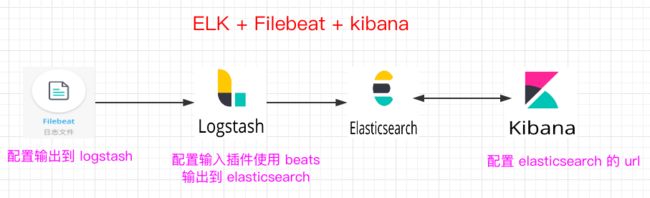
工作流程图
编写 Dockerfile
创建上下文环境
先为这个小测试创建一个目录,作为各个容器的上下文环境
mkdir elk/{filebeat,logstash,elasticsearch}
1. Filebeat
简单介绍
Filebeat 是一个轻量级的托运人,用于转发和集中日志数据。Filebeat作为代理安装在服务器上,监视您指定的日志文件或位置,收集日志事件,并将它们转发到Elasticsearch或 Logstash进行索引。
以下是 Filebeat 的工作原理:启动Filebeat时,它会启动一个或多个输入,这些输入将查找您指定的位置的日志数据。
对于Filebeat找到的每个日志,Filebeat启动一个收集器。每个收集器为新内容读取单个日志,并将新日志数据发送到 libbeat,libbeat 聚合事件并将聚合数据发送到您为 Filebeat 配置的输出。

FilebeatLogstash都是以事件为推动的和处理单位的,不是以文件中的行。
a. 准备源数据
elk/filebeat/2018.log
你可以自己准备一个日志文件,或者将上面的内容多复制1000行到文件中
b. 准备配置文件
elk/filebeat/filebeat_to_logstash.yml
filebeat.config:
modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
processors:
- add_cloud_metadata: ~
filebeat.inputs:
- type: log
paths:
- /*.log
output.logstash:
# The Logstash hosts
hosts: ["logstash:5044"]
#output.console:
# pretty: true
#output.elasticsearch:
# hosts: '${ELASTICSEARCH_HOSTS:elasticsearch:9200}'
# username: '${ELASTICSEARCH_USERNAME:}'
# password: '${ELASTICSEARCH_PASSWORD:}
2. Logstash
简单介绍
集中、转换和存储数据
Logstash 是开源的服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的“存储库”中。
下载
输入、过滤器和输出
Logstash 能够动态地采集、转换和传输数据,不受格式或复杂度的影响。利用 Grok 从非结构化数据中派生出结构,从 IP 地址解码出地理坐标,匿名化或排除敏感字段,并简化整体处理过程。
采集各种样式、大小和来源的数据 (输入)
数据往往以各种各样的形式,或分散或集中地存在于很多系统中。 Logstash 支持 各种输入选择 ,可以在同一时间从众多常用来源捕捉事件。能够以连续的流式传输方式,轻松地从您的日志、指标、Web 应用、数据存储以及各种 AWS 服务采集数据。
实时解析和转换数据 (过滤器)
数据从源传输到存储库的过程中,Logstash 过滤器能够解析各个事件,识别已命名的字段以构建结构,并将它们转换成通用格式,以便更轻松、更快速地分析和实现商业价值。
利用 Grok 从非结构化数据中派生出结构
从 IP 地址破译出地理坐标
将 PII 数据匿名化,完全排除敏感字段
-
简化整体处理,不受数据源、格式或架构的影响
我们的过滤器库丰富多样,拥有无限可能。
选择您的存储库,导出您的数据 (输出)
尽管 Elasticsearch 是我们的首选输出方向,能够为我们的搜索和分析带来无限可能,但它并非唯一选择。
Logstash 提供众多输出选择,您可以将数据发送到您要指定的地方,并且能够灵活地解锁众多下游用例。
从 Logstash 的名字就能看出,它主要负责跟日志相关的各类操作,在此之前,我们先来看看日志管理的三个境界吧
境界一
『昨夜西风凋碧树。独上高楼,望尽天涯路』,在各台服务器上用传统的 linux 工具(如 cat, tail, sed, awk, grep 等)对日志进行简单的分析和处理,基本上可以认为是命令级别的操作,成本很低,速度很快,但难以复用,也只能完成基本的操作。
境界二
『衣带渐宽终不悔,为伊消得人憔悴』,服务器多了之后,分散管理的成本变得越来越多,所以会利用 rsyslog 这样的工具,把各台机器上的日志汇总到某一台指定的服务器上,进行集中化管理。这样带来的问题是日志量剧增,小作坊式的管理基本难以满足需求。
境界三
『众里寻他千百度,蓦然回首,那人却在灯火阑珊处』,随着日志量的增大,我们从日志中获取去所需信息,并找到各类关联事件的难度会逐渐加大,这个时候,就是 Logstash 登场的时候了
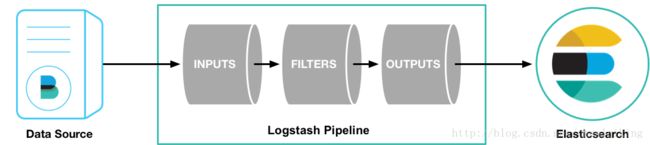
Logstash 的主要优势,一个是在支持各类插件的前提下提供统一的管道进行日志处理(就是 input-filter-output 这一套),二个是灵活且性能不错
logstash里面最基本的概念(先不管codec)
logstash收集日志基本流程:
input–>filter–>output
input:从哪里收集日志
filter:对日志进行过滤
output:输出哪里

