https://www.cnblogs.com/lillylin/p/6102708.html
Xiang Bai——【CVPR2016】Multi-Oriented Text Detection with Fully Convolutional Networks
目录
作者和相关链接
方法概括
方法细节
创新点和贡献
实验结果
问题讨论
总结与收获点
作者和相关链接
作者:

paper下载
代码下载
方法概括
Step 1——文本块检测: 先利用text-block FCN得到salient map,再对salient map进行连通分量分析得到text block;
Step 2——文本线形成: 对text-block利用MSER提取候选字符区域,利用候选字符区域估计整个block的方向,再结合候选字符的bounding box生成每个每条文本行;
Step 3——文本线过滤: 利用centroid FCN得到每条文本行中的字符的质心,利用质心过滤非文本行;
以下为细化的每个步骤示例图:


Figure 1. The procedure of the proposed method. (a) An input image; (b) The salient map of the text regions predicted by the TextBlock FCN; (c) Text block generation;
(d) Candidate character component extraction; (e) Orientation estimation by component projection; (f) Text line candidates extraction; (g) The detection results of the proposed method.
方法细节
text blcok 检测
Text-block FCN的网络结构
选用VGG16的前5层卷积层,去掉后面的全连接层。在每个卷积层后都接上一个deconv操作(由1*1的卷积+上采样构成)。再把5个deconv得到的maps用1*1的卷积进行 fusion,并经 过一个sigmoid层得到salient map。
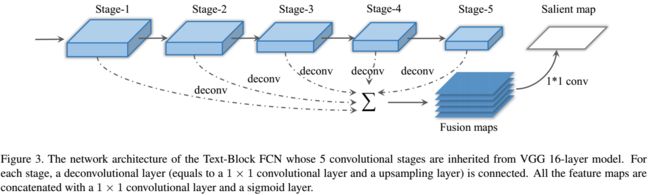
Text-block FCN生成salient map的示例图
从第1层到第5层的细节越来越少,global的信息越来越强。

普通方法得到的的salient map和由text-block FCN得到的salient map对比

text block FCN用到的训练图

文本线生成
MSER提取字符候选区域
在每个text block里进行MSER提取(不要求MSER把所有字符都提取出来,允许漏检和存在噪声);
利用候选区域的面积、长宽比过滤大部分噪声(仅在text block里提取,噪声不多,比较单一);
projection方法估计直线方向
在text block里找到最优的h和θ(可以确定一条直线),使得该直线穿过的component个数最多;
本方法的假设条件:第一,同一block中,所有文本线的方向一致;第二,文本线是近直线的;

候选文本线生成
对每个block里的所有component进行聚类,聚类条件如下:

每个grouping生成bounding box
沿着block(记为α)的方向θr(α)的方向画一条直线l,该直线经过这个grouping中的所有component的中心(所有component中心中随便取一个或者取中间那个?);
将直线l与α的边缘点的交点集合记为P(α是图(b)中的所有白色点的集合),即如下图中的最左边和最右边的两个红点。

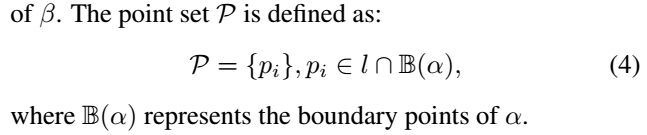
利用点集P和每个componet的bounding box生成整条文本线的bounding box(求并集)


文本线噪声过滤
character-centroid FCN获得每条文本线中的所有可能存在的字符的质心
模型结构:从text-block FCN的5层卷积→3层卷积(text-block FCN的缩小版)
训练样本:距离字符中心(ground Truth中的字符中心?)距离小于字符高度的15%的点都算作正样本点,其他点算作负样本点、


非文本线噪声过滤
质心概率的均值过滤

几何角度过滤(近直线)

