code registerBeanDefinitions} on it.
* @param doc the DOM document
* @param resource the resource descriptor (for context information)
* @return the number of bean definitions found
* @throws BeanDefinitionStoreException in case of parsing errors
* @see #loadBeanDefinitions
* @see #setDocumentReaderClass
* @see BeanDefinitionDocumentReader#registerBeanDefinitions
*/
public int registerBeanDefinitions(Document doc, Resource resource) throws BeanDefinitionStoreException {
BeanDefinitionDocumentReader documentReader = createBeanDefinitionDocumentReader();
//获取之前IOC容器中已经注册过的bean
int countBefore = getRegistry().getBeanDefinitionCount();
//解析Xml资源,注册其中配置的bean
documentReader.registerBeanDefinitions(doc, createReaderContext(resource));
//返回新注册bean的数量
return getRegistry().getBeanDefinitionCount() - countBefore;
}
/**
* Register each bean definition within the given root {@code elements will cause recursion in this method. In
// order to propagate and preserve default-* attributes correctly,
// keep track of the current (parent) delegate, which may be null. Create
// the new (child) delegate with a reference to the parent for fallback purposes,
// then ultimately reset this.delegate back to its original (parent) reference.
// this behavior emulates a stack of delegates without actually necessitating one.
BeanDefinitionParserDelegate parent = this.delegate;
this.delegate = createDelegate(getReaderContext(), root, parent);
if (this.delegate.isDefaultNamespace(root)) {
//获取profile节点
String profileSpec = root.getAttribute(PROFILE_ATTRIBUTE);
//判断profileSpec中是否包含空串或空白字符或者为null包含的话返回false
if (StringUtils.hasText(profileSpec)) {
//将profileSpec使用,;分隔成数组
String[] specifiedProfiles = StringUtils.tokenizeToStringArray(
profileSpec, BeanDefinitionParserDelegate.MULTI_VALUE_ATTRIBUTE_DELIMITERS);
// We cannot use Profiles.of(...) since profile expressions are not supported
// in XML config. See SPR-12458 for details.
//判断是否有profile被激活
if (!getReaderContext().getEnvironment().acceptsProfiles(specifiedProfiles)) {
if (logger.isDebugEnabled()) {
logger.debug("Skipped XML bean definition file due to specified profiles [" + profileSpec +
"] not matching: " + getReaderContext().getResource());
}
return;
}
}
}
preProcessXml(root);
//重头戏来了,从这里开始接下来的逻辑全都是在解析Xml
parseBeanDefinitions(root, this.delegate);
postProcessXml(root);
this.delegate = parent;
}
上面逻辑会看到有一些环境的字眼
如!getReaderContext().getEnvironment().acceptsProfiles(specifiedProfiles)
熟悉配置bean的人应该能理解profile的作用,既然需要满足profile的作用就需要读取环境变量进行对环境变量的判空,并且判断解析出来的profile是不是环境变量中所定义的
主要解析的类为DefaultBeanDefinitionDocumentReader
其中声明了大量的常量,这些常量都是Xml在配置bean的时候允许的语法标记,可以想象得到正是通过这个类实现的解析逻辑