a. 准备管道配置文件
下面的配置是监听本机的 5044 端口接收 Fielbeat 的输入
并且将处理清洗过的事件数据输出到 elasticsearch
elk/logstash/logstash_nginx.conf
input {
beats {
port => 5044
host => "0.0.0.0"
}
}
output {
elasticsearch {
hosts => ["elasticsearch:9200"]
manage_template => false
index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
}
# stdout { codec => rubydebug } # 假如有问题,可以打开此行进行调试
}
关于
output
- hosts ==>["elasticsearch:9200"] 指定机群的主机名,主机名就是容器名
- manage_template => false 禁用默认的模板,详细官方介绍
- index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
- %{[@metadata][beat]} 从源数据获取到处理日志的插件,比如
Filebeat- %{[@metadata][version]} 从源数据获取到版本号
- %{+YYYY.MM.dd} 以
Logstash的时间戳格式显示的时间
3. elasticsearch
简单介绍
Elasticsearch 是一个实时的分布式搜索和分析引擎,它可以用于全文搜索,结构化搜索以及分析。它是一个建立在全文搜索引擎 Apache Lucene基础上的搜索引擎,使用Java语言编写
主要特点
- 实时分析
- 分布式实时文件存储,并将每一个字段都编入索引
- 文档导向,所有的对象全部是文档
- 高可用性,易扩展,支持集群(Cluster)、分片和复制(Shards 和 Replicas)。见图 1 和图 2
- 接口友好,支持 JSON


a. 需要配置
生产环境下, 内核参数 vm.max_map_count 最少设置为 262144
设置方法:
编辑文件 /etc/sysctl.conf
添加一行
vm.max_map_count=262144
并执行如下 命令使之生效
sysctl -w vm.max_map_count=262144
4. kibana
简单介绍
Kibana是一款基于 Apache开源协议,使用 JavaScript语言编写,为 Elasticsearch提供分析和可视化的 Web 平台。它可以在Elasticsearch的索引中查找,交互数据,并生成各种维度的表图.
a. 默认的配置
kibana 的容器其实处于测试性的目的就可以直接运行了。
因为默认的配置文件中集群的 url 就是 http://elasticsearch:9200
下面是容器内默认的配置文件内容
/usr/share/kibana/config/kibana.yml
---
# Default Kibana configuration from kibana-docker.
server.name: kibana
server.host: "0"
elasticsearch.url: http://elasticsearch:9200
xpack.monitoring.ui.container.elasticsearch.enabled: true
整合成docker-compose.yml
注意事项:
整个集群的版本应该一致,各配置文件中对应的ip可以写成容器名
拉取官方镜像
docker pull docker.elastic.co/elasticsearch/elasticsearch:7.4.2
docker pull docker.elastic.co/beats/filebeat:7.4.2
docker pull docker.elastic.co/logstash/logstash:7.4.2
docker pull docker.elastic.co/kibana/kibana:7.4.2
elasticsearch 服务中应该加环境变量
environment:
- discovery.type=single-node
文件 docker-compose.yml 内容
version: "3.2"
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:7.4.2
container_name: elasticsearch
networks:
- elk-net
ports:
- "9200:9200"
environment:
- discovery.type=single-node
filebeat:
image: docker.elastic.co/beats/filebeat:7.4.2
container_name: filebeat
volumes:
- type: bind
source: "./filebeat/2018.log"
target: "/2018.log"
- type: bind
source: "./filebeat/filebeat.yml"
target: "/usr/share/filebeat/filebeat.yml"
networks:
- elk-net
depends_on:
- logstash
logstash:
image: docker.elastic.co/logstash/logstash:7.4.2
container_name: logstash
volumes:
- type: bind
source: "./logstash/logstash_stdout.conf"
target: "/usr/share/logstash/pipeline/logstash.conf"
networks:
- elk-net
depends_on:
- elasticsearch
kibana:
image: docker.elastic.co/kibana/kibana:7.4.2
container_name: kibana
networks:
- elk-net
ports:
- "5601:5601"
depends_on:
- elasticsearch
networks:
elk-net:
driver: bridge
启动容器
docker-compose up
使用浏览器访问宿主机的 5601 端口
比如 http://127.0.0.1:5601

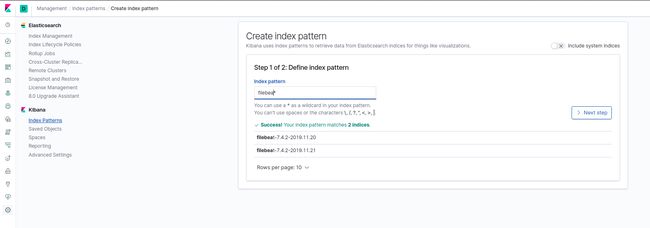
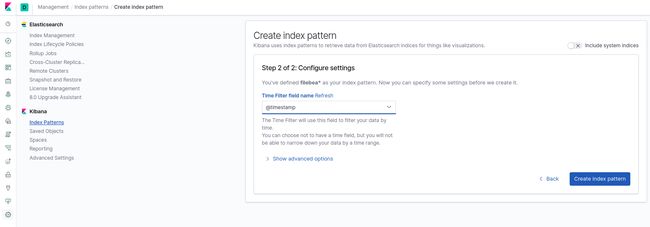
为 kibana 添加匹配索引的索引模式
要想让 kibana 识别到 elasticsearch 的数据,需要把我们在 elasticsearch 创建好的索引告诉他.
Kibana使用索引模式从Elasticsearch索引中检索可视化等内容。