创新点和贡献
贡献
用FCN生成文字/非文字的salient map;
利用局部(Component based )和全局(context of the text block ) 的信息生成文本线;
用FCN得到字符的质心;
idea的出发点
FCN既然可以作像素级的标定,那么可以用来得到每个像素属于文字的概率(salient map),也可以用来得到每个像素是字符质心的概率(centroid map );
单个字符容易受背景干扰,容易造成漏检或者误检,而文本块相对于字符不但区分性更强(更容易与背景区分开),而且更稳定(一般比较完整)。因此,如果能把单个字符的信息(局部,细节)与上下文信息(文本线)结合起来,就能使检测更加鲁棒;
实验结果
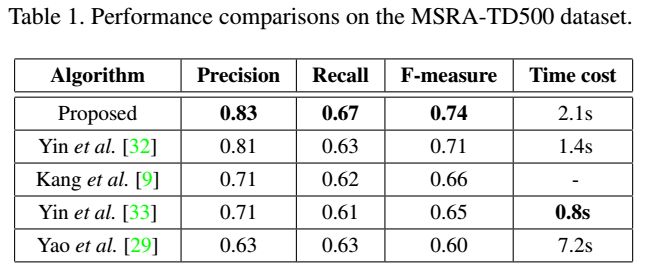
MSRA-TD500
ICDAR2015

ICDAR2013

示例图

失败的图

问题讨论
为什么FCN可以用来做文字?有什么好处?
FCN可以融合局部(字符)和全局信息(文本线);
FCN是端到端训练;
FCN由于去掉了全连接层后在像素级的标定很快,而且文字本身也容易获得像素级标定的训练数据;
为什么这篇文章的方法可以解决多方向的文字检测问题?
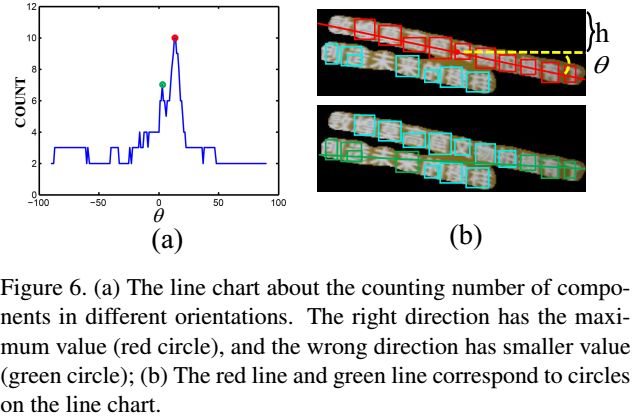
文章中决定文字方向的方法是text block(记为α)上利用MSER检测候选字符,再在整个block上找到一条直线θr(α),使得经过的候选字符个数最多。由于直线θr(α)的两个参数h和θ都没有约束限制,因此可以检测任意方向的文字;
deconv中1*1的卷积作用是什么?
1*1的卷积得到的map大小和原图是一样的,所以作用一般有三个。一是为了把多通道的信息融合起来;二是为了升维或降维(把上一层的channel数变多或者变少);三是有时候1*1的卷积是在做pixel-wise的prediction。
deconv中上采样的作用是是什么?
因为每一层卷积得到的map大小是不同的,而且和原图相比都更小,在fusion的时候要得到和原图相同大小的map所以要进行上采样。这个上采样的核(参数)在FCN中是可以学习的,初始化的时候可以选择用双线性插值;
得到的text block为什么不能直接看成是文本线,为什么还要单独一步专门做文本线生成?
第一,当多条文本线靠得比较近时,容易被一个block包含;第二,text block得到的区域范围太粗糙,并没有准确的文本位置;
文本线方向估计的这个projection的算法实际是如何操作的?(遍历h和θ?)
在文本线过滤中得到的质心图是一个概率图,如下图所示,是一团白色区域,而不是唯一的一个点,每个字符最终是由一个质心表示么?如何确定这个唯一的质心?(使用类似于meanshift,nms找到极值点?)

总结与收获点
把text block(global)和character(local)的特点综合起来,这个想法非常好,要把Faster RCNN与component的方法结合起来可以参考这篇文章的一些思想。
这是第一个用FCN来做文字的文章,虽然准确率高,但是pixel wise还是比较慢的。文字和其他目标检测不大一样,太细了。需要找其他方法来检测text block。